- [SSD는 빠르다는 장점이 있지만 비싸고, HDD는 느리지만 가격이 저렴하다]는 답변은 너무 안일한 답변이다. 그거 쓰려고 이런 제목 안달았다.
- 가격: SSD가 조금 더 비싼 정도가 아니다. SSD는 HDD에 비해 6배 정도 차이난다.
시게이트 Barracuda 7200.12 160GB (HDD) 4만
삼성 S470 128GB (SSD) 25만
시게이트 Barracuda XT 3TB (HDD) 25만
- 보안을 위해서라면 SSD에 AHCI사용하고 윈도7 사용해라. (TRIM 커맨드 사용을 위해. TRIM 커맨드는 성능 향상을 위해서 사용하는 거기도 하지만, 보안을 위해서도 사용한다) 이 상태에서 파일을 지우면 그 누가 와도 복구 못하니까 말이다. 보안을 따지면 HDD는 사용 해서는 안된다.
- 핸드헬드, 모바일 기기라면 당연히 SSD를 사용해야 한다. HDD는 헤드와 디스크가 있고 구동 부분이 있기 때문에 충격과 진동에 매우 취약하다. SSD도 충격과 진동에 취약한건 마찬가지지만 HDD보다는 훨씬 낳다.
- 그 외의 경우엔, SSD를 사용하면 좋지만, 그 정도 차액이라면 다른 부품에 투자하는게 좋지 않을까 생각한다.
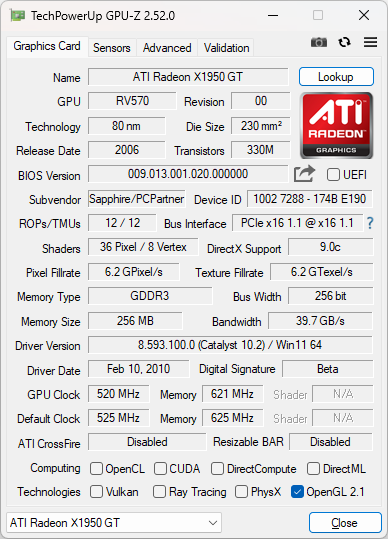
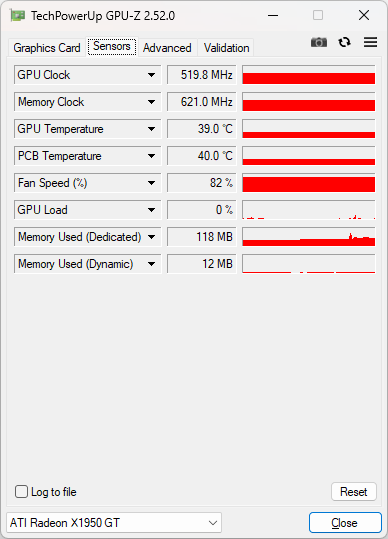
예전에 잠깐 사용하던 그래픽 카드. 버릴 생각을 하긴 했지만 왠지 2023년 현재 아직 까지 버리지 않고 있었다. 제품명은 "SAPPHIRE 라데온 X1950GT 오버에디션 256MB VF9" 으로 2007년 출시한 제품이다. 위 GPU-Z 정보는 표준 스펙이 아니라 오버된 스펙이다.
윈도 11에 설치해봤는데, 윈도 11을 공식적으로 지원하는 드라이버는 없지만, 그냥 윈도 VISTA 드라이버를 수동으로 설치해주었다. 화면 해상도는 정상적으로 나온다.
써멀 도포도 다시 했다. 실제로 사용하기는 어렵겠지만, 그냥 놔두기는 싫어서 말이다. 쿨러 분해해서 깨끗히 청소도 했다. 그러고 보니 한번도 청소해준적이 없었다.
지원하는 포트가 DVI x 2 에 SVGA 다. 2023년 요즘엔 사용하기는 어려운 셈. 게다가 추가 전원도 공급해줘야 한다.
이 카드와 경쟁했던게 nVidia 8600GT 다. 필자는 이걸 거의 사용안한 게, 이걸 구하고 나서 바로 거의 바로 HD 5500 을 구했던걸로 기억한다. 그래서 결과적으로는 거의 사용 못했다. 나름 아쉽다.
- PC-Fi, Hi-Fi 에서 주로 나오는 이야기. 기본적으로 좋아지긴 하는데, 어떤 케이블을 어떻게 바꿔야 하는지, 얼마나 좋아지는지는 안 나와 있는듯.
- 일단 음악 데이터는 실시간으로 전송된다. 그것이 SPDIF를 사용한 디지털 데이터 전송이든, RF단자를 사용한 아날로그 음성 신호이든 말이다. 여기서는 디지털 음성 전달만 다룬다. 일단 디지털 음악 데이터는 실시간 전송이며, 오류를 감지해도 '재전송'하지 않는다고 생각하자.
- (참고로 하드디스크에서 데이터를 읽어오는 경우, 오류를 감지하면 재시도하고 정확한 데이터로 재전송 한다)
- 재전송하지 않기 때문에, 디지털 음악 데이터 전송시 오류가 나지 않도록 하는게 중요하다. 일정 수준의 디지털 신호 노이즈는 데이터에 전혀 영향을 주지 않도록 설계되어있는데, 이 수준을 벗어나는 신호 잡음이 있는 경우에는 데이터가 변형되고 결과적으로 스피커로 나오는 소리에 노이즈가 발생한다 (그리고 결과적으로 음질이 떨어진다).
- 따라서 잡음이 심하게 끼어 디지털 데이터에 영향을 주는 품질이 낮은 케이블을 사용하고 있는 경우, 케이블을 잡음이 덜 끼는 좋은 것으로 교체하면 음질 향상을 얻을 수 있다. 케이블이 굵고 차폐실드가 있는 케이블이 이런 전송 오류가 적다.
카나레 디지털 오디오 케이블
- 단 노이즈가 심한 디지털 케이블은 스펙을 준수하지 않은 싸구려 케이블인 경우가 많다. 디지털 음성 전송을 위한 케이블 규격에 노이즈를 줄이기 위한 스펙이 감안되어있기 때문이다. 그런건 원래 사용하지 말았어야 하는 케이블이란 의미다. 왠만한 저가 디지털 케이블 이라도 노이즈와 관련해 문제 없다.
- 아날로그 케이블은 '스펙을 준수'한 케이블을 사용해야 한다. 또한 노이즈가 적도록 차폐가 잘 되어있고, 저항이 작은 케이블을 사용하면 기본적으로 음질이 더 좋아진다. 단 이는 앰프와 스피커의 스펙을 준수하는 범위내에서의 이야기다. (사람의 귀로 구분해 낼 수 있느냐 없느냐는 논외로 한다)
- 예를 들어 100원짜리 케이블과 10만원 짜리 디지털 케이블은 음질로 구분 할 수 있다. 100원 짜리 케이블은 스펙을 준수하지 못했을 테니깐. 하지만 몇만원짜리 괜찮은 케이블과 100만원짜리 초고급 케이블을 구분하는건 필자의 견해로는 불가능하다고 본다. 게다가 디지털 케이블이라면 신호 노이즈가 심한 싸구려 케이블이라도 데이터 전송에 오류가 없으면 동일한 값이기 때문에 구분이 불가능하다. 데이터가 '동일'하니깐 말이다.
∴ 아날로그 케이블이면 스펙(저항값) 준수한 적당히 굵은 케이블을 사고, 디지털 케이블이면 스펙을 준수한 오류가 나지 않는 선에서 저렴한 케이블을 살 것.
카나레 아나로그 인터커넥터
※ 은으로 만든 SATA케이블을 사용하면 음질이 좋아진다는 어이없는 글을 보고 쓴 글이다. 하드디스크와 마더보드를 이어주는 SATA 케이블은 데이터 전송 케이블이며, 오류 감지시 재전송 한다. 따라서 어떤 케이블을 사용하던 데이터가 오류없이 전송되었다면 데이터는 전혀 차이가 없다.
※ 예전에 마우스를 움직이면 스피커에서 지지직 하는 소리가 나는 경우를 경험해봤는데, 이건 마우스에서 신호 잡음을 마더보드로 전달하는 문제가 있고, 마더보드에도 마우스에서 전달된 신호 잡음을 제대로 걸러내지 못한 문제가 있으며, 마지막으로 사운드 카드에서도 제대로 전기적 노이즈를 걸러내지 못한 경우 이런 현상이 발생한다. 주로 접지를 공유한 경우에 흔히 발생한다. 3가지가 잘못되어야만 가능한 현상이라는 말이다. 요즘에는 마우스나 마더보드나 사운드 카드에서 잘 걸러준다. 이런 경우와 혼동된게 아닐까 생각한다.