- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
※ 여러가지 시행착오끝에 아래와 같은 512x768 이미지를 GT 1030 에서 2분대에 생성할 수 있도록 했다. 작년 이맘때 생성한게 10분 대였다는걸 감안하면 많은 발전이다. 그만큼 기술이 늘었다는 셈이다. 이 방법은 아마도 2G VRAM 을 가진 모든 nVidia 계열에서 사용할 수 있을거 같다.

※ 하는 방법을 적어 놓는다.
1. Ubuntu 22.04 를 설치하고 nVidia 그래픽 카드 드라이버를 설치한다. 이 글을 쓰는 시점에서 드라이버 버전은 550.67 이다. 윈도에서는 이 방법이 되지 않는다.
2. OS 가 띄워진 후에도 VRAM 2GB 를 온전히 비워질 수 있도록 한다. 필자의 경우 모니터 연결은 내장 그래픽을 사용했다.
3. Stable Diffusion WebUI 를 설치하고 실행한다. 옵션은 "--medvram --listen --xformers" 을 준다.
glibc version is 2.35
Check TCMalloc: libtcmalloc_minimal.so.4
libtcmalloc_minimal.so.4 is linked with libc.so,execute LD_PRELOAD=/lib/x86_64-linux-gnu/libtcmalloc_minimal.so.4
Python 3.10.12 (main, Nov 20 2023, 15:14:05) [GCC 11.4.0]
Version: v1.9.0
Commit hash: adadb4e3c7382bf3e4f7519126cd6c70f4f8557b
Launching Web UI with arguments: --medvram --listen --xformers
Loading weights [********] from Model.safetensors
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 7.1s (prepare environment: 1.4s, import torch: 2.4s, import gradio: 0.6s, setup paths: 1.2s, import ldm: 0.1s, initialize shared: 0.1s, other imports: 0.3s, list SD models: 0.1s, load scripts: 0.4s, create ui: 0.4s).
Creating model from config: /home/windy/stable-diffusion-webui/configs/v1-inference.yaml
Applying attention optimization: xformers... done.
Model loaded in 1.6s (load weights from disk: 0.5s, create model: 0.3s, apply weights to model: 0.5s, calculate empty prompt: 0.2s).
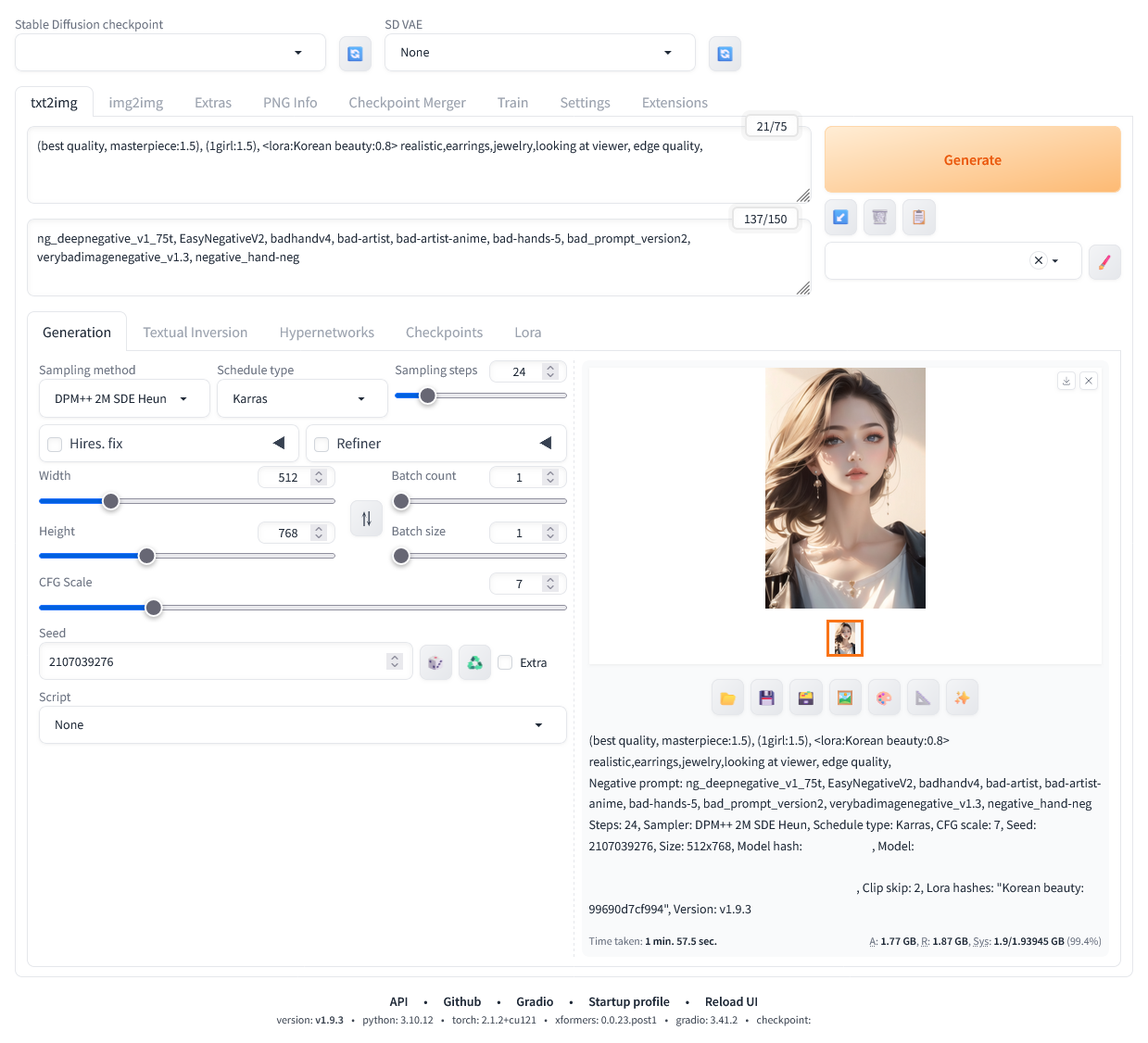
4. 이미지를 생성한다. 아래 화면 참조하자. 프롬프트는 75 토큰 이하, 네거티브 프롬프트가 반드시 75토큰이상 150토큰 이하이어야 한다. (왜그래야 하는지는 모르겠다)
4-1. 아래와 같이 화면에 표시된다.
100%|████████████████████████████████████████████████████████| 24/24 [02:33<00:00, 6.40s/it]
Total progress: 100%|██████████████████████████████████████████████| 24/24 [02:36<00:00, 6.54s/it]
Total progress: 100%|██████████████████████████████████████████████| 24/24 [02:36<00:00, 6.36s/it]
4-2. VRAM 사용량은 아래와 같다. 1952 MB 사용한다.
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.67 Driver Version: 550.67 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce GT 1030 Off | 00000000:01:00.0 Off | N/A |
| N/A 53C P0 N/A / 19W | 1955MiB / 2048MiB | 100% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 5895 C python3 1952MiB |
+-----------------------------------------------------------------------------------------+
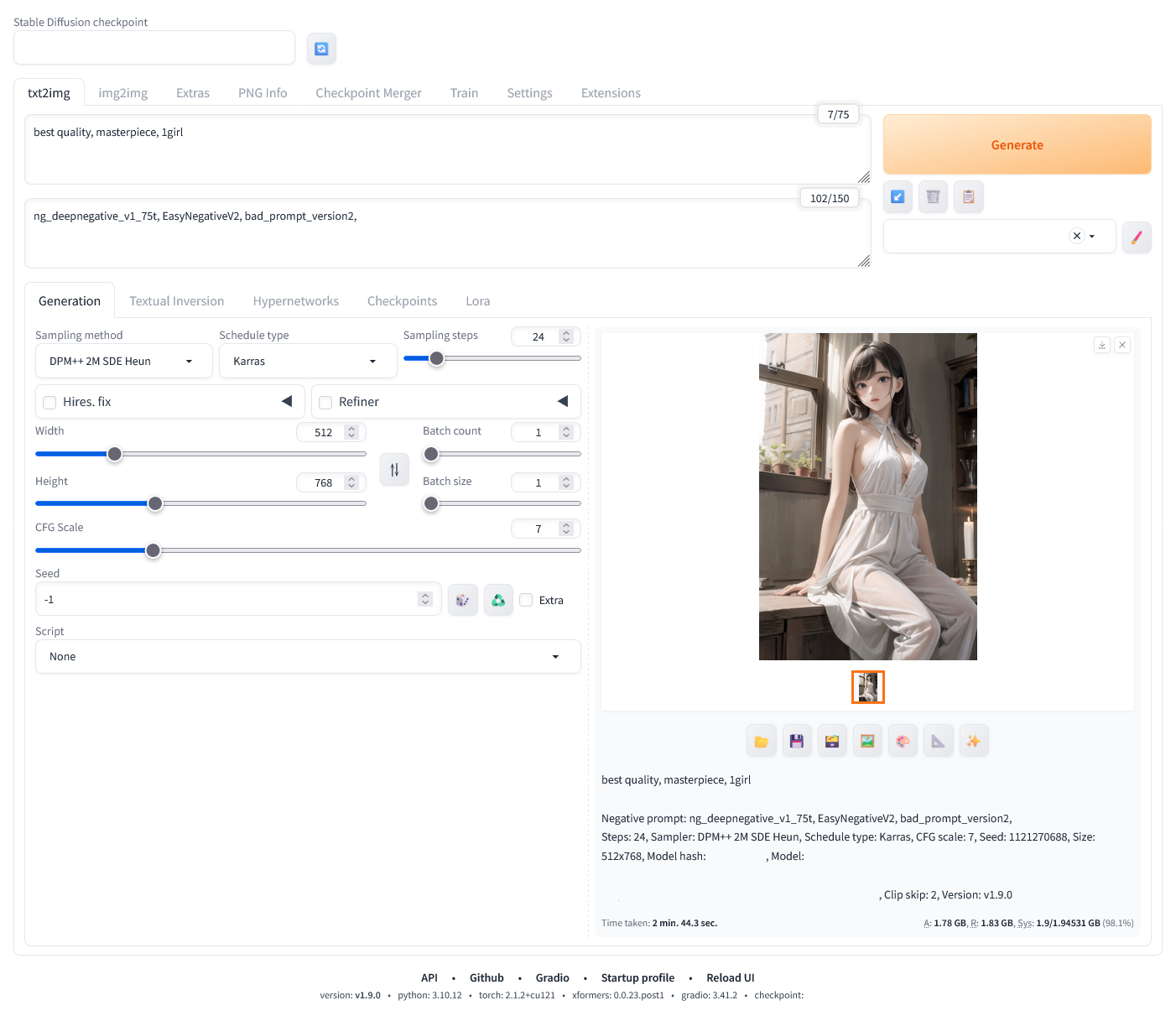
4-3. 생성 완료된 후 나오는 텍스트는 아래와 같다.
best quality, masterpiece, 1girl
Negative prompt: ng_deepnegative_v1_75t, EasyNegativeV2, bad_prompt_version2,
Steps: 24, Sampler: DPM++ 2M SDE Heun, Schedule type: Karras, CFG scale: 7, Seed: 1121270688, Size: 512x768, Model hash: ********, Model: Model, Clip skip: 2, Version: v1.9.0
Time taken: 2 min. 44.3 sec.
A: 1.78 GB, R: 1.83 GB, Sys: 1.9/1.94531 GB (98.1%)
5. 정말 아슬아슬하게 생성되는 셈이다. --lowvram 과 아닌건 성능 차이가 많기 때문에 필자는 이렇게 사용하고 있다.
----
2024.05.19 추가
- 이렇게 세팅하는 경우 LoRA 는 사용 가능하다.
- 배치는 사용할 수 없다. VRAM 이 몇십메가가 모자르기 때문에 사용이 안된다. 아깝다.
- Stable Diffusion WebUI Forge 라는 걸 사용하면 2GB 에서도 원활히 생성할 수 있다. 사용방법도 Stable Diffusion WebUI 와 비슷하다.
- 오늘 생성해보니 이유는 모르겠지만 시간이 줄었다. 2분이 안걸린다.
- torch: 2.1.2+cu121, xformers: 0.0.23.post1 을 사용해야 한다.