케이팝 데몬 헌터스(KPop Demon Hunters)라는 에니메이션이 인기를 끌고 있다. 넷플릭스에서 지원해서 소니에서 만든 케이팝을 소재로한 에니메이션이다. 케이팝 걸그룹이 데몬을 물리치는 단순한 이야기이지만, 그 속에 들어있는 한국적인 문화에 세계적인 인기를 얻고 있다.
이 글에서는 한류를 이야기하고자 하는건 아니고, 그 작품에 한복이 안 나온게 조금 아쉽다. 서울이 배경이고 특히 서울타워가 자주 나오는데, 그 근처인 경복궁이 나오지 않았고, 한국 또는 한류를 어필하는 작품이었으면 한복은 나왔으면 해서 말이다. 처음에 무당옷이 나오는것에 대해서는 긍정적으로 평가하지만 말이다.
주인공 3인방 중 한명인 조이(Zoey)가 맘에 들어서 비슷하게(?) 내 방식대로 생성했다. 원래는 금발로 하려 했지만 막상 해놓고 보니 그건 좀 아닌거 같아서 흑발로 했다.
십여년전에 이미 에이즈(AIDS, Acquired Immune Deficiency Syndrome, 후천성면역결핍증) 는 불치가 아니라 난치병이다라는 이야기를 했었습니다. 어렸을 때 뉴스에서 떠들던 "불치의 병 에이즈"이라는 게 각인되어있던 저에게는 꽤 큰 의미로 다가왔습니다. 십여년전에도 이미 치료제가 많이 있었고, 칵테일 요법이라 해서, 여러가지 에이즈약을 섞어 처방하면 나을 수 있었죠. 그 당시에도 이미 에이즈는 불치병이 아니라 낫기 어렵지만 나을 수 있는 난치병이었죠. 그리고 그 이후에도 계속 치료제가 개발되었고 현재는 그냥 나을 수는 있는 병입니다. (부작용이 제법 있고 치료비용도 많이 들긴 하지만요)
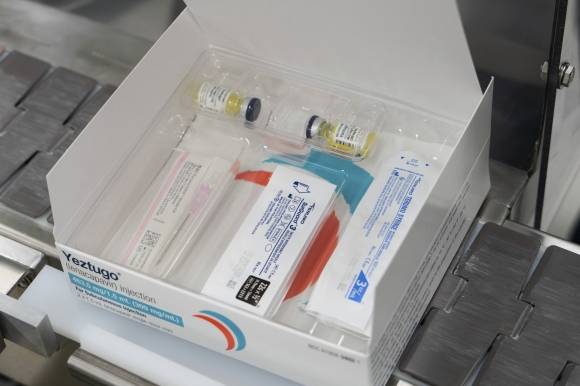
그리고 올해 6월 18일 미국 FDA 가 길리어드사의 예즈투고(Yeztugo, 성분명 Lenacapavir)를 승인했습니다. 에이즈에 대해 '노출 전 예방 요법(PrEP)'을 위한 약입니다. 6개월에 1번 주사하면 100% 예방된다고 하네요. "치료제" 가 아니라 "예방약"입니다. 가격이 비싸긴 하지만(5000만원/회 으로 예상된다고 하네요), 아프리카 등지에서의 AIDS 발병율은 상당한 수준이라 이런 약이 나왔다는건 반가운 일입니다.
인류가 예방약을 만들어 없앤 질병중 하나가 소아마비입니다. 예전엔 예방주사 맞았다고 요즘엔 안 맞는 주사죠. 거의 없어졌다고 하는데요. 이 약이 널리 보급되면 에이즈도 그 뒤를 따르려나요. 인류의 크나큰 쾌거입니다.
저는 이런 바이러스 예방약이 나오게 된 계기가 바로 코로나19 때문이라고 생각합니다. 그 전까지는 바이러스에 대해 연구를 잘 안하다가 코로나 이후부터는 연구가 활발해졌고 때마침 AI 가 발달되어있어서 그 연구가 가속화 되었죠.