- 글쓴시간
- 분류 기술,IT
DeepSeek R1는 중국의 DeepSeek 에서 개발한 LLM 모델입니다. 쉽게 말하면 ChatGPT 같이 사용할 수 있는 AI 라고 생각하면 됩니다. 요즘에 주목받는 AI인데요, 그 이유중 하나가 성능이 좋고 무었보다 오픈소스이기 때문입니다.
성능이 좋다는건 사용자가 원하는 답을 잘 내어준다는 의미입니다. 들리는 말에 의하면 OpenAI 의 ChatGPT o1 보다 더 좋다는 말이 있네요.
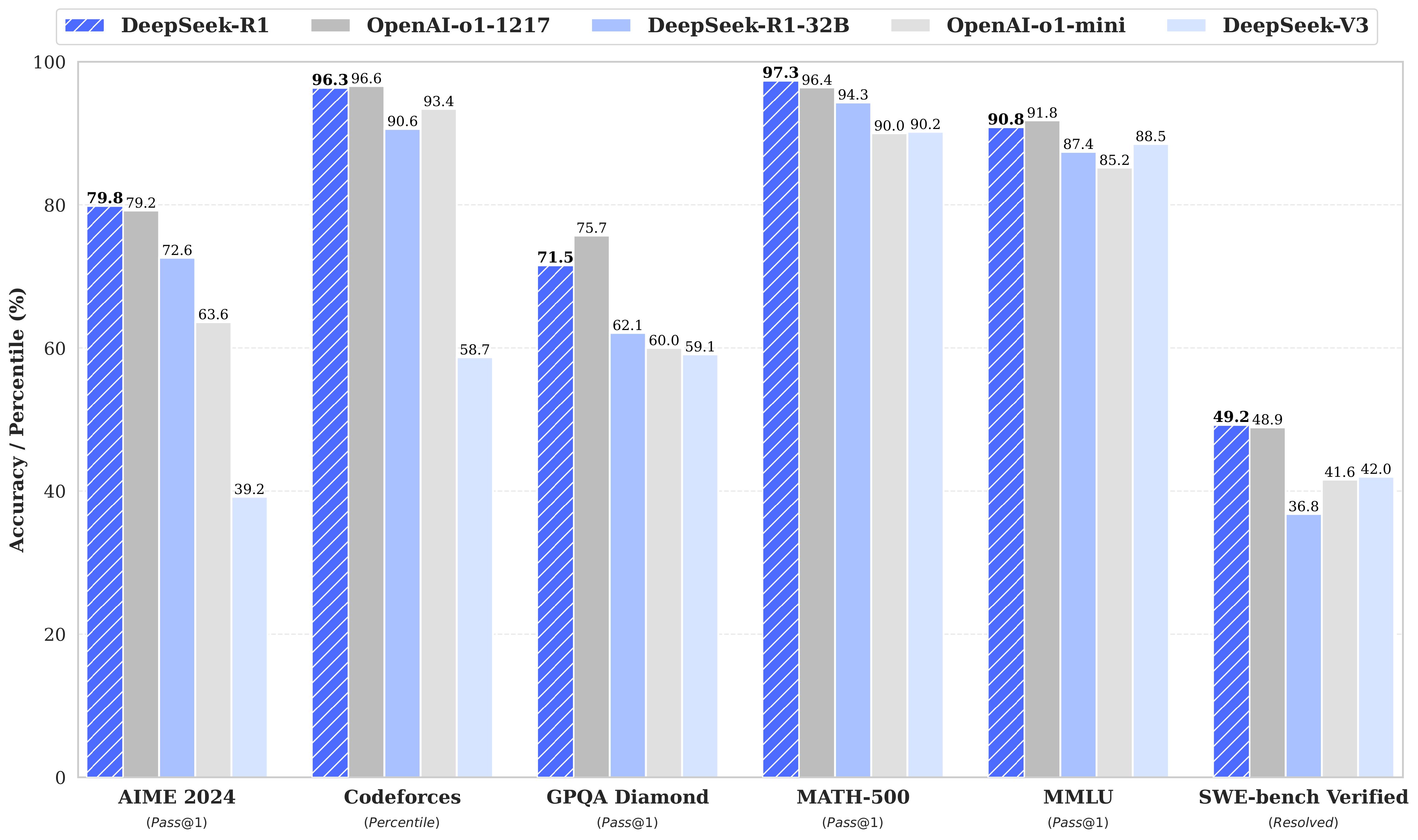
DeepSeek R1 벤치마크.
하지만 저에게 무었보다 좋은건 오픈소스라는 점 때문입니다. 이정도 성능의 모델을 오픈 소스로 풀 거라고는 생각 못했습니다. 오픈 소스로 풀린다고 해서, 당장 제가 가진 PC에서 돌려보거나 할 수는 없겠습니다만, 일단 오픈소스라는게 가장 좋아보이네요. 몇몇 사용기가 올라온걸 보면 꽤 괜찮다는것 같습니다. AI 에서 중요한 것 중 하나가 개방성인데, 거대 LLM 을 오픈하는건 중국이 미국보다 먼저 했네요.
비용이 많이 들어가는 RLHF(Reinforcement Learning from Human Feedback, 인간의 피드백에 의한 강화 학습), SFT(Supervisor Fine Tuning, 감독자에 의한 파인 튜닝)을 사용하지 않고, RL(Reinforcement Learning, 강화 학습) 만을 사용했다고 합니다. 그래서 비용이 줄었다고 하네요. 이게 대단한게 RL 만으로는 한계가 있어서 RLHF, SFT 를 사용했던건데, 다시 RL 만으로도 된다는걸 보여주는 거라고 합니다. 물론 RL 만으로 학습한게 티가 난다고 합니다만, 어느 정도일지는 사용자마다 다르겠죠. 어쨋던 대단하긴 합니다.

또한 MOE(Mixture of Experts, 전문가 혼합) 기법을 사용해 특정 주제에 맞는 부분만 활성화 시켜 연산시키기 때문에 훈련과 추론시 사용하는 메모리를 줄였고, MLA(Multi-head Latent Attention) 를 사용해 키-값을 처리해 메모리를 더 줄였습니다. 마지막으로 nVidia CUDA에서 사용하는 PTX(Parallel Thread xecution)를 적극적으로 사용해서 성능을 향상시켰습니다. PTX 는 일종의 하드웨어 독립적인 언어로, CUDA 보다도 더 저수준의 언어입니다. PTX 는 일종의 GPU용 어셈블러이긴 하지만 하드웨어 독립적입니다. (하드웨어 독립적이긴 하지만 nVidia 제품에만 사용됩니다. nVidia GPU 아키텍처에 독립적이라는 의미입니다. CUDA/PTX 를 사사용해 작성한 코드는 바이너리 코드로 변환되어 실행되는데 이 바이너리 코드를 SASS(Source and Assembly)라고 부릅니다. SASS 가 GPU에 의존적입니다) PTX 를 사용한다는게 굉장히 어려운 일이기 때문에 CUDA 정도만 사용했었는데, 중국에서는 이걸 했나보네요.

또한, 아직 추정이긴 합니다만, Distilled(추출기법)도 사용했을거라고도 생각합니다. 학습된 모델의 추론 결과를 학습할 모델의 입력으로 사용하는걸 말합니다. 쉽게 말하면 ChatGPT 의 결과를 DeepSeek 의 입력으로 사용했다는 겁니다. (이런 방식은 ChatGPT 이용 약관 위반입니다) 기사를 보면 OpenAI 에서는 어느 정도 증거를 가지고 있는것 같이 보입니다.
중국에 대한 수출 제한으로 nVidia H100 을 사용하지 못하는 제약때문에 nVidia H800 (H100 의 중국 수출 판)을 사용할 수 밖에 없었는데, H800 이 가진 한계(칩 간 전송 데이터 폭이 H100 의 절반, FP64 성능은 많이 떨어지나 FP32, TP32, BF16, FP16 의 연산은 성능이 동일함)를 극복한걸로 보이네요. H800 이 H100 에 비해 그렇게 떨어지는것도 아니긴 하구요.

nVidia H100
사용하는 방법에는 여러가지가 있겠습니다만 제가 본건 nVidia 에서 배포한 TensorRT-LLM - Deepseek-v3 사용 방법입니다. 여기에서는 BF16을 사용할 걸 추천하는데, 이경우 GPU 메모리가 1.3TB 이상 되어야 합니다. 모델 파일만 650GB 정도 되어보이고 모델 파일은 FP8 으로 되어있는것 같네요. 게다가 현재는 Hopper 아키텍처에서만 작동한다고 합니다
생성형 AI 를 사용하는 때에도, 중국 아니면 일본, 미국에서 만든 LoRA 가 많이 올라옵니다. 중국이 특히 많구요, 우리나라도 제법 있긴 합니다만, 다수라고 보기엔 무리가 있습니다. 그나마 오노마에이아이 (Onoma.AI) 에서 만든 Illustrious XL(ILXL) 과, ILXL 기반으로 만든 NoobAI-XL 이 생성형 AI 에서는 제법 알아준다고나 할까요. 우리나라도 어서 LLM 이 공개되었으면 하네요. 누가 공개할지는 모르겠습니다만 말이죠.
로컬에서 실행하는 방법: DeepSeek R1 로컬에서 실행

