윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
2464 개 검색됨 : 분류 전체보기 에 대한 결과
- 글쓴시간
- 분류 기술,IT/하드웨어 정보
예전에 32GB 메모리를 구매한 이후 H110 마더보드에서 32GB 메모리 모듈이 인식될지, 총 64GB 메모리를 사용할 수 있을지 궁금해지긴 했다. 그리고 될것 같았다. 하지만 예전에 구매했던 H110M-K 2개는 지금은 내가 사용하지 않기 때문에 확인을 할 수 없었다.
우연히 H110M-K 를 하나 더 구했다. 원래 이 블로그의 서버를 바꿀 생각으로 mATX 마더보드 저렴한걸로 구매할 생각을 하고 있었는데 마침 이 물건이 나왔다. H110M-K 마더보드에 좋은 기억이있기 때문에 주저하지 않고 구매했다. 마더보드와 i3-6100 CPU를 포함해 1만냥에 당근에서 구매했다. 이정도면 저렴하게 잘 구매한거 같다. 테스트해 본 결과 보드와 CPU 에 이상 없다.
일단 64GB 메모리는 H110M-K 마더보드의 공식 스펙으로는 지원되지 않는다. 스펙에는 지원되는 메모리가 최대 32GB 까지라고 적혀있다.

ASUS H110M-K 의 메모리 스펙. 최대 32GB 까지 지원한다.
하지만, 마더보드에 최신 바이오스 (4401 버전)를 사용하고, 32GB 메모리를 2개를 설치하면 아래와 같이 제대로 인식되고 사용할 수 있다.
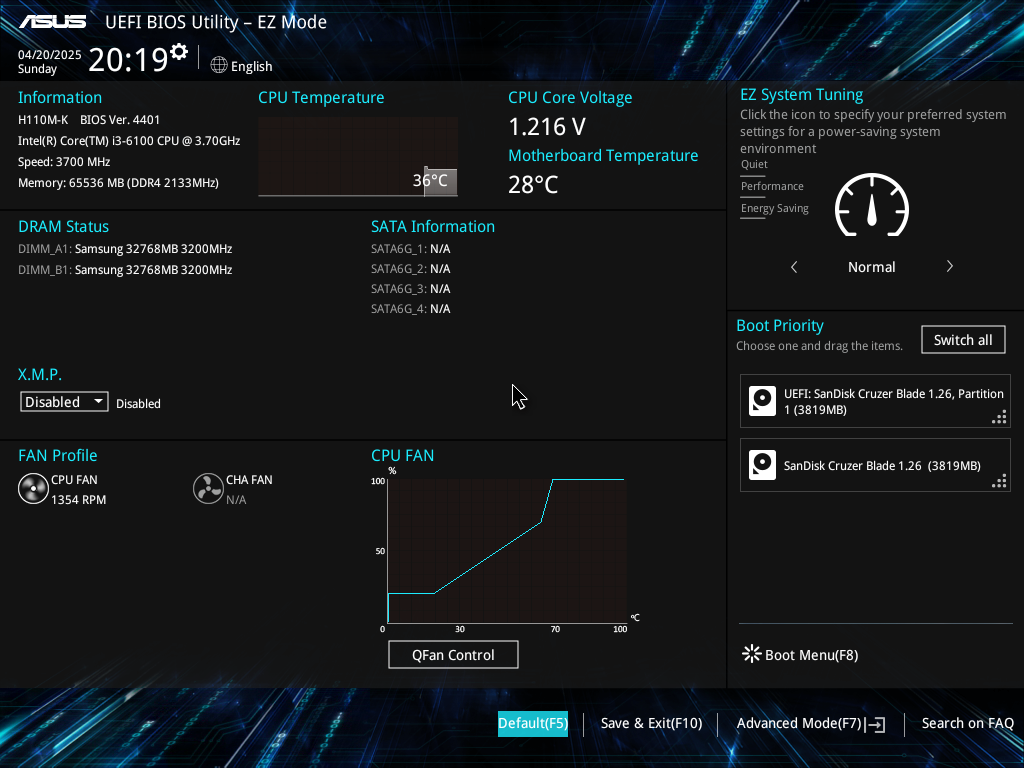
H110M-K + 64GB Memory (32GB x 2)
스카이레이크 PC중 스펙이 낮은 H110 + i3-6100 조합에서도 64GB 메모리를 사용할 수 있으니, 그 상위 제품들도 32GB 모듈 2개, 64GB 를 사용할 수 있을 것이라 생각한다.
인터넷에서 "Skylake/Kabylake 128GB Memory Support" 또는 "Skylake/Kabylake 32GB Memory Module Support" 쳐보면 "No" 라고 답변한 글이 최근에도 제법 있는데, 이렇게 "Yes"라고 이야기 하고 싶은거다.
----
Skylake / Kabylake 에서 32GB 메모리 모듈 및 128GB 메모리 사용하기
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 자동차
아방이 뒷 브레이크 패드를 교환했다. 보통 50000 KM 마다 교환한다. 이번이 두번째다.
브레이크 패드 교환은 블루핸즈에서 하는것 보다 근처 카센타 가서 교환하는게 더 저렴하다. 많이 저렴하다.

우선 인터넷으로 차량에 맞는 패드를 구매. "뉴아반떼 XD 1.6 (ABS) 용 브레이크 패드 뒤 라이닝"로 상신 브레이크의 부품번호는 SP1062 이다. 상신브레이크 패드 중에서 가장 저렴한걸로 골랐다. Hi-Q 브랜드 말하는거다. 가격은 1.1만냥. 1세트에 4개 들어있다. 배송받아보면 생각보다 작았다. 손바닥 만하다고나 할까. 참고로 앞바퀴용 브레이크 패드의 부품번호는 SP1152 다.
카센타에 가서 교환. 근처 자주가던 카센타가 문을 닫는 바람에 멀리 갔다. 공임은 3만냥이라고 했다. 친절하고 잘 해주셨다. 시간은 20분 정도 걸렸다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
최근에 나온 AGESA 1.2.0.E 에는 Microcode Signature Verification Vulnerability 보안 취약점이 해결되었다고 합니다. AMD CPU ROM 로더에 시그니처 검사하는 부분을 바꿨나 봅니다. 예전에 SMM(System Management Mode) 관련한 보안 취약점이 있었는데 그것과 비슷해보이기도 하네요.

보안 취약점은 구글에서 발견했습니다. 중요한 패치는 아니지만, 어쨌든 새로운 바이오스 버전이 나왔으니 업그레이드 해놓는게 좋겠네요. 사용하고 있는 PRIME B550M-A 은 바이오스 버전이 3611 에서 3621 으로 업그레이드 되었습니다.
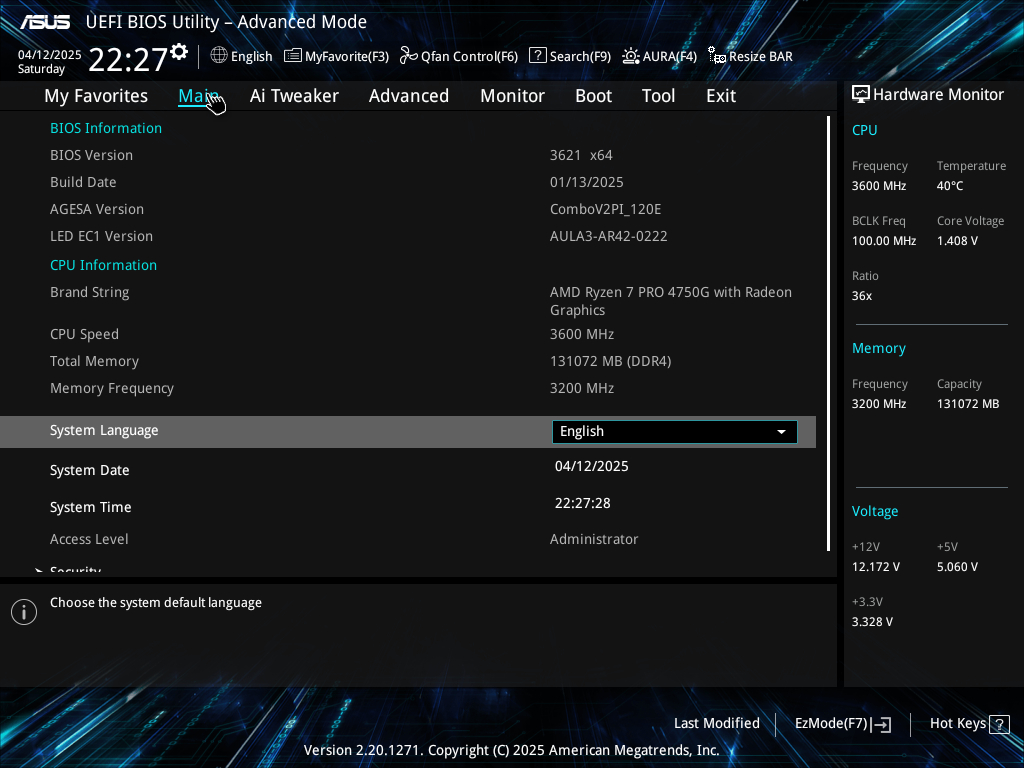
AGESA 도 ComboV2PI 1.2.0.Cc 에서 ComboV2 PI 1.2.0.E 으로 업그레이드 되었네요.
참고로 AGESA 1.2.0.D 버전도 있었습니다. SMM 보안 취약점을 고친건데, 결국 E 버전에서 다른 부분이 함께 고쳐진거 같네요. SMM 부분은 1.2.0.Cb 버전의 수정 내역부터 계속 언급되는데 이부분에 원래 문제가 제법 있었나봅니다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
2024.08 에 32GB 2개를 구매한적이 있었는데, 다시 4개 더 구매했다. 당근에서 중고로 구매했고 개당 5.5 만냥이다. 아마 DDR4 는 이걸 구매하는걸로 마지막일듯 하다. DDR5 떨어질때까지 기다려서 그걸로 시스템 업그레이드나 해야할듯. 올해는 아니고 빨라야 내년 이야기다.
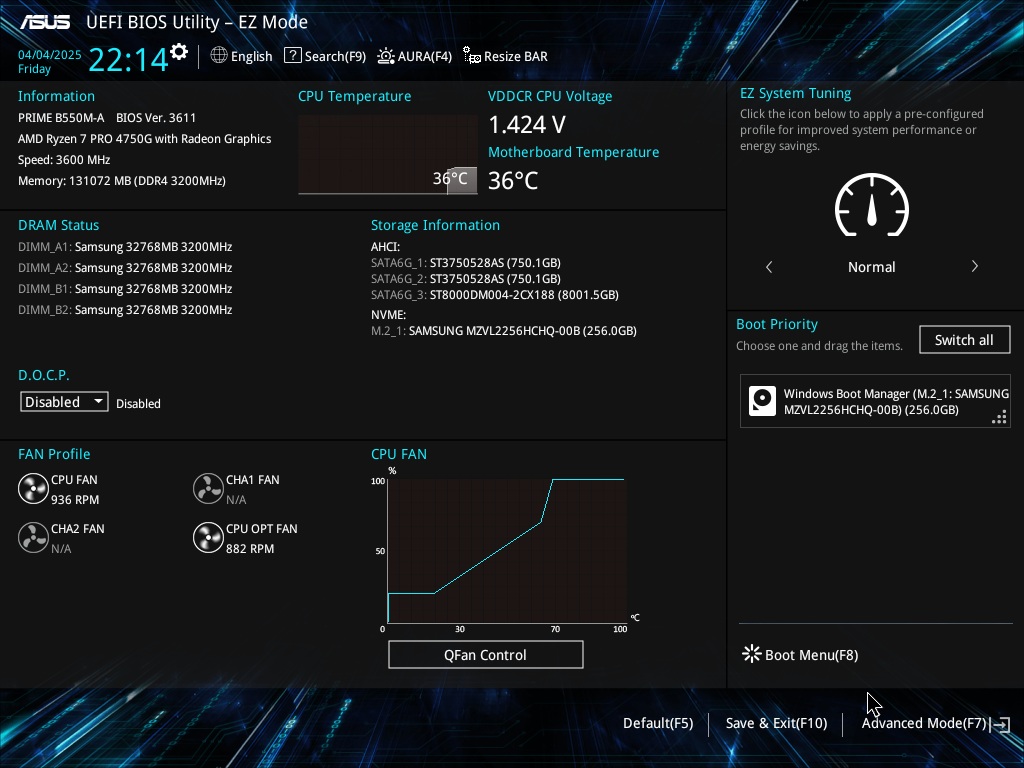
드디어 128GB 풀 뱅크로 채워봤다.
파트넘버는 M378A4G43AB2-CWE 으로 지난번 구매한것과 동일하다. A 다이를 사용한 제품이다. 주차만 이번에 구매한게 조금 빠른 21년 05주차다. 기존건 08 주차였다.
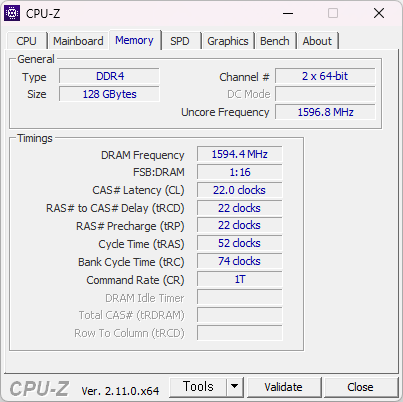
주 PC에 달아주려고 구매했다. 잘 인식되었고, 메모리 테스트 결과 이상 없다. DDR4 로도 최대 메모리를 찍었으니 DDR5 으로 넘어가야 할 때가 온거 같기도 하다.
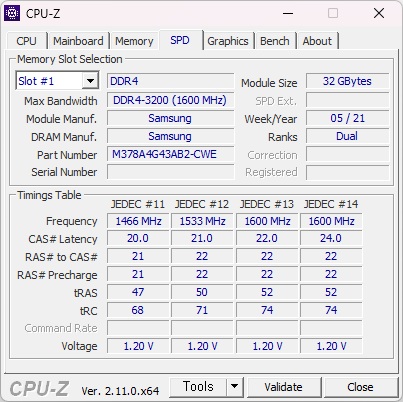
메모리 오버 테스트는 안해봤다. 어차피 풀 뱅크라서 오버는 포기다. 3600MHz 오버도 안될듯.
기존에 사용하던 32GB 메모리 두개는 세컨 PC에 달아주었다. ASUS PRIME H270-PLUS 의 32GB 메모리 모듈 지원 을 읽어보자.
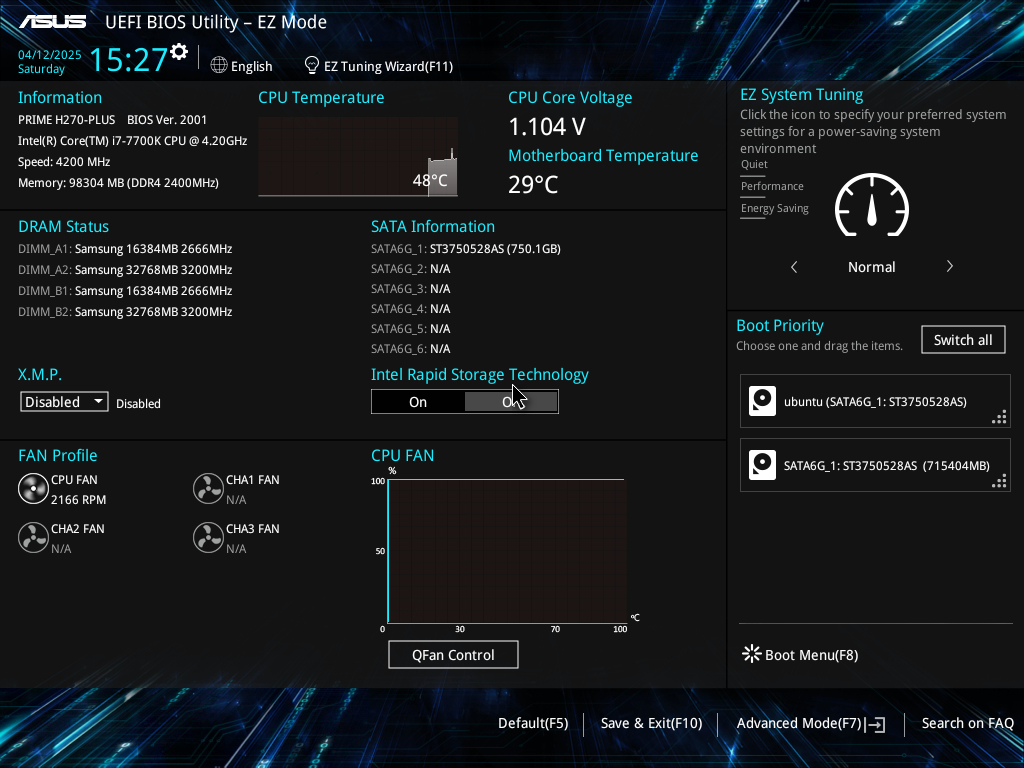
구매하고 나서 같은 스펙의 메모리 신품 최저가를 검색해보니 10만원으로 나온다. 메모리 가격이 오를꺼란 기대감이 있다고 하는데, 글쎄다. DDR4 가 언제까지 쓰일지는 미지수다. 물론 아직까지는 DDR4 가 주요 제품이 속해있긴 하다. 30만원대 PC를 구성하기에도 가장 좋다. DDR5 가격이 32GB 모듈기준 현재 14만원 정도 하는데 이 가격도 서서히 오르긴 하고 있다. 찾아보니 DDR5 64GB 모듈도 마이크론에서 나온거 같다. 어차피 DDR5 는 CUDIMM 으로 바뀌는 중이라 나중에 이걸 구매할꺼기도 하다. 이런 상태라면 128GB 모듈 나올때 쯤 구매할거 같긴 하다.
----
2025.10.26 업데이트
이 글 쓸때까지만 해도 DDR4 단종이라 가격 떨어질껄로 예상했지만, 현실은 어마어마하게 오르고 있다. 앞으로도 더 오를꺼라고 한다.
DDR4 메모리 가격 상승
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
Wan 2.1 는 중국의 알리바바그룹의 통이 연구소에서 개발한 시각모델이다. 주로 동영상을 생성하는 AI 으로 잘 알려져 있고 오픈소스로 공개되어있기 때문에 현재는 매우 핫해졌다.
나온지는 꽤 되었지만 이제서야 돌려 보았다. 내 PC 사양에서 720p 동영상은 무리지만, 480p 영상은 생성 가능할것으로 생각된다. 조금 기다리긴 해야 하지만 말이다. RTX 2060 12G 에서 아래 영상 생성하는데 약 30 분 걸렸다. GPU 온도가 60도 미만인것으로 보아 VRAM 이 매우 부족해 보인다. 뭔가 튜닝을 해야할 듯.
파라메터가 14B 와 1.3B 모델이 있는데, RTX 2060 12G 에서 14B 모델을 그대로는 못 돌린다. 너무 느리다. 양자화한걸로 실행하긴 했는데 성능은 다행이도 그대로인거 같다. 샘플 만큼의 영상이 나온다.
잠재영역(Latent)을 사용하는건 SD와 같은데, 이를 동영상 생성에 맞게 튜닝했다. 그래서인지 굉장히 빠르다.
사용하려면 반드시 ComfyUI 를 사용해야 한다. 최신버전을 설치하고, 모델 4개를 받아 지정된 곳에 넣어주면 준비는 끝. 비디오 메모리가 12G 이기 때문에 조금 많이 기다리긴 해야 하지만 어쨌든 생성은 된다.
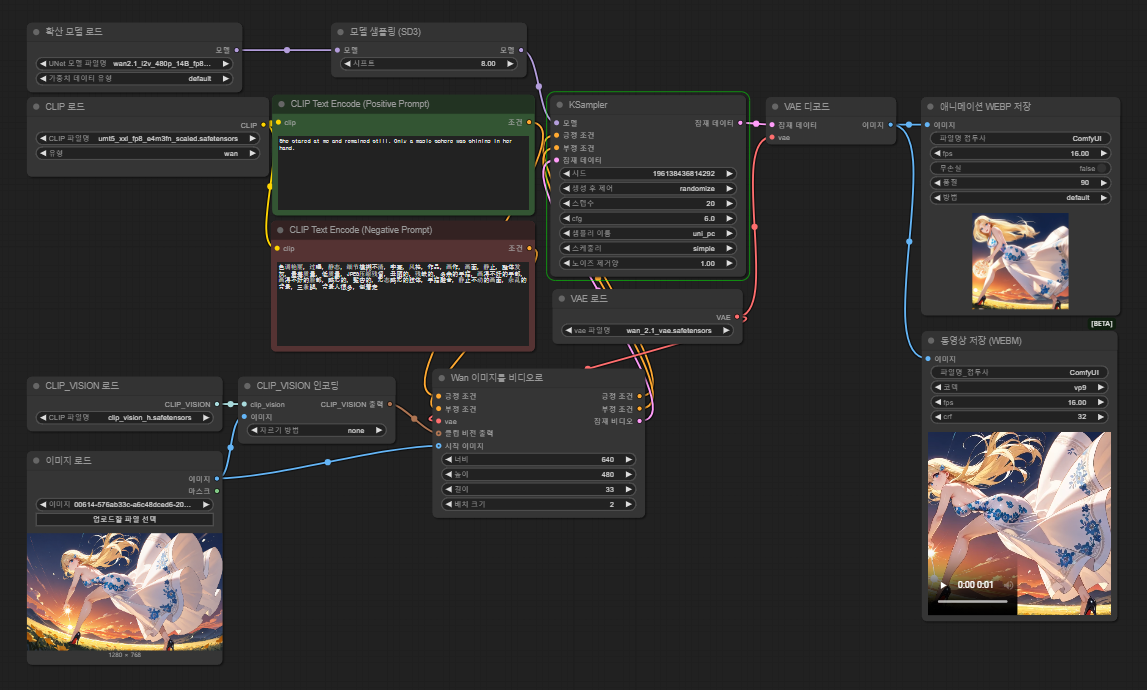
사용 방법은 Wan2.1 ComfyUI Workflow 에 잘 설명되어있으니 생략.
처음 치고는 잘 만들었다고 자찬중이다. (이후에도 몇개 더 만들었긴 하지만, 모두 이것보다는 잘 안나왔다) 어쨌든 동영상 생성시에도 좋은 이미지가 필요하다는건 알게 되었다.
----
2025.08.01 추가
Wan 2.2 가 나왔다. 2.1가 비슷하긴 한데, 좀 더 부드럽고 그럴듯하게 생성해준다. 당연히 써야 한다.
https://github.com/Wan-Video/Wan2.2
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
Intel® Pentium® G4560 - PCIe 인식 오류
오래전에 공짜로 받은 CPU 하나가 PCIe x16 기기 인식에 오류가 있다고 했었다. ( Intel® Pentium® G4560 - CPU-Z ) 이에대해 정리해 놓으려 한다. 찾아보면 G4560이 인식 안된다는 글을 몇개 더 볼 수 있는데 필자의 경우 CPU는 인식되지만, PEG 에 연결된 기기가 인식이 안되는 현상이다. 워낙 인기 있었던 CPU 이기 때문에, 많이 팔렸으니 그만큼 불량도 많이 보고되는 것 같다. 2017년 초에는 7.5 만원짜리 CPU가 2코어/4쓰레드라면, 그냥 이거 구매하라는 의미였다. 인텔의 실수이니 마구마구 구매했었다. 그런 CPU가 지금은 중고로 7000원에 거래된다. 워낙 많이 팔려서 그만큼 중고 물량도 많다.
G4560 을 장착한 PC의 PCIe x16 에 아무것도 끼워있지 않으면 BIOS 에 PEG(PCI(Peripheral Component Interconnect) Express Graphics) 포트가 Not Present 으로 나온다.
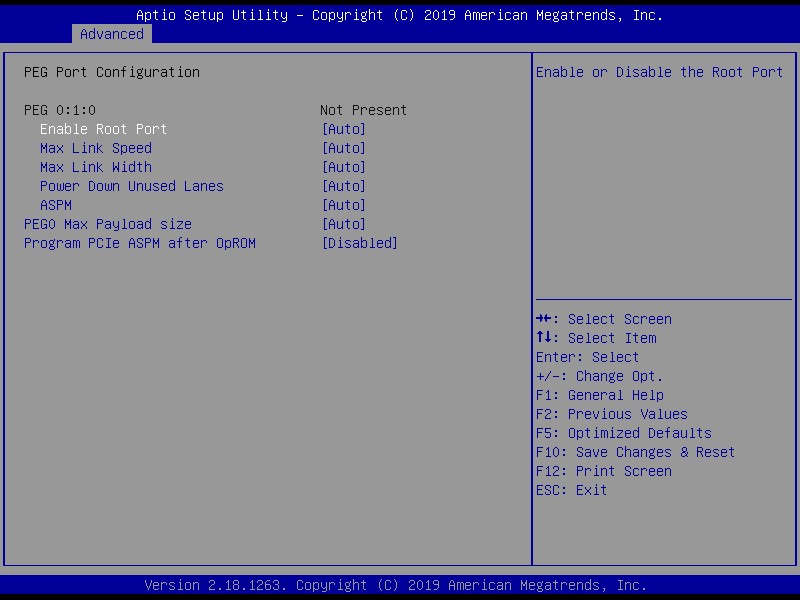
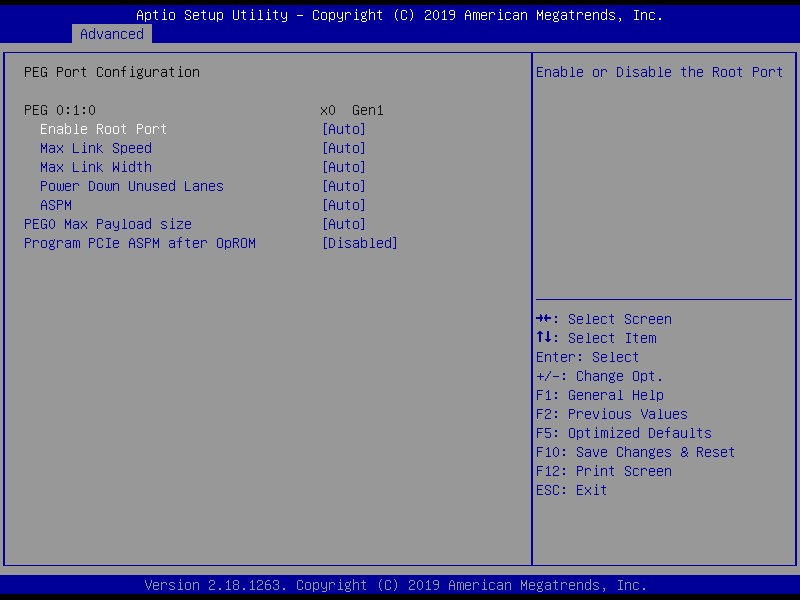
이 포트가 고장난 경우 외부 GPU 를 연결하면 아래와 같이 "x0 Gen1"으로나왔다. 이렇게 나오면 안되고 "x16 Gen1" 이와 비슷하게 나와야 한다. "x0" 은 PEG 슬롯에 삽입된게 감지되긴 했는데 통신이 안된다는 의미다.
고장난 CPU의 뒷면을 찍어보았다.

어디가 잘못되어있는지 보이는가? 아래 사진을 다시 보자. 육안으로는 4곳의 연결 부위가 잘못된거 같다. (사진상으로 보는것과 실물을 보는게 다르다. 사진상으로는 핀의 접점부위가 고장난게 잘 안보이는데 실제로 보면 잘 보인다) 4곳 외에도 PEG 의 Tx 를 담당하는 부분이 고장나는 바람에 PCIe 기기와 통신이 안되는 것으로 생각된다.

LGA 1151 v1의 핀아웃이다. 오른편 하단의 초록색으로 된 PEG 포트에 해당되는 핀이 나간게 맞는듯.

LGA1151 v1 핀아웃
참고로 LGA1151 v2 와 v1 은 핀아웃이 유사하다. v2 는 v1에서 RSVD 부분에서 전력을 공급하는 핀이 추가되어있다. 새로 추가된 전력 공급 핀은 8, 9세대 의 i5 급 이상되는 CPU에서만 사용했기 때문에 i3 급 CPU는 완전하게 호환되었다. 그래서 커피타임과 같은 바이오스 개조 마더보드가 나올 수 있었다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
마더보드의 팬 커넥터에 대해 정리해 보았다.
- 기본적으로 마더보드의 팬 커넥터는 3핀 또는 4핀 규격이며, 3핀은 전압 조절방식, 4핀은 PWM 방식으로 팬의 속도를 조절한다. 특별한 언급이 없는 한 12V 를 사용하며, 최대 1A 까지 전력을 공급한다. 아주 오래전엔 2핀도 있었지만 지금은 없다.
- PC에서 사용하는 팬은 모두 브러시리스 팬이다. 팬에 작은 칩이 내장되어 있으며, 이 칩에서 팬을 제어한다. 브러시가 없기 때문에 수명도 길고 조용한 대신 비싸다. 브러시리스 팬에 대해서는 언젠가 다룰 생각이다.
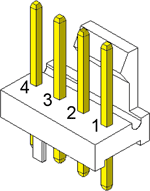
마더보드 4핀 커넥터. 인텔이 정한 규격이다.
- 핀 규격은 아래와 같다.
핀# 설명 색상1 색상2 --- ------- ----- ---- 1 GND 검정 검정 2 +12VDC 노랑 빨강 3 Sense 초록 노랑 4 Control 파랑 파랑
1번과 2번 핀이 연결되면 팬이 작동한다. 12V 가 인가되기 때문에 팬이 최대 속도로 회전하며, 그 이하의 전압이 인가되면 회전수가 낮아진다.
3번핀은 팬의 속도를 모니터링하기 위한 핀이다. Open Collector, Open Drain 방식의 신호다. 연결되지 않아도 팬은 돌아간다.
4번핀은 팬 속도 정밀 제어를 위해 PWM 신호를 전달하기 위한 핀이다. 5V, 5mA, 25kHz 의 신호다. (오차는 있다) 연결되지 않아도 팬은 돌아간다.
커넥터에는 핀 번호를 맞추기 위한 지지대가 있고, 이 때문에 거꾸로는 연결되지 않는다. 안심하고 끼우자. 어차피 1, 2번 핀만 맞춰서 연결하면 팬을 사용할 수 있다.
4번핀이 있다고 모두 PWM 제어를 하는건 아니다. 마더보드 매뉴얼에 PWM 으로 나와있어야 PWM 제어를 한다. 4번핀으로 5V VCC 를 흘려주어 PWM 신호에 의해 최대 속도로 작동하고, 이 상태에서 전압으로 팬 속도를 조절하는 마더보드가 간혹 있다.
- 팬 핀에 따른 케이블 색상은 제각각이다. 1 번 그라운드는 중요한 핀이기 때문에 공통적으로 검은색이다.
3핀의 경우 검정-빨강-노랑 이 많기 때문에, 색상2를 더 자주보는것 같기도 하다. 인텔 번들 쿨러는 색상1로 많이 나온다.
- 시스템 전원을 켜자 마자 CPU 팬이 빨리 도는걸 볼 수 있는데, 순간적(몇초)으로 12.6V - 2.2A 까지 허용해 빨리 RPM 을 높일 수 있도록 하기 위함이다.
- 마더보드의 4핀 팬 커넥터에 3핀 팬을 끼워도 되며, 반대로 마더보드의 3핀 팬 커넥터에 4핀 팬을 끼워도 된다. 단 이렇게 하면 팬 속도제어가 되지않는 것이 기본이다. 하지만 마더보드가 이렇게 연결하고도 팬 속도를 조절할 수 있도록 제공하는 경우가 많다. 따라서 설명서를 확인해보자. 예를 들어 마더보드 4핀 커넥터에 3핀 팬을 연결하고, 마더보드에서 팬 속도제어를 전압으로 설정하면 팬 속도가 제어된다.
- PWM 방식의 팬 제어는 팬의 회전수를 더 정교하게 제어할 수 있다. (하지만 팬의 회전수를 정교하게 제어할 필요가 있는지는 생각해보자. 1000 RPM 과 1010 RPM 은 팬 회전수 센서의 오차 범위 이내고, 실제로도 차이가 없다)
- 마더보드에있는 팬 커넥터에는 이름이 있다. 이름에 관계없이 팬 커넥터 규격은 동일하기 때문에 팬을 아무데나 연결해도 되긴 하지만, 마더보드 제조사에서 커넥터에 특성을 부여하는 경우가 있다. 이에 대해 설명한다.
1. CPU-FAN, CPU-OPT, CPU-FAN2
CPU 를 식혀주는 팬을 연결하는 커넥터라는 의미다. 마더보드 제조사에서, 이 포트에 끼우는건 CPU 의 열을 식히는 팬이라고 생각하고 제조한다. 따라서 이 팬 포트는 마더보드에서 CPU의 온도를 모니터링해 팬 속도를 제어할 수 있도록 설계되어있다. 보통 1A 까지는 출력해준다. 몇몇 마더보드에서는 이 포트에 연결된 팬의 RPM 이 0 인경우, 알람이나 비프음을 띄우거나 아예 부팅을 하지 않는 기능을 제공하기도 한다. CPU-OPT는 CPU Optional 이라는 의미로, 역시 CPU 에 연동된 팬이란 의미다. 최근 나오는 타워형 CPU 쿨러에는 2개 이상의 팬을 요구하는 경우가 있기 때문에 CPU-OPT 가 생겨났다. CPU-FAN2 도 CPU-OPT 와 마찬가지다.
2. SYS-FAN, CHA-FAN
System Fan, Chasis Fan.
마더보드 제조회사마다 부르는 명칭이 다를 뿐 같은 포트다. 보통 마더보드에 달린 온도센서와 연동되어 팬의 속도를 제어해주는 기능을 가지고 있다. 즉 이 커넥터에 연결된 팬은 시스템 온도계와 연동되어있어, 시스템 온도가 오르면 이 커넥터에 연결된 팬의 속도를 높이는 기능을 가지고 있다. CPU 온도와 연동시키는 기능을 가진 마더보드도 있다.
3. AIO-PUMP, W_PUMP
All In One Pump, Water Pump.
수냉 쿨러의 수중 모터에 연결하기 위한 팬 커넥터다. 수냉 쿨러의 수중 모터는 물을 순환시키기위해 작동하는 것으로, 상시 최대 속도로 작동해야 하기 때문에 이 커넥터들은 속도 제어가 되지 않는 경우가 많다.
또한 보통 마더보드 팬 커넥터는 12V-1A 규격으로 최대 12W 까지 출력할 수 있지만, 수중 모터는 간혹 이 규격을 넘어서는 경우도 있다. 이런 규격을 만족하기 위해 만든 팬 커넥터이기도 하다. 보통 12V-2A 규격이다. 장착하려하는 수냉쿨러 매뉴얼에 2A 이상의 포트에 연결하라고 되어있는 경우 반드시 이 포트에 연결해야 한다. 이렇게 이야기하긴 했지만, 12V-2A 가 필요한 수냉 쿨러를 보기 힘들다. 필자가 가지고 있는 3열 수냉 쿨러의 워터 펌프도 12V-0.36A 으로 1A 초과해 사용하는 수랭쿨러가 거의 없다.
이 포트가 없으면 그냥 4핀 몰렉스 커넥터를 3핀 팬 연결할 수 있는 단자로 변환해주는 어댑터를 구매해서 사용하면 된다. (아마 수냉쿨러 패키지에 들어있을 것이다) 없다면 구매하자. 1000원 정도 한다.
4. PUMP-FAN
수냉 쿨러의 라디에이터에 달려있는 팬에 연결하기 위한 포트다.
대부분의 마더보드에 이렇게 이름 지어진 커넥터가 없다. 그냥 CHA-FAN 에 연결하고 CPU 온도에 연동해 팬의 속도를 제어하게 해주면 된다.
5. PWR-FAN
Power Supply Fan.
파워 서플라이의 팬 회전수 모니터링 용 포트. 2015년만 해도 이 포트를 지원해주는 파워 서플라이가 있었는데 요즘엔 없으며, 요즘의 마더보드에서도 이런 이름을 가진 포트가 없다. (필자가 가지고 있는 ASUS P5K 마더보드에 이런 이름을 가진 포트가 있고, 오래전에 시소닉에서 나온 파워 서플라이에 팬 RPM 모니터링용 커넥터가 있었다)
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/하드웨어 정보

ASUS P10S-V/4L

ASUS P10S-V/4L
출시가격은 24만원 정도. 구형 PCI 슬롯이 있는 제품이지만, C236 칩셋이기 때문에 가격은 비쌌다. 그래도 같은 C236 칩셋을 사용한 워크스테이션용 보드인 P10S-M WS 이 28 만원, P10S WS 이 34 만원 인걸 감안하면 꽤 저렴하게 나온 셈이다.
Sky Lake 와 Kaby Lake 프로세서 외에 XEON E3 12XX V5, V6 CPU 를 사용할 수 있다. (마더보드의 CPU 호환리스트에는 i5-6500, i7-7700 과 같은 i5 이상의 CPU 가 나와있지 않는데, 사용할 수 있다. 필자가 i7-7700K 이 작동하는걸 확인했다) 또한 XEON CPU를 사용하는 경우, ECC 메모리를 사용할 수 있다.
SATA 슬롯이 8개고 SATA-DOM 도 지원된다.
서버용 마더보드답게 ASPEED 사의 VGA 칩셋(AST1400)이 내장되어있다. (이 칩셋은 서버용 초 저 전력 VGA 칩셋이다. 콘솔용이다) 또한 시리얼 포트를 사용한 콘솔을 지원한다. 오디오 기능은 없다. 랙마운트 서버에 사용할 때, 바람이 원활히 불도록 CPU 소켓, 전원 커넥터, 메모리 위치가 변경되어있다.
캐패시터 색상이 금색이다. 뭔가 멋쩌 보인다. 65도에서 136.9년이라는 수명이라고 한다. 초크 모양도 맘에 든다. CPU 전원부는 4 Phase 으로 고효율 전원부라 발열이 적다.

ASUS P10S-V/4L 후면패널
무엇보다 압도적인건 BIOS 들어가보고 놀랬다. 설정할 수 있는게 굉장히 많다. 어쨌든 C236 칩셋이라 풀 스펙이긴 하니 말이다.
Z270 보드 사려고 당근 기웃거리다가 마침 싸게 있길래 재미삼아 구매했다. 1 만냥에 구매했다. 이 마더보드는 현재 3만냥 정도에 판매되고 있다. 다행이 잘 작동한다. 메모리 슬롯 정상, PCIe x16 포트 정상, PCI 슬롯 정상이다.
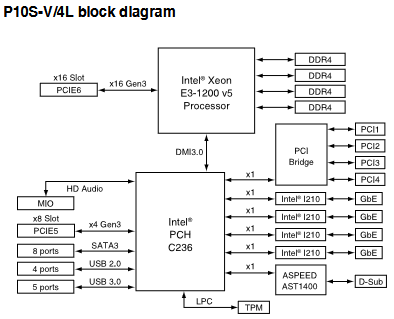
ASUS P10S-V/4L 의 블록 다이어그램
이제 XEON CPU 를 사야 하남. 문제는 E3 계열 XEON CPU중에서 V5, V6 는 잘 안팔렸기 때문에 구할 수 있을지 모르겠다. (E3 CPU 는 C2XX 보드에서만 사용 가능했기 때문에 많이 안 팔렸다) 그냥 i5-7500 정도 선에서 하나 구할 생각도 하고 있다.

ASUS MIO AUDIO 892
마더보드에 보이는 PCIe x1 처럼 생긴 포트는 실제로는 MIO 포트다. PCIe 방식으로 통신하는게 아니기 때문에, PCIe 장치를 끼워도 인식되지 않는다. 블록 다이어그램에도 HD Audio 으로 연결한다고 되어있다. 문제는 MIO 포트에 맞는 오디오 카드가 현재 중고로 100달러가 넘는다. 서버 액세사리이기 때문. 에혀. 출시가격은 30달러정도였다. 중고로 100달러라면 그냥 좋은 USB 오디오를 하나 사서 사용하는게 좋다. 이 마더보드가 인기가 없는 이유 중 하나다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SDXL 은 다양한 해상도를 가진 이미지로 학습되어있는데, 이 해상도의 기준이 1024 x 1024 이다. 또한 내부적으로 64px 의 디멘션을 사용하기 때문에, 해상도는 64의 배수가 되어야 한다.
SDXL 이미지 학습 해상도인 1024 x 1024 으로 생성하는것이 가장 좋고, 512 ~ 1536 사이의 값으로 64 의 배수값으로 생성할 수 있다. 전체 픽셀수는 1.04M (1,090,519) 을 넘어서는 안된다.
결과적으로 이미지는 아래 해상도로 생성하면 된다.
해상도 픽셀수 비율
---------- --------- -------------
1344 x 768 1,032,192 1.75:1 16:9
1216 x 832 1,011,712 1.46:1 3:2
1152 x 896 1,032,192 1.28:1 4:3
1024 x 1024 1,048,576 1.00:1 1:1
1536 x 640 983,040 2.40:1 2.39:1
가로/세로를 바꿔서 생성해도 된다. 비율은 16:9 비율이 약 1.77:1 비율임을 생각하면 된다. 참고로 2.39:1 은 시네마스코프 비율이다.
필자의 경우 768 x 1344 를 선호한다. 16:9 에 가장 가깝기 때문에 그렇다. 두번째로는 832 x 1216 을 사용한다. 대략 3:2 비율이기 때문이다.
SDXL 은 생성할 이미지의 비율에 따라 이미지의 구도가 달라지기 때문에, 생성해보다가 구도가 맞지 않으면 다른 걸 사용해도 된다.
아래 이미지를 보자.

1536 x 640

1344 x 768

1216 x 832

1152 x 896

1024 x 1024
모두 동일한 프롬프트와 시드에서, 해상도만 변경해서 생성한 이미지다. 머리 모양과 흩날리는 정도가 이미지 비율에 따라 변경되는걸 볼 수 있다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SDXL 에서 VAE 는 FP32 으로 사용하곤 한다. FP16 으로 된 VAE 라도, FP32 으로 변환해서 사용한다. 이렇게 하는 이유가 SDXL 의 경우 VAE 를 사용해 이미지를 변환할 때, NaN 오류가 많이 발생하기 때문이다.
- 그래서 필자도 Stable Diffusion webUI (SDUI) 에서 --no-half-vae 옵션을 주어 사용했다. 이렇게 하면 NaN 이 발생하지 않아 이미지가 검게 생성되는 현상을 없앨 수 있었다. 반대로 이 옵션을 주지 않으면, 매우 자주 발생한다.
여태까지 --no-half-vae 옵션을 주면서 사용하다가, 최근에 이에 대한 패치가 나온걸 알 았다. VAE 에 대한 FP16 FIX 이다. SDXL-VAE-FP16-Fix 에 나와있는
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/resolve/main/sdxl.vae.safetensors
을 다운로드 받아 사용하면 된다.
- VAE를 받아 SDUI 의 VAE 디렉토리에 넣고 이 VAE 를 사용하도록 세팅한다. 그리고 --no-half-vae 옵션을 사용하고 SDUI 를 실행해보면, 이미지 생성시 아래와 같이 메모리 사용량이 줄어드는걸 볼 수 있다.

SDXL 에서 FP16 VAE 으로 세팅하고 이미지를 생성시 전용 GPU 메모리 사용량

SDXL 에서 FP32 VAE 으로 세팅하고 이미지를 생성시 전용 GPU 메모리 사용량
FP32 VAE 사용시 마지막 단계에서 FP32 VAE 를 사용하기 위해 메모리 사용량이 급격히 (2배) 늘어나는걸 볼 수 있다. 이미지 품질에는 영향이 없기 때문에 FP16을 사용할 수 있으면 사용해야 한다.
- 시간과 메모리 사용량은 아래와 같이 비교된다.
FP32 VAE: 생성시간 4 min. 18.3 sec. A: 8.37 GB, R: 26.08 GB, Sys: 16.0/15.9961 GB (100.0%)
FP16 VAE: 생성시간 3 min. 49.4 sec. A: 5.22 GB, R: 9.99 GB, Sys: 11.2/15.9961 GB (69.8%)
- 또한 HiResFix 나 Upscale 작업시에는 VRAM 이 부족한 경우가 많다. 부족한 경우 Tiled VAE 를 사용할 수도 있지만, FP16을 사용할 수도 있을것 같다. 아니면 두가지 모두 사용하거나 말이다.
- FP16 VAE 를 사용해서 문제가 생기면(검은색 이미지가 생성되면) SDUI 의 아래 옵션을 체크해보자. NaN 이 발생하는 경우 자동으로 BF16이나 FP16으로 변환해 사용한다. BF16 을 사용하는 경우 GPU 에서 지원하는지 반드시 확인해야 한다. 잘 모르겟으면 해제하면 된다.
☑ Automatically convert VAE to bfloat16 ☑ Automatically revert VAE to 32-bit floats
- FP16 VAE 설명을 보면, NaN 이 자주 발생하는건 일부 활성화 값이 너무 크기 때문이라고 한다. 이 값을 조절하기 위해 몇가지 작업을 했다고 한다.

활성화 값이 큰 예시
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음