윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
154 개 검색됨 : 기술,IT/스테이블 디퓨전 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
그냥 습관적으로 이것 저것 생성하다가, 드레스를 입히면 괜찮을 것 같은 조합이 나왔다. 바로 실행해봤다. 나름 맘에 들어서 올려본다.

아래 사진이 가장 맘에 들었는데, 스케일 업 과정에서 손가락에 문제가 생겼다. 손가락 부분은 수정했다.




- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전





- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
근하신년 텍스트가 들어간 이미지를 만드려고 했지만, SDXL 기반에서는 텍스트는 그냥 안된다고 보는게 맞을거 같다. 그래서 그냥 없는걸로 만들었다. 마침 CivitAI 에 비슷한 이미지가 있길래 프롬프트를 기반으로 따라했다. 생각보다는 잘 나왔다.
만들고 난 후에 알았지만, 이거 기모노 기반이었다. 중국의상이 아니라 말이다. 끄긍.


- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
스테인드 글라스를 배경으로 만들어보았다. #4 와는 조금 다른 느낌. 역시 이런 복잡도 높은 이미지 생성할때에는 손가락이 가장 문제다.



- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
Wan 2.2 는 중국 알리바바그룹의 통이 연구소에서 개발한 시각모델이다. 2025.07.28에 공개되었다. 주로 동영상을 만들기 위해 사용한다. 오픈소스로 공개되어있다.
기존의 Wan 2.1 의 완성판이다. 이후에는 Wan 2.5 가 나올꺼고, 현재는 WAN 2.5 의 프리뷰버전까지 나왔다. 하지만 이제서야 2.2 를 써 본다.
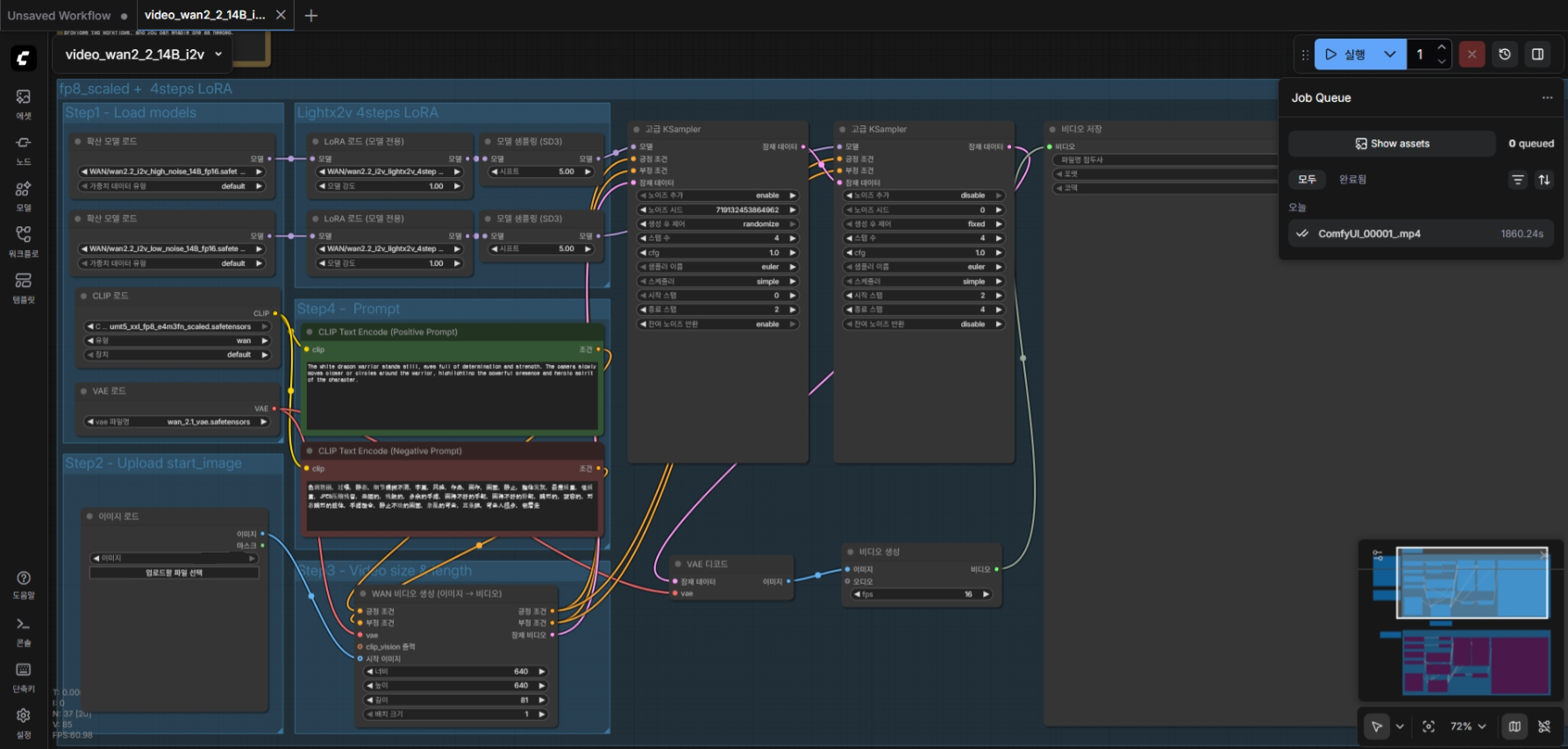
WAN 2.2 의 기본 워크플로. 2060 12G 에서 생성에 30분 걸렸다.
사용방법은 Wan 2.1 과 비슷하다. 모델만 2.2 로 바꿔주면 되는데, Wan 2.2 부터 I2V 에서 High - Low 모델이 분리되었다. High 모델은 구도 잡는데, Low 모델은 디테일을 높이는 데 사용한다. 따라서 동영상을 생성하기 위해서는 모델 2개를 순차적으로 돌려야 한다. 또한 모델 로딩에 필요한 메모리가 2배로 들어간다. 64GB 시스템 메모리에서 간신히 로딩된다. 128GB 는 필요하다. 벌써부터 64GB 메모리가 부족할 줄이야.

ComfyUI 0.4.0 + WAN 2.2 에서 I2V 실행후 남아있는 메모리 사용량. 스왑메모리 사용량을 감안하면 64GB 시스템에서 사실상 모자른 셈이다.
Lightx2v 에서 정제버전을 공개했다. 이를 사용하면 4 스텝으로도 충분한 품질을 얻을 수 있다고 한다. 20 스텝 -> 4 스텝 이니 5배나 빨라진 셈이다. 안쓸 이유가 없고 ComfyUI 문서에도 사용하라고 나온다.
RIFE VFI 프레임 보간을 사용해서 생성할 이미지의 FPS 를 올려주는 방법도 있다고 하는데 아직 적용은 못해봤다.
Wan2.2 Video Generation ComfyUI Official Native Workflow Example - ComfyUI
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전

- 16GB 메모리 를 가진 소비자용 GPU 에 최적화되어있는게 특징입니다. 파라메터 개수는 6B 입니다. 오픈소스이고, Apache-2.0 라이선스라 상업적으로 사용하는 것도 자유롭습니다. 또한 이미지 생성할 시, 9개 스탭 정도로도 충분한 이미지 퀄리티를 보여줍니다.
- 현재는 Python 코드로 사용하거나, ComfyUI 에서 사용 가능합니다.
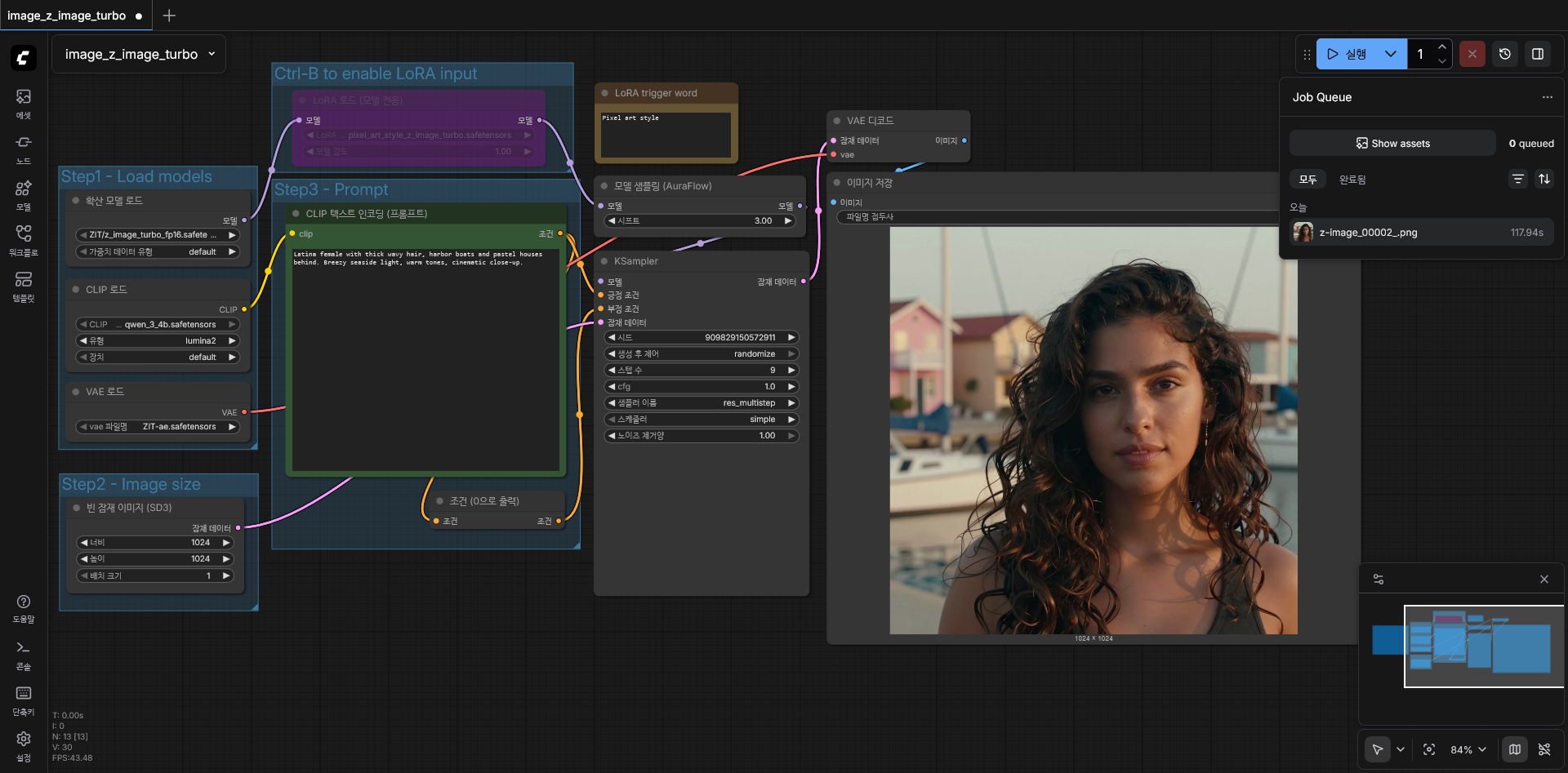
2060 12GB 에서 기본값으로 실행.
- 기본 워크플로를 사용해 생성했을때, 117.9초 소요됩니다. 1024x1024 이미지 임에도 불구하고 2060 에서는 꽤 느리기 때문에 당분간은 SDXL 을 사용할 수 밖에 없겠습니다. 조만간 5060 정도로 바꿀 지도 모르겠네요.
- 제가 가지고 있는 2060 12GB 에서 작동시키기 위해 FP16 버전을 사용했습니다. BF16 과 비교해서 성능에 큰 차이는 없습니다. (물론 그래도 할 수 있다면 BF16을 사용하는게 좋습니다) ComfyUI 실행시킬 때 "--use-sage-attention --force-fp16" 옵션을 추가로 주었고, "pip install sageattention" 명령을 주어 파이썬 패키지를 설치했습니다. sageattention 을 사용하기 위해 "apt install python3.12-dev" 패키지도 설치했죠. 최종적으로 27초로 단축되었네요.
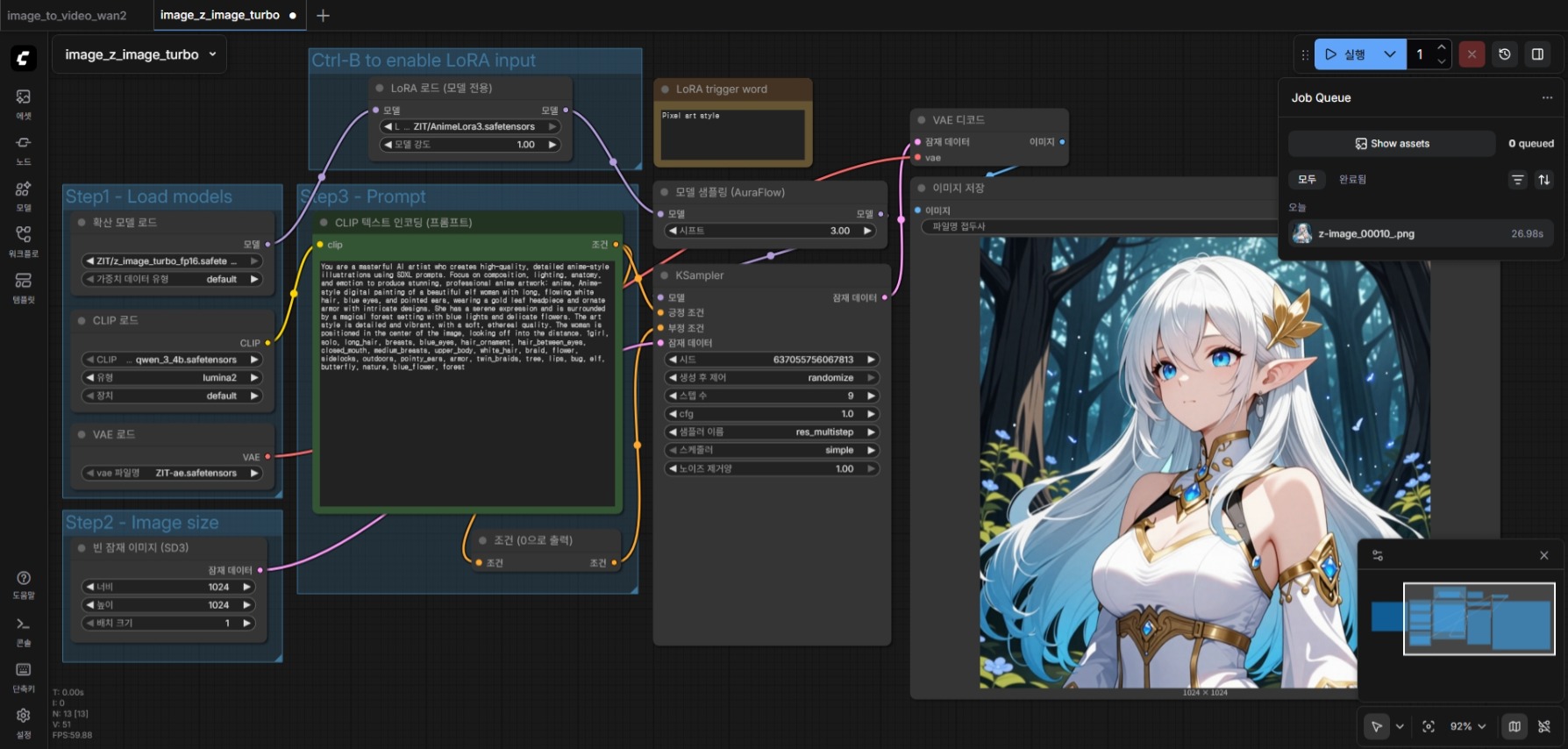
2060 12GB 에서 기본값으로 실행. 27초 소요.
- 아직 에니메이션 풍의 이미지는 생성하기 어려워 보입니다. 뭔가 실사판 이미지를 에니로 바꾼 느낌이네요. SDXL 에 비해 사용자가 많지 않아서 그런지 LoRA 도 아직은 적게 나오고 있습니다. 하지만 앞으로는 달라질꺼라고 생각합니다. 하드웨어 요구사항에 비해, 이미지 퀄리티도 좋고 이미지 생성 속도도 빠르기 때문에 지금도 꽤 많은 곳에서 쓰기 시작하네요. 저도 바꿔볼까 생각중입니다.
Z-Image - Fast & Free Image Generator
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전






- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
원래는 다른거 만들어보려 한건데 이런 이미지가 나와서 올려본다. 원래 만드려고 했던건 다음에 올릴 예정.
HIRES.fix 이전에는 손가락 5개라 잘 나온게, HIRES.fix 만 하면 6개가 되곤 한다. 그렇다고 안 쓸 수도 없고 말이다. 결국 편집툴을 사용해 한개를 지운다. 못 지우겠는건 그냥 안 올리고 말이다.
투톤 헤어는 잘 안만들었는데, 이번에 해보니 괜찮았다. 파란색-초록색 계열이 맘에 든다.





- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
황혼녁 배경과 함께 생성했다. 이쪽에 더 맘에 드는듯.




- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
대기실에 있는 신부가 혼자 있게 되는 경우는 드물지만, 몇년 전 잠깐 혼자있게된 신부가 고개를 숙이고 뭔가 깊게 생각하는걸 본적이 있는데 왠지모르게 기억에 남는다. 혼인을 하려니 뭔가 만감이 교차하게 되는거려나.



- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음