라이저케이블을 사용해 VGA 를 수직 장착했다. 배송비 별도 4.95 만냥에 구매했다. 사용하고 있는 2060이 기가바이트 윈드포스라 바람이 그래픽 카드 위로도 나온다. 따라서 수평 장착시 케이스 측면을 향해 뜨거운 바람이 불게되고, 이때문에 뜨거운 바람이 다시 케이스 안으로 들어가게 된다. 여러모로 발열을 해결하는데 있어 문제가 되기 때문에 수직 장착으로 해결했다. 수직 장착하면 케이스 후면 팬으로 뜨거운 바람이 나가게 된다. 케이스 내부 온도는 쉽게 체감될 정도로 낮아졌고, 그래픽 카드 온도는 72 도 정도로 수직장착 전보다 3도 낮아진걸로 측정되긴 했지만 큰 차이 없는듯 하다.
라이저케이블을 사용해 그래픽 카드를 장착하게 되면, 그래픽 카드가 붕 뜨게 된다. 그냥 그래픽 카드가 떠있는 상태에서 그래픽 카드 받침대를 사용해 지지하고, 라이저케이블을 사용해 마더보드의 PCIe 16 포트와 그래픽 카드의 접속 단자를 연결해주는식으로 설치한다. 초기에는 PCIe 3.0 용 케이블만 판매했고 품질도 조악했었다고 하는데, 요즘 판매되는건 PCIe 4.0 용 케이블이고 속도저하도 없다고하며 무었보다 5만원정도로 저렴하게 구매할 수 있다.
필자의 경우도 다행이 성능 저하는 없는듯 하지만, 현재 사용하고 있는 마더보드는 PCIe 3 까지만 지원하는거라 PCIe 4 로는 확인 못했다.
L610 수직 장착
케이스에 따라 전용 라이저 장치를 달 수 있는경우도 있지만, 그렇게 하면 다른 확장포트를 전혀 쓰질 못하게 되어서 이런식으로 장착했다. 케이스에 수직으로 장착해 고정할 수 있는 확장 포트가 있고, 라이저케이블을 끼울 수 있을 정도의 공간이 있다면, 다른 케이스에도 장치하는건 어렵지 않을것 같다. 참고로 필자는 3RSYS L610 를 사용한다.
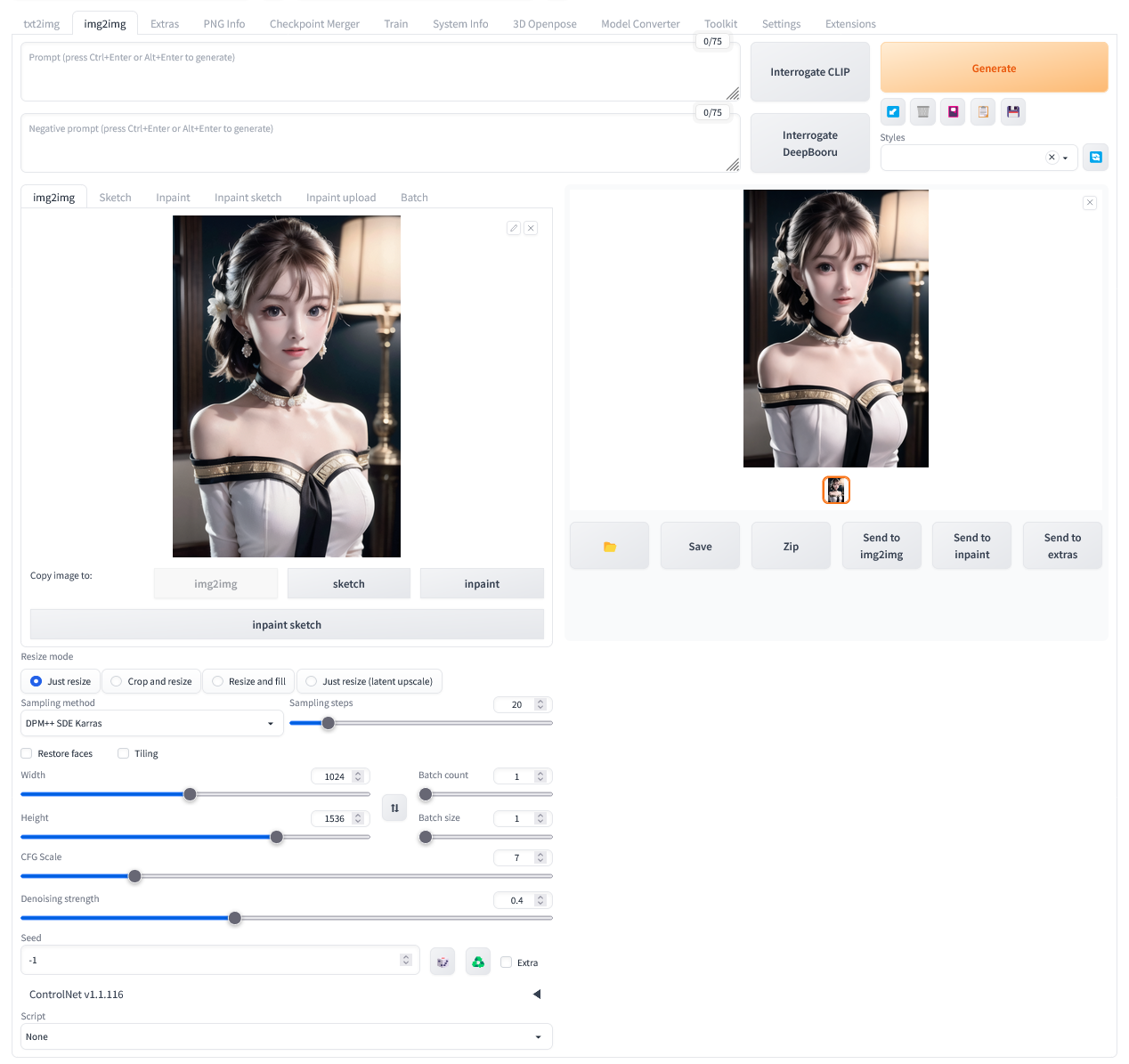
Stable Diffusion WebUI (이하 SD) 사용하다보면 같은 프롬프트를 주었는데도 유사한 이미지를 생성하지 못하는 경우가 꽤 자주 있다. 원인은 모르겠지만, 프롬프트 외에도, SD 실행시 옵션이나 설정이 달라지면 같은 프롬프트로도 완전히 다른 이미지가 생성되는것 같다.
재미있는건 이 현상이 이미지 업스케일링에서도 일어난다는 거다. txt2img 에서 hi.res fix 를 사용하거나, img2img 탭에서 업스케일링하는 경우에 업스케일링 전 이미지와 살짝 다른 이미지를 생성해 낸다. 그게 더 좋아보이기 때문에 사용하고 있다. 어쨌든 img2img 탭에서는 프롬프트를 입력하도록 되어있고 이 프롬프트를 업스케일링할때 사용한다.
이 문서에서는 프롬프트를 사용해 업스케일링 하는 방법을 이야기 한다. AI를 사용한 이미지 업스케일링은 Extra 탭에서 사용하고 추후 다룰 것이다.
※ 이미지 생성시에 사용한 프롬프트를 가지고 있지 않은 경우
img2img 탭에서 프롬프트 없이 실행.
프롬프트를 사용하지 않은 이미지 업스케일링
단, 단순 업 스케일링 하는 경우 PNG 파일에는 프롬프트가 남지 않는다. 프롬프트를 입력하지 않아도 업스케일 되기 떄문에, 필자는 입력하지 않는다. 또한 선명함이 조금 낮아진다. 그래도 프롬프트를 전혀 알 수 없을때 SD 를 사용해야할때 할 수 있는 방법이다. 추천하는 방법이 아니다. 프롬프트 없으면 Extra 탭 사용하자.
※ 이미지 생성시에 사용한 프롬프트를 가지고 있지만, txt2img 탭에서 프롬프트를 사용했을 때 같은 이미지가 생성되지 않는 경우
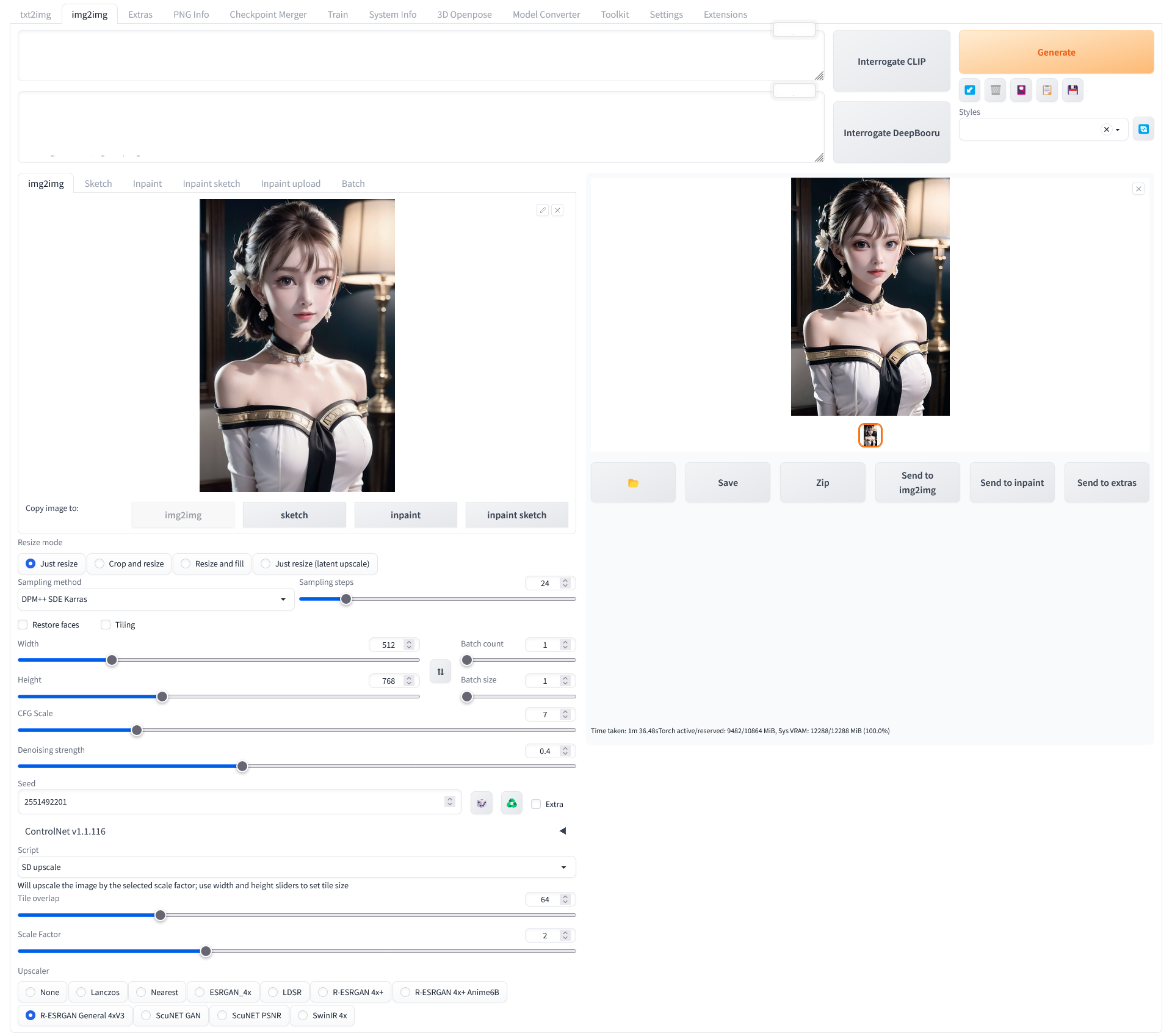
img2img 탭 하단의 Script 드롭박스에서 SD upscale 을 선택한 후 Upscaler 를 선택해 사용
원래는 다른 이미지를 얻기 위한 프롬프트인데, 시드를 높이면서 이미지를 생성하면 아래와 같이 입력한 프롬프트와 다른 이미지를 그려주기도 한다. 그런데, 이게 맘에 드는 경우가 있다. 뭔가 과하게 학습되었다고 생각되는데, 그게 나름 괜찮다. 다른 모델들 보다 animePastelDream 이 조금 심한것 같긴 하다. 아래는 그 사진들이다. 1920 x 1080 해상도로 업스케일 했다. 윈도 바탕화면 용이다.
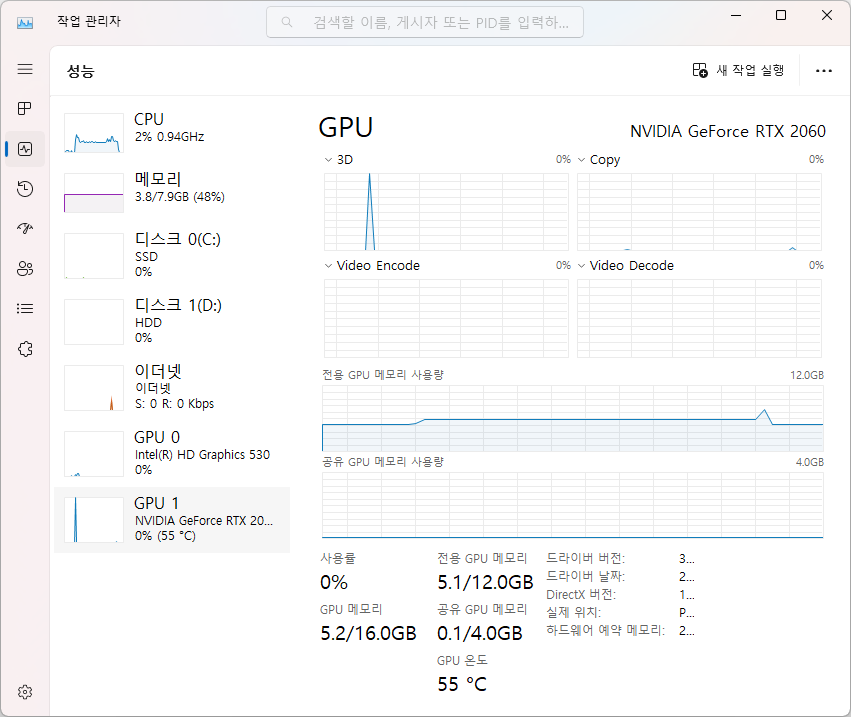
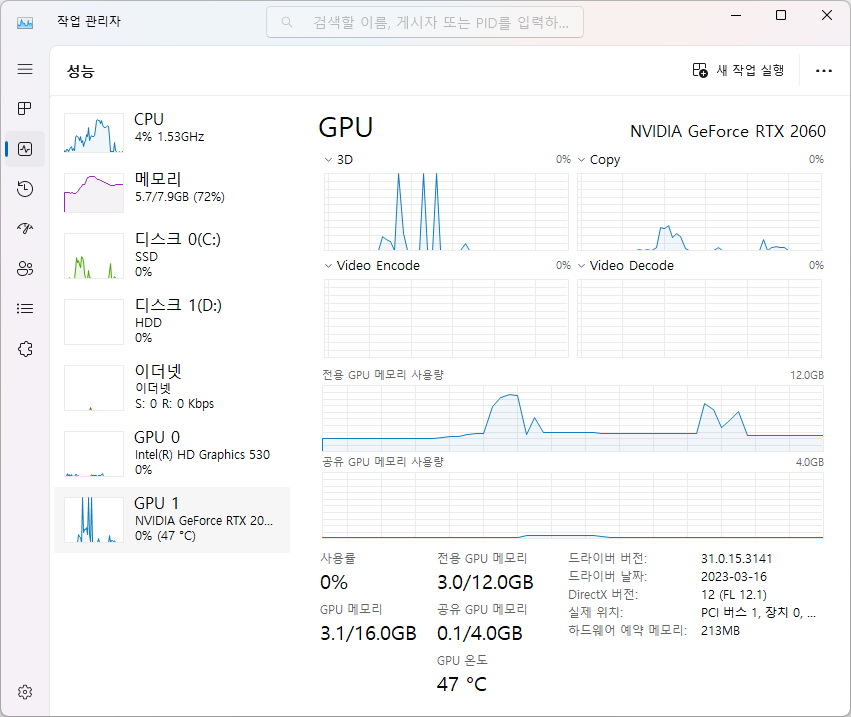
② 은 FP32로 학습한 체크포인트를 FP16 으로 수행하기 전에 FP16 으로 변환하는데, 처음 체크포인트 변환시 10.1G, VAE 변환시 8.9G 를 소비한다. 재 실행시에는 변환작업이 없다.
생성한 이미지
①
③
④
메모리 사용
①
②③
④
------------
참고: GT1030, --lowvram
이미지크기: 384 x 768
① FP16 체크포인트, FP32 실행 chilloutmix_NiPrunedFp16Fix FP32 1952MiB Total progress: 100%|██████████████████████████████████████████████████████████████████| 20/20 [08:10<00:00, 25.61s/it]
② FP16 체크포인트, FP16실행 chilloutmix_NiPrunedFp16Fix FP16 1350MiB Total progress: 100%|██████████████████████████████████████████████████████████████████| 20/20 [05:10<00:00, 16.15s/it]