윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
2464 개 검색됨 : 분류 전체보기 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
우연히 그린 복장. 마음에 들었다. 무슨 복장이라고 해야할지는 모르겠다.















- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 시사,사회

민주주의 최후의 보루는 깨어있는 시민의 조직된 힘입니다.
노무현 대통령이 축사영상에서 이야기한 말입니다. 요즘에 가장 와 닿는 말이네요.
계엄이 일어났다가 해제되었지만 아직까지도 후폭풍은 가라앉지 않고 있습니다. 경제적으로는 최소 300조, 최대 900조 정도의 손실을 예상하고, 이 손실은 우리 오천만 국민들이 할부로 갚아나가야 할거라고 합니다. 에혀... 중국의 거센 추격을 떨쳐내기도 힘든데 이런 것까지 신경써야 할건지 모르겠네요.

그리고 한가지 더 이야기 하고 싶습니다. 저는 쿠데타 실패의 가장 큰 원인이 바로 "교육"이라고 생각합니다. 요즘에는 학교에서 5.18 이나 12.12 에 대해 배우고, 당시의 참상에 대해 배우고 있습니다. 군인은 국민을 향해 총을 겨누면 안된다는 걸 배우죠. 제가 중/고등학생 때에는 배우지 않은 내용입니다. 그리고 권력은 국민에게서 나오고 영원한 권력은 없다, 독재는 없다는 걸 알려주죠. 5.18을 일으킨 주범은 결국 사형을 선고 받은것도 알고 있습니다. 즉 군인이라 해도 불법적인 명령에 따를필요 없다는걸 알고 있고, 무었이 불법적인것인지 정확히 이해하고 있습니다. 오직 그들만이 젊은 군인들이 그 명령에 따를리가 없다는걸 이해하지 못한거 같네요.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
GB200 의 이야기는 많은데 구체적으로 어떤건지는 잘 몰라서 찾아봤습니다. GB200이 칩을 이야기하는게 아닌거 같아서 찾아본겁니다.
B200 은 nVidia 의 최신 GPU 칩의 모델 이름입니다. 이 칩의 코드명이 Blackwell 입니다.

nVidia B200
GB200 은 1개의 Grace CPU 와 2개의 B200 으로 이루어진 일종의 보드입니다. 아래와 같이 생겼죠. 그런데 이걸 "Grace Blackwell Superchip" 이라고 부릅니다. Chip 이라는 단어때문에 이게 보드인지 칩인지 계속 혼동되었네요.

nVidia GB200 (Grace Blackwell Superchip)
이걸 NVLink 을 사용해 36개 연결해 총 72 개의 Blackwell GPU 을 내장한게 GB200 NVL72 입니다. NVLink 는 칩과 칩을 연결해주는 고속 인터커넥트 기술입니다.

nVidia GB200 NVL72
스펙은 아래와 같습니다. FP16 이 360PFLOPS 라는게 인상깊네요. 여기에 그 유명한 HBM3e 가 들어갑니다. 하나 가지고는 싶습니다.
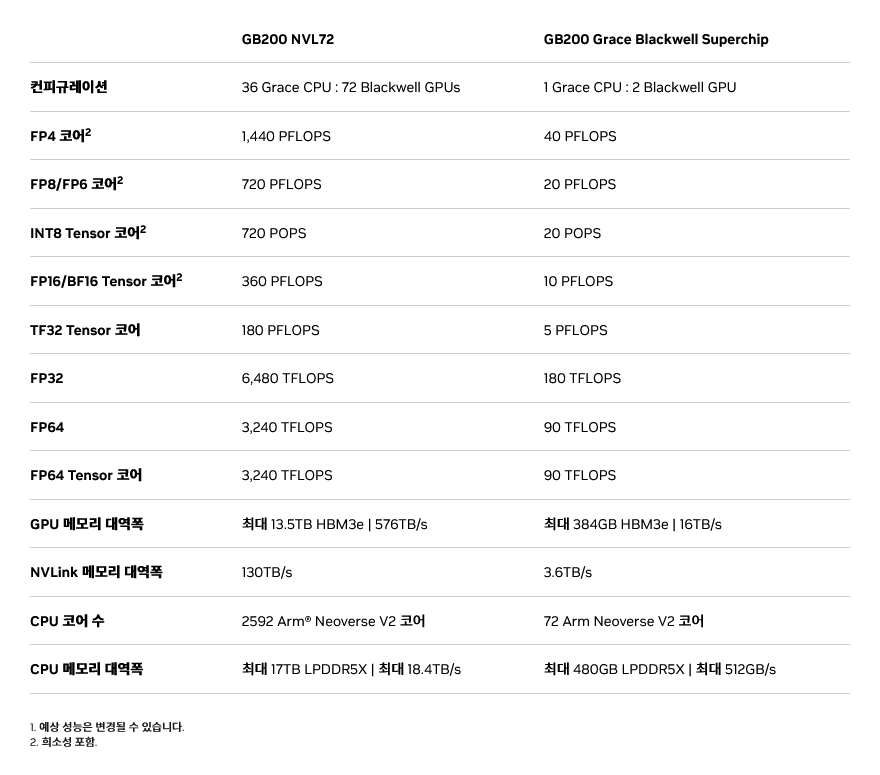
스펙에는 안 나와있지만 GB200 NVL72의 TDP 가 140kW 으로 알려져 있습니다. 보통의 1U 서버 1대의 소비전력이 1kW 정도이고 1Rack(24U) 를 모두 채운다고 해도 24kW 입니다. 2Rack 을 사용하는 GB200 NVL72 라 해도, 소비전력이 140kW 라면 매우 높긴 하네요. 그래도 이전 세대보다 전성비는 좋습니다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 시사,사회
2024년 12월 3일 22시 27분 비상 계엄이 선포되었습니다. 살다살다 계엄 선포가 된 시대에도 살아보네요. 얼마나 빨리 수습될지는 모르겠습니다만 참 많은걸 생각하게 해줍니다. 이게 그냥 그냥 넘어갈 수 있는 문제가 아니었나 보네요.
계엄(Martial law) 은 행정 및 사법권을 대통령이 임명한 계엄사령관이 행사하는 제도를 말합니다. 입법권은 안 넘김니다.
우리나라에서 마지막 계엄은 1979년 10월 27일에 발효되었었습니다. 10.26으로 인해 발효되었죠. 이후 45년만이네요.
2024.12.03 22:27 비상 계엄 선포
2024.12.03 23:00 계엄사령부 포고령 1호 발표
2024.12.03 23:48 국회 위로 군용 헬기가 가는게 카메라에 잡혔네요.
2024.12.04 00:33 제418회 국회(정기회) 제15차 본회의 시작
2024.12.04 00:34 군인들이 창문을 깨고 국회에 진입하는게 화면에 나왔군요.
2024.12.04 01:01 제418회 국회(정기회) 제15차 본회의에서 "비상계엄 해제 요구 결의안"을 가결했습니다. 출석 190 찬성 190으로요. 헌법에 따라 대통령은 계엄을 즉시 해제해야 한다고 하네요. 그래도 민주적인 시스템이 살아있다는게 다행이긴 하네요. 155.7 분간의 계엄이었네요.
2024.12.04 04:27 계엄 해제 선포
2024.12.14 17:00 대통령(윤석열) 탄핵소추안 가결
2025.04.04 11:22 (헌법재판소) 재판관 만장일치로 피청구인 대통령 윤석열 파면 선고

비상계엄 해제 요구 결의안 가결
----
국회에 진입한 군인들은 1공수여단 이라는 이야기가 있네요. 탄창 띠 색으로 봐선 실탄이 아닌 훈련용 탄인걸로 생각된다고 하네요.
야당 의원들이 국회의사당 근처에서 회식중이었다고 합니다. 그래서 빨리 모일 수 있었다고 하네요.
3개월즘 전에 계엄 이야기 나왔을대 설마 하겠어 했는데 진짜로 했네요. 상상도 못했습니다.
----
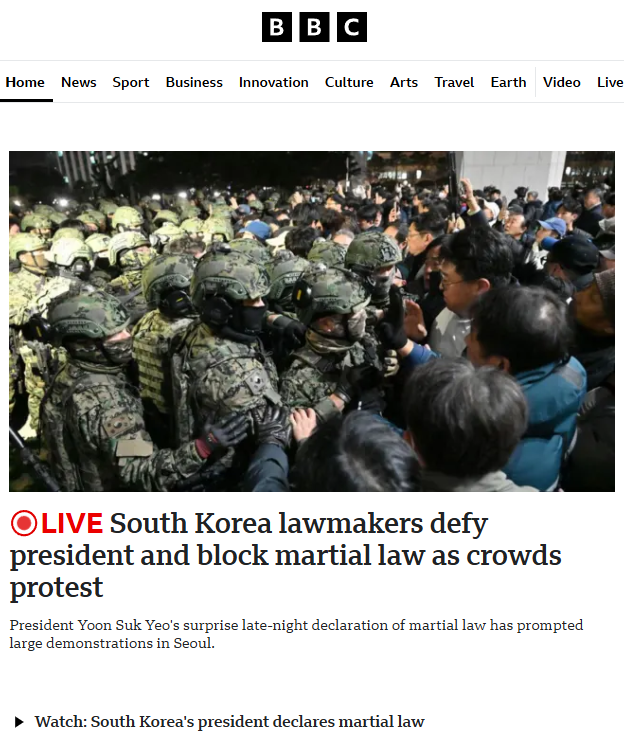
BBC 속보 나왔습니다.
- 태그 헌법
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
많은 눈이 지나고 단풍이 왔네요. 왠지 지금이 가을 같다는 느낌입니다. 이제야 주변에 낙엽에 떨어지고 있네요.
오래전부터 단풍이 예쁠 때 올리려던 이미지 하나 올립니다.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT

작동전압/전류: 12V / 0.29A
최소전압: 3.9V
팬크기: 120mm
팬두께: 25T
베어링: Hydrodynamic Bearing
회전속도: 200 ~ 3300RPM
풍량: 81.04CFM
풍압: 4.35 mmH2O
팬소음: 27dBA (0.6sone)
기타: PWM, 제로팬(5% PWM)
케이블길이: 400 mm
무게: 184g
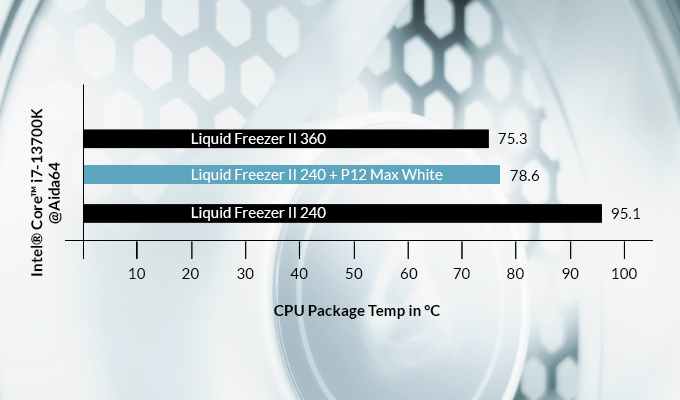
꽤 오래전부터 Arctic 의 제품을 주로 써와서 망설임없이 구매했다. 어차피 팬 컨트롤러 달아서 사용하기 때문에 소음도 크게 문제 없고 말이다.
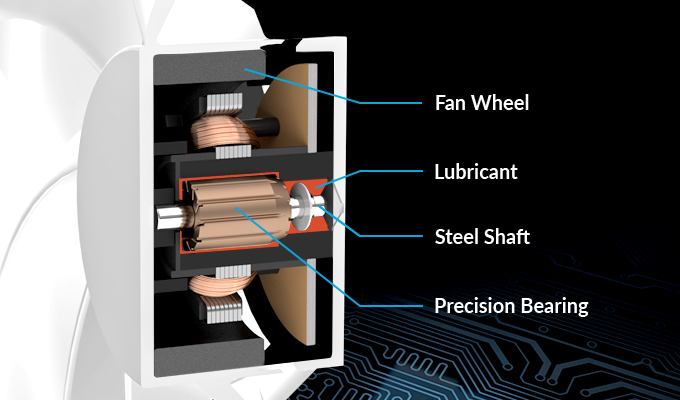
팬이 조금 특이하다. 팬 블레이드 끝를 자세히 보면, 휠이 보인다. 이 휠이 같이 회전한다. 진동을 줄여준다고 한다. 아래 이미지를 보자.

- 가장자리에 고무가 달려있어서 진동을 억제한다.

- 팬 RPM 이 넓은 범위에 있기 때문에 열을 잘 식혀준다고 한다.
- 팬 베어링 구조
- 제로팬

- 바람이 분산되지 않는다.

이 팬이 예전에는 2볼베어링 이었던것 같다. 내가산건 박스의 베어링 스펙 부분에 "Fluid Dynamic Bearing"이라는 스티커가 붙어있고 스펙을 검색 해보면 2볼 베어링으로 나오는 경우도 제법 있다. 베어링만 바뀐것으로 스펙은 동일하다. (2볼베어링으로 27dBA 가 나온게 대단하긴 하다)
----
PC Direct 에서 수입한걸 샀고 A/S 기간은 6년이다. 2024.06.13 에 4개 구매. 개당 약 9,800 원.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
필자가 본 에니에서, 아름다운 여인을 이야기할 때 빼놓지 않는 캐릭터가 바로 메텔이다. 은하철도 999 라는 에니메이션에 나오는 그 메텔 맞다.
털모자 샤프카와 털 코트 슈바, 흩날리는 긴 금발, 갈색 눈동자, 어딘가 슬퍼보이는 얼굴이 프롬프트다.

내가 생성하는 이미지에서는 메텔의 영향을 받은게 꽤 있다. 프롬프트를 변경하다 보면 이런 분위기를 내도록 하는 경우도 있으니깐 말이다. 그만큼 인상 깊었고, 이런 분위기의 여성을 좋아하는 편이기도 하다.
은하철도999의 줄거리는 대체적으로 암울하다. 원래 메텔은 메텔에 의해 희생된 아이들을 위한 속죄를 상징하는 인물이니 그렇다. 그래서 다른 에니에서 밝은 모습으로 나왔으면 하는 바램이 있다. 그래서 한번 제작해 보았다.
- 약간 현대적으로 재 해석한 메텔. 가장 맘에 든다.

- 작은 가게에서 점원으로 일하고 있는 숏컷 메텔


- 군대에서의 지휘관같은 인상을 보이는 메텔

짧은 스커트도 어울린다.


- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
2009년에 구매했던 nVidia GeForce 8400GS 의 팬이 몇년전에 고장나서 작동하지 않았다. 팬이 작동하지 않으면 발열이 해소되질 않기 때문에, 그리고 어차피 구형이라 사용하지 않고 있었는데, 갑자기 필요하게 되어서 부랴부랴 팬을 교체했다.

COOLERTEC CTV-OB9-LP
홀간격이 55mm이고, LP 타입의 VGA에서 사용할 수 있는 쿨러로 구매했다. 결국 COOLERTEC CTV-OB9-LP 으로 구매. 결제하려고 보니 8000원에 가까운 금액이라 망설여지긴 했지만 그냥 결제했다.
장착은 잘 되었지만, 팬를 VGA 의 팬 핀에 연결해도 쿨러가 돌지 않았다. 아무래도 VGA 가 고장난듯. 그냥 마더보드의 3핀에 끼워 넣었다. 다행이도 잘 돌아간다. 쿨러 스펙은 12V, 0.10A, 12.4CFM, 볼베어링, 10T, 4000 RPM 이라 소음은 제법 있다. 노이즈가 18dBA 라고 되어있는데 그것보다는 훨씬 큰거 같다.
팬 소음은 제법 있어서, 전압을 낮춰서 사용하고 있다. 열은 조금 있지만 그래도 조용하니 좋다. 쿨러 고를 때에는 팬이 없는 것도 고려해봤지만, 8400GS G98 의 25W 의 TDP 를 식힐 수 있는 방열판은 꽤 크기 때문에 LP 규격에 맞는게 없어서 그냥 팬 있는 걸로 골랐다.
----
2024.11.24
팬이 안돌아가는건 팬 전극이 뒤바꼈기 때문이다. 테스트기로 VGA의 팬 전극을 체크해보니 -12V 으로 나온다. 팬의 +, - 를 바꿔끼면 되는건데 그냥 안하기로 했다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
nVidia 의 최신 GPU 블랙웰에서 발열 이슈?
nVidia 의 최신 GPU 제품인 블랙웰 제품에서, 발열 이슈가 있다고 합니다. 하지만 글쎄요, 어차피 발열은 예상 되어있는게 아닌가 하네요. TDP 가 1000 W가 넘는다고 하는데, 그정도면 서버에서는 크게 문제되지 않을 정도의 발열입니다. 물론 한개의 칩만 사용하는건 아니고, 서버 룸에 공조 시설과 냉방 시설이 잘 되어있어야 문제가 안되겠지만요. 1000 W 가 크긴 하지만 이게 이슈가 되었다는게 조금 이상하긴 하네요. 게다가 이미 알고 있던거 아니였나요. 그래서 IDC에도 수랭이라던가 유랭이라던가 도입한다고 했구요. 칩당 1000W 정도면 수랭 필요하다고 생각합니다.

Stable Diffusion 으로 작성한 Blackwell. 검은 우물?
AI로 그림그리는걸 시작했을때, 하드웨어 업그레이드 이후에 신경써야 할것이 발열이었습니다. RTX 2060 12G 의 184W TDP를, 당시 가지고 있던 저가형 케이스로는 제대로 냉각할 수가 없었죠. 부랴 부랴 케이스 부터 큰 걸로 바꾸고 팬 바꾸고, VGA 수직 장착하고, CPU 쿨러를 수랭으로 바꿨습니다. 그래서 지금은 해보진 않았지만 400W TDP 정도까진 버티지 않을까 생각되네요. 그래도 GPU 온도가 80도이고 케이스 내부온도도 뜨겁다고 생각하기 때문에 좀 더 낮추려고 노력하고 있습니다.
GPU 세대가 거듭되면서 데이터센터에서 사용하는 GPU 는 발열이 많아지긴 하지만, 전성비는 계속 좋아지고 있습니다. 지금 제가 사용하는 RTX 4060Ti 도 예전의 RTX 2060 의 2배 정도 성능(이론상 성능)이지만 발열은 183W -> 165W 으로 더 낮아졌으니까요. 이번 블랙웰도 더 좋아졌을것이라고 생각합니다. 5060 나올때가 되면 특이사항 없으면 아마 바꾸겠죠.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 시사,사회
빈 카운터스는 기업의 본질적 가치가 아니라 재무제표상 숫자를 중시하는 사람들이 기업을 이끌며 모든 문제를 단기 수익률 등 숫자로만 접근하는 걸 뜻합니다. 의미상으로는, 콩의 개수만 세는걸 의미하죠. 콩의 품질은 고려하지 않구요.

요즘의 인텔이나, 삼성을 보면 기술로 먹고 사는 기업들이 기술을 개발하지 않는 세태, 마케팅, 영업이나 비용 절감을 외치면서 기술 개발에 투자하지 않는게 얼마나 위험한건지 느끼게 해줍니다. 그렇다고 기술 개발"만" 하라는건 아닙니다. 기술 개발도 어느 정도 견제가 이루어지지 않으면 굉장히 비효율적으로 이뤄지니까요. 문제는 마케팅이나 비용 절감에 중점을 두고 기술 개발을 등안시 한 기간입니다. 요즘 세대에서는 1년정도만 기술 개발을 등안시해도 문제 되는 시대입니다. 인텔이나 삼성을 보면 5년 ~ 10년은 기술개발을 별로 하지 않은것 같네요. 이정도 이니 문제가 되는겁니다.
저는 개인적으로 삼성이나 인텔이 이 위기는 극복할 수 있을 거라고 생각합니다. 그래도 그간의 저력이라는게 있고, 뒤늦게나마 기술 개발을 시작했고, 아직 후발 주자가 파이를 다 가져간게 아니기 때문에 다시 회복할 수 있다고 생각합니다. 대체할만한것도 마땅치 않구요.
문제는 주식입니다. 현 시점에서는 미래가치를 보고 투자하는 주식시장에서는 현재로써는 미래가치가 없는건 맞으니까요.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음