윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
1001 개 검색됨 : 기술,IT 에 대한 결과
- 글쓴시간
- 분류 기술,IT/하드웨어 정보
SilverStone SST-FLP02W
재미있는 케이스가 나와서 올려본다. 실버스톤의 FLP02 라는 모델이다.

레트로감성 풍만한 케이스다. 요즘엔 플로피나 ODD 를 달 수 있는 5.25 인치 확장 슬롯이 있는 모델이 나오지 않지만, 불과 10여년전만 해도 흔했다. 게다가 20여년전에 볼 수 있었던 잠금장치를 2026년에 볼 수 있을거라고는 생각 못했다. 터보키도 구현해 놓았다. 전원 버튼도 요즘 나오는건 버튼식이라 저런식으로 구현하기 힘들었을 것 같다. 실제로 작동되는 건 20여년전의것과는 다르다. 잠금키는 리셋버튼의 잠금키고, 터보키는 PWM 조절장치라고 한다.

재미삼아 구매하기엔 너무 비싸다. 30만원 정도. 그래도 이런 케이스가 나오니 반갑긴 하다.
같은회사에서 아래와 같이 HTPC 모델인 FLP01 이 나왔다. 이것도 만만치 않는 가격이다.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전





- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
근하신년 텍스트가 들어간 이미지를 만드려고 했지만, SDXL 기반에서는 텍스트는 그냥 안된다고 보는게 맞을거 같다. 그래서 그냥 없는걸로 만들었다. 마침 CivitAI 에 비슷한 이미지가 있길래 프롬프트를 기반으로 따라했다. 생각보다는 잘 나왔다.
만들고 난 후에 알았지만, 이거 기모노 기반이었다. 중국의상이 아니라 말이다. 끄긍.


- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/하드웨어 정보
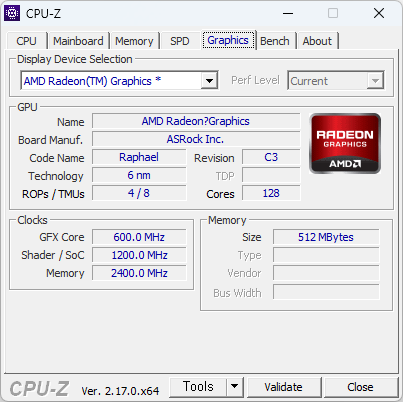
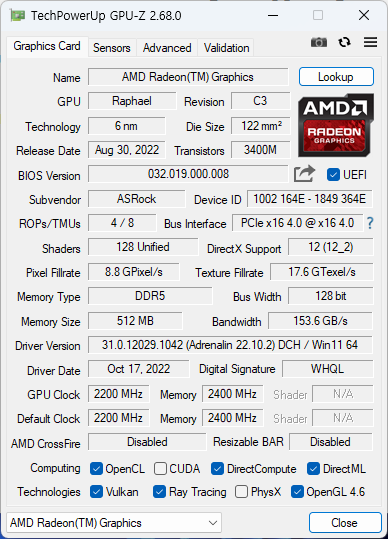
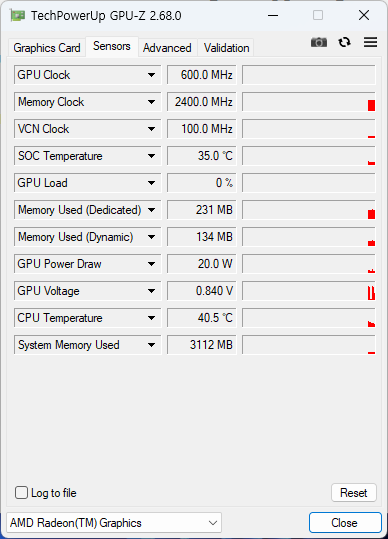
우연히 써보게 된 3070Ti 에 대한 GPU-Z 다. 생각보다 4060Ti 과 성능차이가 나지 않는다. (물론 3070Ti 가 더 좋다) GPU 메모리는 8GB vs 16GB 이니 이부분은 4060Ti 가 더 좋긴 하겠지만 말이다.
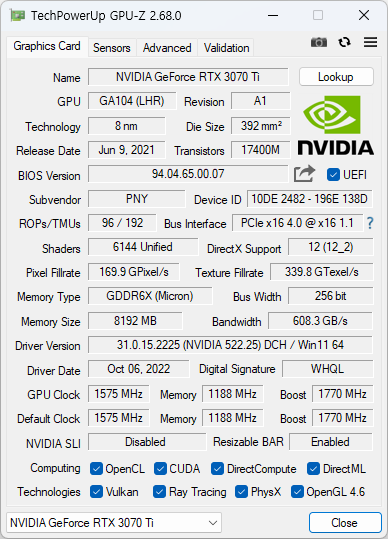
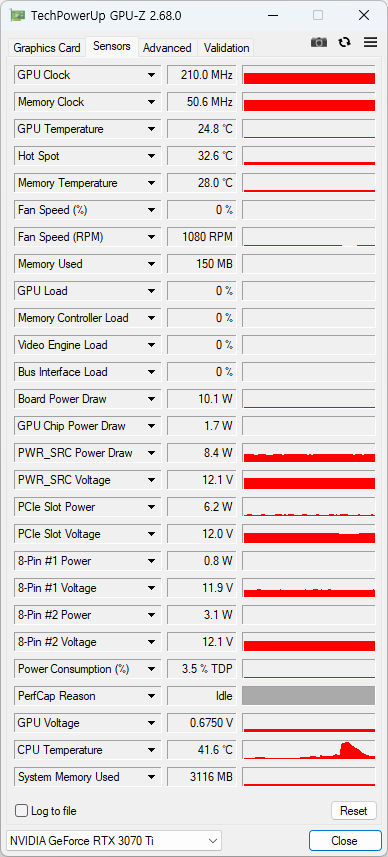
센서는 4060과 동일한 느낌.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/하드웨어 정보
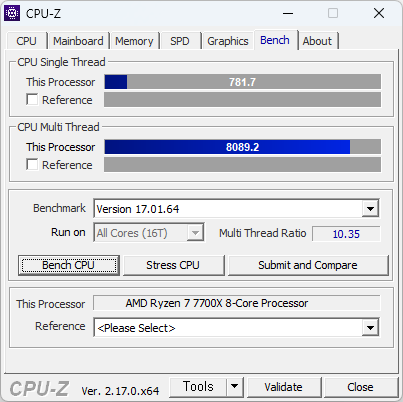
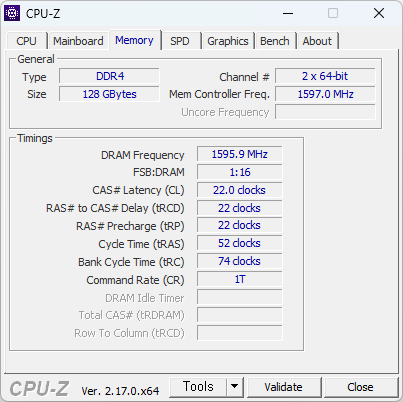
이번에 사용해본 CPU. 생각보다 빠르다. 많이 빠르다. 바꿔야 겠지만, 메모리가격이 문제다.
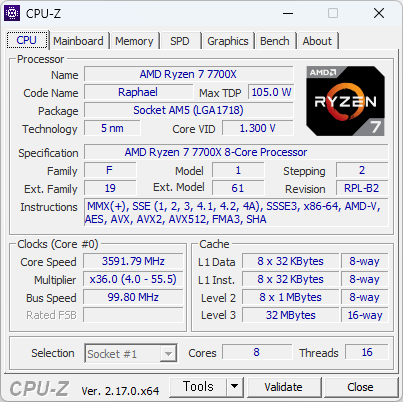
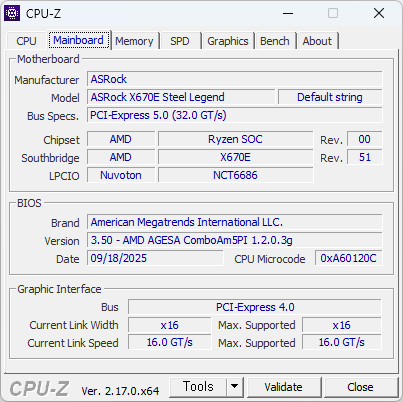
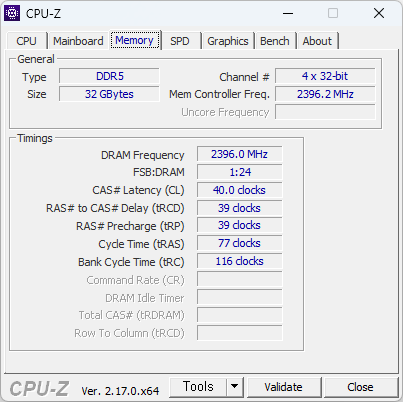
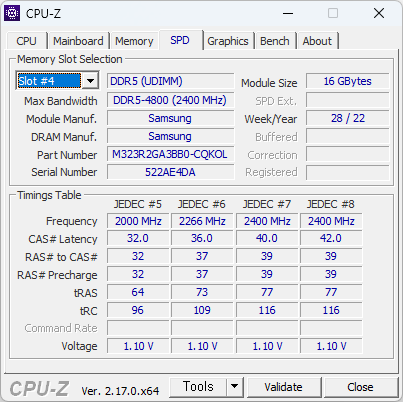
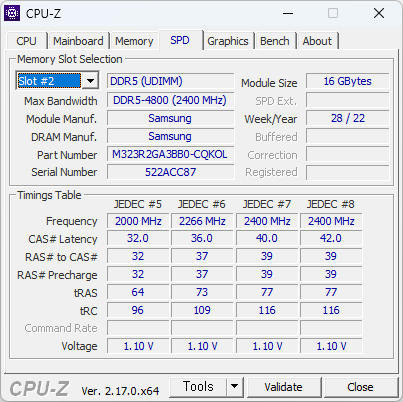
싱글점수가 700점을 넘는다. 현재 쓰고 있는것에 거의 80% 이상 빠르다. 이러니 빠른게 체감될 수 밖에.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
스테인드 글라스를 배경으로 만들어보았다. #4 와는 조금 다른 느낌. 역시 이런 복잡도 높은 이미지 생성할때에는 손가락이 가장 문제다.



- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
Wan 2.2 는 중국 알리바바그룹의 통이 연구소에서 개발한 시각모델이다. 2025.07.28에 공개되었다. 주로 동영상을 만들기 위해 사용한다. 오픈소스로 공개되어있다.
기존의 Wan 2.1 의 완성판이다. 이후에는 Wan 2.5 가 나올꺼고, 현재는 WAN 2.5 의 프리뷰버전까지 나왔다. 하지만 이제서야 2.2 를 써 본다.
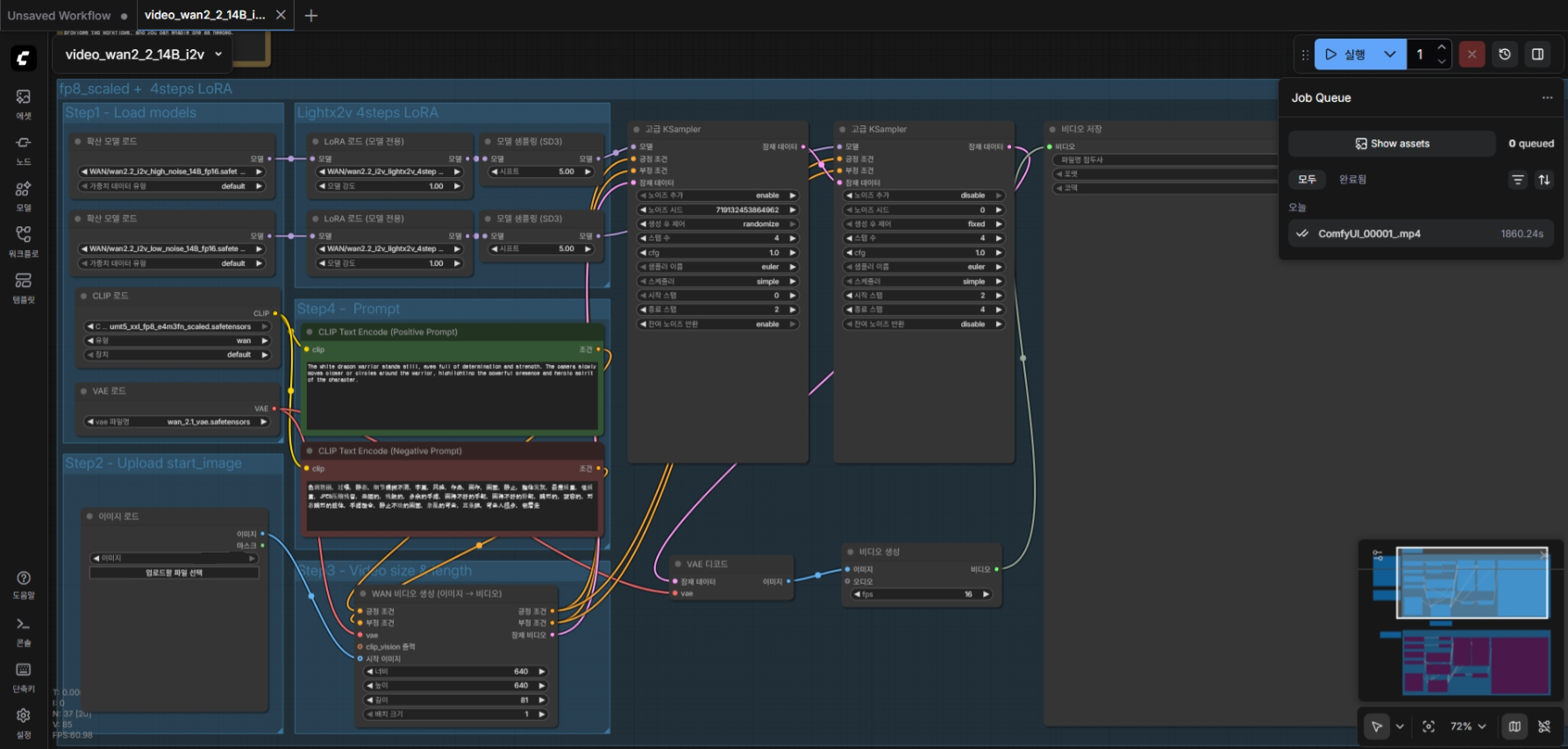
WAN 2.2 의 기본 워크플로. 2060 12G 에서 생성에 30분 걸렸다.
사용방법은 Wan 2.1 과 비슷하다. 모델만 2.2 로 바꿔주면 되는데, Wan 2.2 부터 I2V 에서 High - Low 모델이 분리되었다. High 모델은 구도 잡는데, Low 모델은 디테일을 높이는 데 사용한다. 따라서 동영상을 생성하기 위해서는 모델 2개를 순차적으로 돌려야 한다. 또한 모델 로딩에 필요한 메모리가 2배로 들어간다. 64GB 시스템 메모리에서 간신히 로딩된다. 128GB 는 필요하다. 벌써부터 64GB 메모리가 부족할 줄이야.

ComfyUI 0.4.0 + WAN 2.2 에서 I2V 실행후 남아있는 메모리 사용량. 스왑메모리 사용량을 감안하면 64GB 시스템에서 사실상 모자른 셈이다.
Lightx2v 에서 정제버전을 공개했다. 이를 사용하면 4 스텝으로도 충분한 품질을 얻을 수 있다고 한다. 20 스텝 -> 4 스텝 이니 5배나 빨라진 셈이다. 안쓸 이유가 없고 ComfyUI 문서에도 사용하라고 나온다.
RIFE VFI 프레임 보간을 사용해서 생성할 이미지의 FPS 를 올려주는 방법도 있다고 하는데 아직 적용은 못해봤다.
Wan2.2 Video Generation ComfyUI Official Native Workflow Example - ComfyUI
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전

- 16GB 메모리 를 가진 소비자용 GPU 에 최적화되어있는게 특징입니다. 파라메터 개수는 6B 입니다. 오픈소스이고, Apache-2.0 라이선스라 상업적으로 사용하는 것도 자유롭습니다. 또한 이미지 생성할 시, 9개 스탭 정도로도 충분한 이미지 퀄리티를 보여줍니다.
- 현재는 Python 코드로 사용하거나, ComfyUI 에서 사용 가능합니다.
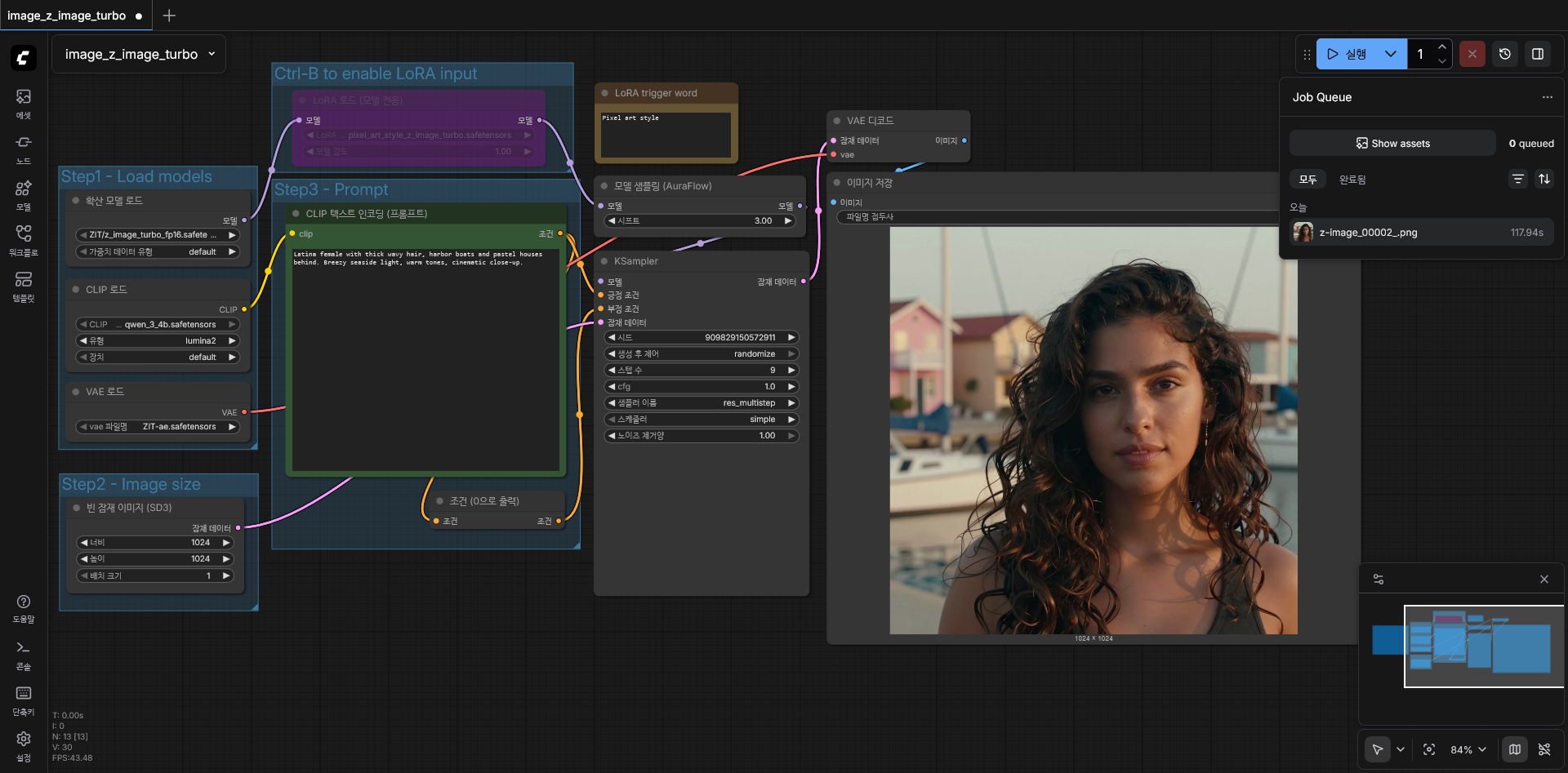
2060 12GB 에서 기본값으로 실행.
- 기본 워크플로를 사용해 생성했을때, 117.9초 소요됩니다. 1024x1024 이미지 임에도 불구하고 2060 에서는 꽤 느리기 때문에 당분간은 SDXL 을 사용할 수 밖에 없겠습니다. 조만간 5060 정도로 바꿀 지도 모르겠네요.
- 제가 가지고 있는 2060 12GB 에서 작동시키기 위해 FP16 버전을 사용했습니다. BF16 과 비교해서 성능에 큰 차이는 없습니다. (물론 그래도 할 수 있다면 BF16을 사용하는게 좋습니다) ComfyUI 실행시킬 때 "--use-sage-attention --force-fp16" 옵션을 추가로 주었고, "pip install sageattention" 명령을 주어 파이썬 패키지를 설치했습니다. sageattention 을 사용하기 위해 "apt install python3.12-dev" 패키지도 설치했죠. 최종적으로 27초로 단축되었네요.
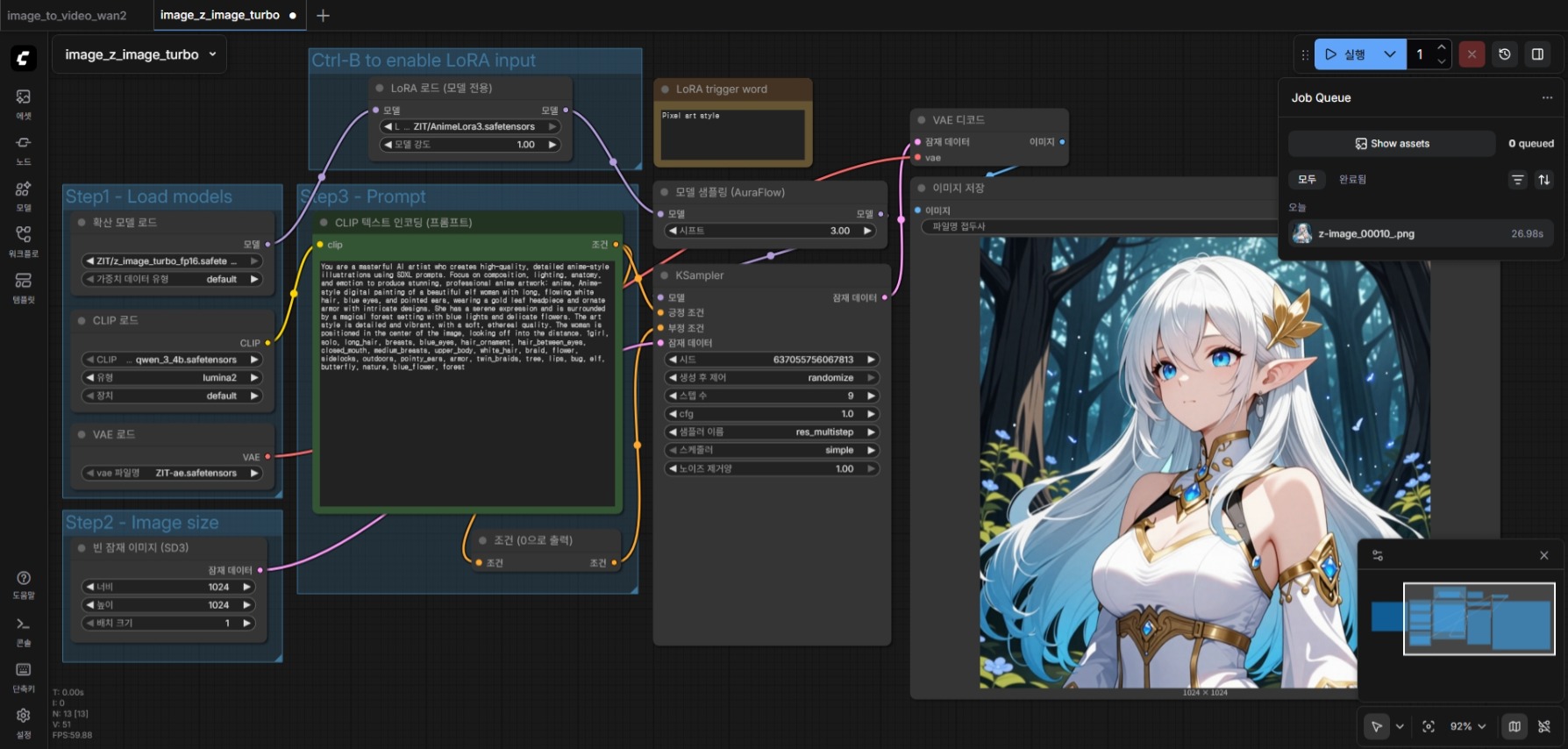
2060 12GB 에서 기본값으로 실행. 27초 소요.
- 아직 에니메이션 풍의 이미지는 생성하기 어려워 보입니다. 뭔가 실사판 이미지를 에니로 바꾼 느낌이네요. SDXL 에 비해 사용자가 많지 않아서 그런지 LoRA 도 아직은 적게 나오고 있습니다. 하지만 앞으로는 달라질꺼라고 생각합니다. 하드웨어 요구사항에 비해, 이미지 퀄리티도 좋고 이미지 생성 속도도 빠르기 때문에 지금도 꽤 많은 곳에서 쓰기 시작하네요. 저도 바꿔볼까 생각중입니다.
Z-Image - Fast & Free Image Generator
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
구글의 차세대 TPUs (Tensor Processing Units) 인 Ironwood 가 주목받고는 있습니다.

구글의 Ironwood 클러스터의 일부
하지만 뭔가 관심이 너무 과한것 같아 글을 남겨봅니다.
TPU 라는건 딱히 신기할건 없습니다. nVidia 의 GPU 에도 TPU 와 유사한 Tensor Core 가 있기도 하구요. 필요한 데이터를 미리 연산 유닛에 전부 로드시켜 놓고 파이프 라인 및 연산 어레이를 통해 동시에 연산하는거니까요. 굉장히 빠른 연산이 가능하기 때문에 GPU 던 TPU 던 많은 곳에서 이런형태의 연산 유닛이 있습니다.

Ironwood 소켓의 영상. 수냉 쿨러가 인상적이다.
TPU 는 주로 AI 추론용 칩입니다. AI 학습에서도 사용 가능하지만 매우 제한적인 용도로만 사용할 수 있습니다. 물론 AI 학습보다 AI 추론에 사용될 GPU/TPU 가 훨씬 많아질거라, TPU 가 추론용이라고 폄하하는건 아닙니다. 특히 AI 서비스가 점점 많아지고 일상생활에서도 알게 모르게 AI 를 사용하려면, 이런 형태의 추론용 칩은 앞으로도 굉장히 많이 필요하게 될겁니다. 즉 학습용 칩보다 추론용 칩이 훨씬 많이 필요합니다.
Ironwood Chip Spec
- 4614 TFLOPS (FP8)
- Memory: 192 GB HBM, 7.37 TB/s
- Interconnect: 1.2 TBps
- 9216 개의 칩을 사용한 Pod Size 구성 가능

----
Ironwood: The first Google TPU for the age of inference
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
오랜만에 다나와 가서 메모리 가격을 살펴보고 있었는데, DDR4 가격이 그야말로 급 상승해버렸다. 32GB 에 19.9 만원. 메모리 가격이 오른다는건 알고 있었지만 이미 구시대의 메모리인데다 단종까지 된 제품인데 아직까지 수요가 있나보다.
기존 가격은 7 ~ 10만원으로 8만원 정도로 기억한다. 이 가격이 몇년동안 계속되었기 때문에 이 가격에서 단종 수순으로 갈걸로 생각했다.
원래 메모리 단종 직전엔 판매점 개수가 떨어지면서, 가격이 오르지만, 이번에는 판매점 수는 그대로다. 즉 재고가 있는 상황에서도 가격이 오른 셈이다. 메모리 재고가 소진되면 아예 안 팔 테니 사재기 하는 수요가 있다고는 들었지만 이정도라고는 생각하지 못했다.

2025.10.26 DDR4 메모리 가격 - 20만원
DDR5 에서는 그저 그렇지만, DDR4 는 삼성 제품만한게 없다. 삼성 제품의 2025.10.26 일자 가격 올려본다. 실제로 구매할 수 있는 가격은 위 가격에서 10% 정도 더 쳐줘야 한다. 32GB DDR4 메모리가 약 20만원이라는건 말 그대로 (일반인들은 살 수 없는) 최저가일 뿐이다.
요즘 이거 보면 뿌듯하다. 내가지금 100만원대 시스템을 사용하고 있는거니 말이다. (메모리 가격 오르기 전에는 40만원대)
적당한 시점에서 DDR5 으로 넘어가려 하는데 DDR5 가격도 만만하지 않아 고민이긴 하다.
재작년 12월부터 DDR4 메모리를 중고로 샀었다. 중고로 16GB 3만원, 32GB 6만원 안팍에 구매했는데, 이렇게라도 사 놓은게 다행이겠거니 하고 있다. 더 구매해야 하는데 지금은 너무 비싸져서 못 사고 있다. 중고가격도 예전에 매입가 생각나기 때문에 못 구매하겠다. 문제라면, 내년엔 더 오를 전망이라는 거다.
2023.12 Samsung DDR4 16G DDR4-2666V PC4-21300 x 2 구매
2024.04 Samsung DDR4 16G DDR4-2666V PC4-21300 x 2 구매
2024.08 Samsung DDR4 32G DDR4-3200AA PC4-25600 x 2 구매
2025.04 Samsung DDR4 32G DDR4-3200AA PC4-25600 x 4 구매
----
2025.11.08
더 올랐다. 32GB 24.7 만원. 오르는 속도가 솔찍히 무서울 정도. PC 구매를 포기해야할 수도 있겠다.

2025.11.08 DDR4 메모리 가격 - 25만원
----
2025.12.21
30만원. 2026년 상반기까지는 오를게 확실하고, 하반기까지도 유지될꺼라고 한다. DDR6 나올때쯤에나 정상화 될거라는 전망도 있다.

2025.12.21 DDR4 메모리 가격 - 30만원
이제 필자는 140만원대 PC 를 사용하고 있는 셈이다. 에혀.
----
2026.01.29
DDR4 32GB 40만원. 에혀. 3개월만에 신품 가격이 2배 올랐다. 지금은 DDR4 32GB 중고가격도 25 만원 정도로, 3개월 만에 3배 올랐다. 그나마 중고도 물량이 없어서 빠르게 신품 가격을 따라잡는 중이다.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음