윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
1001 개 검색됨 : 기술,IT 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SDXL 이 공개(2023.07.28)된지 약 6개월이 지났다. 필자는 아직 SD1.5를 주로 사용하고 있지만, SDXL 도 점점 사용회수를 늘이는 중이다. SDXL 을 사용하면서 선명도 때문에 언젠간 SD1.5 에서 SDXL 으로 전환해야 한다는 생각은 하고 있지만, SD1.5 도 6개월 전에 비해 많이 발전했기 때문에 전환할 일정은 좀 나중이 될거 같다. 아직도 에니메이션 풍의 그림은 SDXL 보다 SD1.5가 더 좋다. 아니면 최종적으로 병행해 사용하거나 말이다.

SDXL 으로 그린 그림. 선명한 그림을 그릴 수 있어 좋지만, 아직 에니풍의 화면은 무리다.
- 현재 SD WebUI 에서 SDXL 을 원활히 사용하기 위해 필요한 메모리 양은 윈도11의 경우 시스템 메모리 24GB 이상, VRAM 12GB 이상이다. CPU 는 크게 상관 없다. 듀얼코어에서도 크게 문제 없다.
- VRAM 이 8GB 인 경우에도 문제 없이 실행해볼 수 있다. --medvram-sdxl 옵션을 사용해야 한다. 시스템 메모리는 조금 많아야 한다.
- VRAM 이 4GB 인 경우에도 --lowvram 옵션을 사용해 실행할 수 있다. 해보지는 않았다.
- 반드시 nVidia 드라이버 최신 버전 사용하고, 리눅스사용할 경우 tcmalloc 반드시 사용하도록 하자.
- 스토리지가 많이 필요하다. 체크포인트만 해도 최소 6GB 이고, LoRA 파일의 용량도 SD1.5 에 비해 평균적으로 3배는 크다.
- SD1.5 에 비해 생성할 이미지의 해상도를 늘여야 하기 때문에 그만큼 느리다. 필자는 SD1.5 는 512x768, SDXL 은 832x1216 을 기본 해상도로 사용하고 있다. 그만큼 메모리 많이 먹는다.
- 필자는 현재 SD WebUI 에 "--xformers --no-half-vae" 옵션만 붙여서 사용하고 있다.
----
Stable Diffusion XL 1.0 출시
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT

RTX 4060 을 사용한 그래픽 카드중 LP(Low Profile)을 지원하는게 나왔다고 해서 한번 찾아봤다. 정말 나와있었다. Gigabyte GeForce RTX™ 4060 OC Low Profile 8G 이 바로 그거다.

일반적으로 LP 규격은 슬림 PC 에 주로 사용하고, 슬림PC는 대기업 PC에서 주로 사용되는 규격이다. 하지만 LP 는 케이스 공간이 협소하기 때문에 냉각에 문제가 있어, 발열이 많은 최신 그래픽 카드를 사용하기에는 문제가 있었다. 4060 은 TDP 가 115W 이기 때문에 보조전원까지 필요한 그래픽 카드이고 그만큼 발열이 많은 바, 따라서 LP 에서 사용하기엔 어려웠다. 보통 75W 이하인 보조전원 없는 GPU, 예를들어 xx30 이나 xx50 번대 그래픽 카드로 LP 형식에 맞춰 제조했기 때문에 xx60번대 GPU인 4060 을 LP 로 만든건 의외였다.

어쨌든 나왔고, 4060의 원래 성능과 차이가 없다고 한다. 가격대가 높지만 LP 가 필요한 시스템에서는 충분히 구입할만해 보인다.

전원부가 윗쪽이 아닌 측면에 있고, 50mm 팬 3개를 달았다. 카드 크기는 L=182 W=69 H=40 mm 이다. 그래픽 카드는 생각보다는 아담해 보인다. 구매하지는 않겠지만 재미있는 제품이다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/하드웨어 정보
벼르고 벼르다가 중고로 구매했다. DDR4 는 이제 끝물이라 구매하기 망설여지긴 하지만, 지금 내 상황에서 SDXL 을 원활히 사용하려면 메모리 증설이 필수였다. 그래서 그냥 구매. 2개에 6.5만냥에 구매했다.
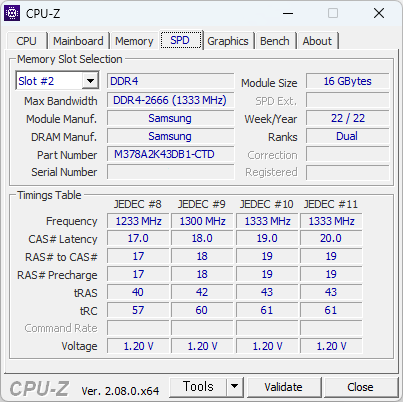
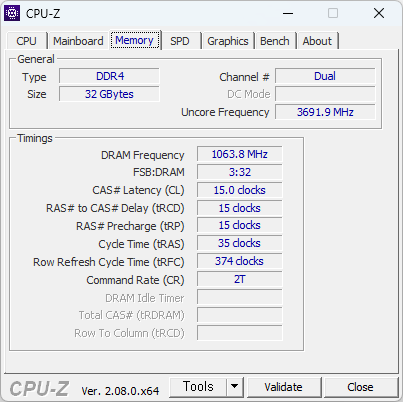
어쨋든 32GB 사용하니 좋긴 좋다. 특히 윈도11은 윈도10 에 비해 메모리를 4GB 정도 더 소요되기 때문에, 16GB 급 메모리를 사용해야하는건 어쩌면 필수일지도 모르겠다.
DDR4-2666 이긴 해도 i3-6100 CPU 가 DDR4-2133 까지만 지원하기 때문에 풀 스피드로 사용하지는 못한다. 그래도 워낙 빠르니 속도에 따른 성능 저하를 알아차리기 힘들겠지만 말이다.
----
DDR4 16G DDR4-2666V PC4-21300 x 2 추가구매
DDR4 32G DDR4-3200AA PC4-25600 x 2
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
원래 주는 프롬프트에 오타도 났고, 스케일업 설정도 평소와 다르게 들어갔지만 결과가 맘에 들어 올려본다.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
사이트 로그를 보다가 재미있는 로그가 나와서 적어본다. 정상적이지 않은 로그고 따라서 어떤걸 노렸는지 이해가 가지 않는 로그다. 발신지 IP를 조회해보니 미국으로 나왔다.
JAVA 나 JavaScript, Shell 를 사용한걸 노린거 같고, PostgreSQL 을 사용한걸 가정한듯 하다.
1. 문자열에 PG_ 으로 시작하는 쿼리처럼 생긴 문장이 있다.
2. response.write 로 시작하는 구문이 있다. Java JSP 에서 수식을 계산한건데 Integer 오버플로를 노린거 같아 보인다.
3. Shell 스크립트를 노리기도 했다. nslookup 으로 특정 도메인을 조회하려 했다.
코드 몇개는 실제로 실행해봤는데 딱히 뭔일이 발생하진 않았다. 뭐지.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
재미있는 LoRA 가 올라와서 만들어보았다. 곧있으면 신년이기도 해서, 랜턴 이미지는 준비하고 있었는데, 바이올린과 같이 만들면 어떨까 해서 만들어봤다. 예전에 라푼젤이라는 에니메이션 봤을때, 남여 주인공들이 배를 저어 호수 가운데로 가서 소망을 담은 등을 띄우는 걸 매우 감명깊게 보았었던게 기억나기도 한다. 이때문에 이맘때가 되면 윈도 바탕화면에서라도 등을 걸어두곤 한다.



아래 이미지들은 바이올린 이미지 만들다가 프롬프트 잘못줘서 나온 그림이긴 한데 꽤 맘에 들어 올려본다.


- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
밤하늘을 연상시키는 별 무늬 드레스. 역시 LoRA 가 좋은게 올라와있길래 사용했다.
드레스 안감에 별자리가 새겨져있도록 하고싶었지만 못했다. 이걸 영어로 표현하기가 쉬운게 아니다.
그래도 이정도면 매우 만족.




- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
이미지 생성시간을 획기적으로 줄일 수 있는 방법중 하나로 LCM 을 사용하는 방법이 있다. 쉽게 말하면 (필자가 AI에 대해 잘아는건 아니지만) 노이즈를 제거하는 패턴을 학습시켜서 적은 스텝으로도 노이즈를 제거할 수 있도록하는 CM (Constistency Model)을 Stable Diffusion 에 맞게 Latent 영역에서 수행하도록 하는게 LCM이다.
※ 사용 방법은 아래와 같다.
- 사용 준비
● 현재 SD 1.5 용 체크포인트와 LoRA 를 사용하고 있는 경우 아래 2가지를 작업한다.
1. https://huggingface.co/latent-consistency/lcm-lora-sdv1-5 에서 LCM LoRA 를 받는다.
2. 프롬프트에 LCM LoRA 를 추가한다.
● LCM 용 체크포인트를 사용하는 경우에는 사전 준비할것이 없다. 가장 유명한 SD 1.5 LCM 용 모델인 DreamShaper 8 LCM 을 사용해도 좋다.
- 생성하기
1. Sampler 를 "LCM" 으로 변경한다.
4. CFG Scale 을 "2" 으로 변경한다.
5. Sampling steps 을 4 ~ 16 사이의 값으로 변경한다.
6. 생성 버튼 클릭
- 사용한 예
LCM LoRA 사용

미사용

생성한 파일


- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
2023.11 에 배포된 One UI 6 에서, 불여우 안드로이드 브라우저에서 글꼴이 세리프 폰트로 (우리나라 폰트로 말하자면 명조체로) 변하는 현상이 있다. 내 블로그가 그랬다.
세리프 계열 글꼴은 예쁘긴 하지만 모니터에서 글을 오래 읽다보면 피곤해진다. 그래서 필자는 고딕글꼴을 주로 사용해 왔는데, 이번에 내가 사용하는 스마트폰 업데이트가 나와 업데이트 하니 내 블로그가 세리프 글꼴을 사용하고 있는 것이었다.
최신 삼성 갤럭시 제품에 업데이트된 "One UI 6" 부터 기존에 사용하던 한글 글꼴이 삭제되었고, "One UI Sans KR VF" 글꼴이 Fallback 글꼴(매칭되는 글꼴이 없는 경우 해당 문자를 출력하기위한 글꼴)가 되었다. 이거 사용하도록 웹의 글꼴 설정를 바꾸면 된다.
이 글꼴을 찾는데 몇일 걸렸다. 설마 여태까지 잘 쓰던 Noto CJK 폰트를 삭제할 줄은 몰랐다. ㅎㅁㅎㅁ
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
AI로 그림그리는 실력을 늘이는데 필요한 것 중 하나가 바로 잘 그린 그림을 따라해보는 거라고 생각한다. CivitAI 에서 그림 감상중에 한 그림이 맘에 들어 따라해 보았다. 아래 이미지가 바로 그것.

프롬프트는 CivitAI 의 샘플 이미지와 같다. 재현은 잘 되었다. CivitAI 에 있는 그림과 거의 동일하다고 생각하기 때문이다. 사소한 디테일은 장비차이 때문이라고 치자. 내 방법대로 그리면 이런 그림은 안 나오기 때문에 조금 아쉽다. 위 그림을 생성하려면 반드시 xxmix9realistic_v40 체크포인트를 사용해야 하고, wrenchfaeflare LoRA 를 사용하면 쉽게 생성할 수 있다.
요즘의 SD 용 체크포인트는 적은 프롬프트를 사용해도 풍성하고 디테일 있는 그림을 얻을 수 있도록 튜닝되곤 한다. 이 그림도 마찬가지.
내 방법대로 그린 그림은 아래에 있다. 빛나는 이펙트가 많이 살아있지 않아서 아쉽지만 그럭저럭 봐줄만 하다.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음