윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
10 개 검색됨 : 2025/02 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
후면 이미지로도 생성해보았다. 오히려 뒷 모습을 그리는게 옷이 휘날리는 프롬프트에 더 부합하는 느낌이다.
실제 이런 옷을 볼 수는 없겠지만 언젠가 비슷한 거라도 있었으면 한다.






- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT
윈도 11을 사용하다 보면 키보드로 문자를 입력할 때 전각 문자로 변경되는 경우를 경험할 수 있다. 전각 문자란, 높이/너비가 같은 문자로, 이런 용어가 한자문화권에 있다. 바꿔말하면 영문자에 비해 폭이 두배 정도 되는 문자다.
※ 반각 문자
windy.luru.net
※ 전각문자
windy.luru.net
해결방법은 아래와 같다.
1. 아래한글을 사용하는 경우 IME 를 확인해보자. "한"을 클릭하면 자판배열을 변경할 수 있는 창이 나온다. "Microsoft 입력기"를 선택한다.
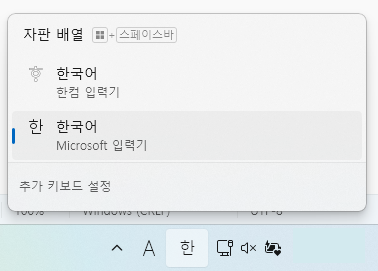
2. Microsoft 입력기인데도 전각으로 입력되면 Alt + = 를 눌러 전각/반각을 전환하면 된다.
윈도 오른쪽 아래의 "가" 또는 "A" 아이콘을 눌러 문자너비 → 반자를 선택하면 된다.
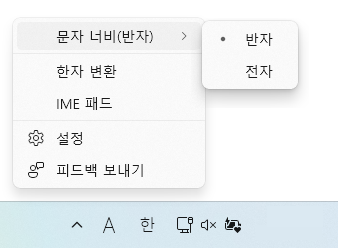
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/하드웨어 정보
3RSYS L600/L610 측면 스토리지 파트
예전에 구매한 3RSYS L610 Quiet (화이트) 케이스에 3.5인치 하드디스크를 추가 할 수 있는 부품을 주문했다. "측면 스토리지 파트"라고 부르는데 3RSYS 의 L600, L610 케이스에서 HDD 를 더 장착할 수 있도록 해주는 부품이다.
L610 케이스에 하드 디스크 장착하라고 되어있는, 케이스 하단에 있는 하드 디스크 장착 부품과 같은거다. 따라서 이 부품엔 2.5 인치 SSD도 장착 할 수 있다.
L610에는 총 4개의 파트를 추가할 수 있는데, 파트당 2개씩 HDD를 장착할 수 있다. 따라서 4개의 파트를 추가하게 되면, 원래있던 1개의 파트에 장착할 수 있는 2개의 HDD를 포함해, 총 10개의 HDD 를 장착할 수 있게 된다. 빅 타워 케이스를 제외하고는 이렇게 많은 HDD를 장착할 수 있는 케이스가 흔하진 않다.

스토리지 파트는 흰색과 검은색이 있는데, 흰색으로 주문했다. 케이스가 흰색이 더 많이 팔렸을 것이라 흰색 재고가 항상 별로 없다. 마침 4개 재고가 있길래 바로 주문했다. 개당 4000원이다.
HDD 를 4개 설치할 것이라 필요한 파트는 2개였지만, 막상 설치하고 보니 4개 주문하길 잘했다. 하나의 파트에 HDD를 2개 설치하기가 쉽지가 않다. 케이블간의 간격도 좁아져서 연결하기 힘들고, 케이스와도 간섭이 있는 경우가 있다. 그래서 그냥 파트마다 1개씩 넣어서 편하게 조립했다.

"측면 스토리지 파트"는 L610의 측면 패널에 다는 것이기 때문에, 측면 패널에 팬을 달 수 없다. 이부분은 아쉽긴 하다. 그래도 전면 흡기 팬으로부터 흡입한 바람을 스토리지 파트에 설치된 하드 디스크 냉각에 사용할 수 있는 구조라, 하드 디스크의 발열을 줄일 수 있어 좋다.
하드 디스크용 나사도 필요한 만큼 동봉되어있는데, 하드 디스크마다 6개씩 나사를 사용하지는 않아서, 나사에 제법 여유가 있다.
예전에 구매한 3RSYS L610 Quiet (화이트) 케이스에 3.5인치 하드디스크를 추가 할 수 있는 부품을 주문했다. "측면 스토리지 파트"라고 부르는데 3RSYS 의 L600, L610 케이스에서 HDD 를 더 장착할 수 있도록 해주는 부품이다.
L610 케이스에 하드 디스크 장착하라고 되어있는, 케이스 하단에 있는 하드 디스크 장착 부품과 같은거다. 따라서 이 부품엔 2.5 인치 SSD도 장착 할 수 있다.
L610에는 총 4개의 파트를 추가할 수 있는데, 파트당 2개씩 HDD를 장착할 수 있다. 따라서 4개의 파트를 추가하게 되면, 원래있던 1개의 파트에 장착할 수 있는 2개의 HDD를 포함해, 총 10개의 HDD 를 장착할 수 있게 된다. 빅 타워 케이스를 제외하고는 이렇게 많은 HDD를 장착할 수 있는 케이스가 흔하진 않다.
3RSYS L600/L610 측면 스토리지 파트
스토리지 파트는 흰색과 검은색이 있는데, 흰색으로 주문했다. 케이스가 흰색이 더 많이 팔렸을 것이라 흰색 재고가 항상 별로 없다. 마침 4개 재고가 있길래 바로 주문했다. 개당 4000원이다.
HDD 를 4개 설치할 것이라 필요한 파트는 2개였지만, 막상 설치하고 보니 4개 주문하길 잘했다. 하나의 파트에 HDD를 2개 설치하기가 쉽지가 않다. 케이블간의 간격도 좁아져서 연결하기 힘들고, 케이스와도 간섭이 있는 경우가 있다. 그래서 그냥 파트마다 1개씩 넣어서 편하게 조립했다.
"측면 스토리지 파트"는 L610의 측면 패널에 다는 것이기 때문에, 측면 패널에 팬을 달 수 없다. 이부분은 아쉽긴 하다. 그래도 전면 흡기 팬으로부터 흡입한 바람을 스토리지 파트에 설치된 하드 디스크 냉각에 사용할 수 있는 구조라, 하드 디스크의 발열을 줄일 수 있어 좋다.
하드 디스크용 나사도 필요한 만큼 동봉되어있는데, 하드 디스크마다 6개씩 나사를 사용하지는 않아서, 나사에 제법 여유가 있다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 시사,사회
우리나라 말로 번역할 때에는 주로 만수 무강 하시옵소서. 정도로 번역 된다. 원문은 "The Queen is dead, Long live the Queen!" 으로 전 왕이 죽었으니, 새 왕은 오래 살라는 의미.

몇일전 대통령제를 하는 국가에서 이 문구가 쓰였다고 합니다. 뭔가 새롭게 느겨지긴 하네요. 저쪽 불도 좀 큰거 같긴 합니다만, 우리 불 부터 꺼야 해서 남말 할 처지는 아니군요.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
원래 제품이 나오면 초반에는 이슈가 있곤 했습니다. 특히 GPU는 드라이버 이슈가 많았죠. 게다가 RTX 4090 나올 때에는 전원부가 타버리는 이슈가 있었습니다. 하지만 이번엔 전원부가 타버리는 것 외에도 조금 특이한게 더 있네요.

50xx 칩의 ROP 모듈이 스펙보다 적게 나온 경우가 있다고 합니다. 5090, 5080, 5070 전부 해당된다고 합니다. ROP 모듈이 적게 들어가면 게임할때 눈에 띄게 성능이 떨어집니다. 5% 정도 차이난다고 하네요. 어쨌든 스펙보다 잘못된거기 때문에 이런 제품은 교환해준다고 합니다.
ROP(Raster Operations Pipeline)는 GPU에서 픽셀의 색상을 처리하는 핵심 요소로, ROP의 개수는 성능에 직접적인 영향을 줍니다. 또한 GPU 에서 많은 메모리 대역이 필요한 요소이기도 하죠. ROP를 거친 데이터는 프레임 버퍼에 모이고 바로 모니터로 출력됩니다.
5090 5080 5070Ti 5070
ROP 176 112 96 64
비정상 ROP 168 104 88 -
불량품은 ROP가 8개 부족합니다. 이게 칩 제조단계에서 걸러지지 않았다는게 더 의아할 뿐입니다. 5070Ti 까지 발견되었으며, 5070 에서는 불량 보고가 없네요.
어차피 못 사는 제품이긴 하지만, 조금 아쉽네요. 현재 블랙웰 아키텍처를 사용한 GPU는 PCIe 를 사용한 제품이 50 시리즈 밖에 없습니다. 예전에 썼던 GB200 은 플랫폼으로 판매하는 거라 PCIe 를 사용하지 않습니다. 즉 데이터센터에서 사용할 수 있는 PCIe 제품은 H100 까지입니다. 블랙웰은 발열이 많아서 공랭으로는 어렵다고 하네요. 반드시 수랭을 써야 한다는거 같네요. 에혀.
이번 5090 도 기존보다 발열은 제법 있습니다. 그냥 성능 향상분 만큼의 발열이 있다고 생각하면 쉬울거 같네요.
어서 안정화 되고 어서 32 GB 이상 메모리를 가진 저렴한 모델이 나왔으면 좋겠네요. 그래야 업스케일 없이 4K 이미지를 만들 수 있을 것 같네요.
----
2025.04.01 추가
5090 에 ROP 가 스펙보다 16개 더 들어간 192개의 ROP 가 있는 제품이 발견되었다네요. 192개의 ROP 는 GB202 칩의 풀스펙입니다. 위에도 나와있듯 ROP 는 성능에 직접적인 영향을 줍니다. 벤치해보면 게임에서 8% 나 더 빠르다네요. 이정도면 Ti 급이나 Super 급입니다. 불량이니 교환하라고 하겠지만 글쎄요, 이거 교환할 사람이 있을까요.
예전에 3060 중에서 GA104 를 사용해 ROP 가 더 높은경우가 있었죠. 3060 의 인기가 한풀 꺽였을때 나온거라 조용했지만 말이죠. 당시 이론상 픽셀레이트가 85.30 → 113.7 GPixel/s 으로 상승하긴 했지만, 실제 게임에서 이점은 별로 없었습니다. 메모리 대역폭은 그대로라 여기서 병목이 발생했기 때문입니다. 이번 5090 에서는 성능향상이 있었다는건 5090 이 메모리 대역폭에 꽤 여유가 있는걸로 생각되네요.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
요즘 주로 사용하고 있는 이미지 편집 프로그램이다. 블로그에 AI 로 생성한 그림을 올릴때에도 크롭하거나, 픽셀 한두개 고치는건 이걸 사용해 하고 있다. 포토샵보다야 기능상 떨어지겠지만, 이런 간단한 작업 하기에는 손색 없는 프로그램이다.
공식 홈페이지에서 받는 것 보다, GITHUB 에서 받는걸 추천한다. 여기에는 포터블 버전도 있다. 현재 포터블 버전은 약 127MB 정도 된다.
다운로드 하기: https://github.com/paintdotnet/release/releases
포터블 파일을 다운로드 했으면, 압축을 풀고 paintdotnet.exe 파일을 실행시킨다. 사용 방법은 포토샵과 비슷하다.
공식 홈페이지에 가면 플러그인도 많다. 꽤 오래된 프로그램이기 때문에, 사용자 층도 제법 있다. 앞으로도 자주 애용할것 같다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SDXL 에서는 FP8 를 사용않고 있었다. SDUI 에서도 FP8 이 기본적으로 활성화 되지 않는다. 문득 조금 이상하다는 생각이 들어 찾아봤다.
- 우선 SDUI 에서는 Optimizations 항목에 FP8 관련 설정이 아래와 같이 2개 있다.
① FP8 weight (Use FP8 to store Linear/Conv layers' weight. Require pytorch>=2.1.0.)
◎ Disable ◎ Enable for SDXL ◎ Enable
② Cache FP16 weight for LoRA (Cache fp16 weight when enabling FP8, will increase the quality of LoRA. Use more system ram.)
- ① 을 활성화하면 기본적으로 FP8 을 사용하게 된다. 실제로 해보면 성능 향상(이미지 생성속도)이 없다. 단 메모리는 FP8을 사용하는 만큼 적게 사용한다. FP8을 활성화 하는 경우 일부 LoRA 를 사용할 수 없다. 왜인지는 모르겠지만 오류 발생한다.
- SDXL 메모리 사용량
FP8: 3.80 GB
FP16: 5.23 GB

SDXL FP16

SDXL FP8
주) VAE 는 동일하게 FP32 사용한다.
- ②는 캐시관련된거라 성능에 관련이 없다.
- 결론적으로 써도 성능 향상이 없고, LoRA 호환성만 떨어뜨리기 때문에 사용 안하는 거다. 결과물도 다르다. (단 FP16이 항상 더 좋은 결과를 내주는건 아니다) FLUX.1 dev 는 FP8 을 쓰면 효과가 상당히 좋은데 (이미지 생성속도가 빨라지는데) 유독 SDXL 에서는 효과가 없다.
- 아래는 같은 프롬프트, 같은 파라메터를 사용해서 만든 이미지다. 어떤게 좋다고는 할 수 없지만 왠지 FP16 이 더 빛나 보인다.

FP8 으로 생성한 이미지

FP16으로 생성한 이미지
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
바람에 휘날리는 드레스와 노을은 언제나 예쁘다. 생각날때마다 만드는데, 이번에도 한번 올려본다. 해상도가 4000 x 2400 이기 때문에, 4k 화면에서도 잘 보일 것이다.





- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 문화,취미
딥 시크 R1 을 Python vLLM 을 사용해 로컬에서 실행해 보았다. DeepSeek-R1-Distill-Qwen-1.5B 모델을 사용했는데, 이 모델은 DeepSeek R1 에서 Distill 된 모델중 가장 작은 모델로, 수학 모델이다. 한글을 잘 인식하질 못해서 영어로 질문했다. 인터넷에서 영문 수학 문제를 검색해 문의해보았다.
인터넷을 찾아보면 한글 지원하는 모델도 쉽게 구할 수 있고, 7B 모델만 되어도 한글 잘 인식한다고 한다. 하지만 필자의 사양에서는 못 돌린다. 그래서 INT8 으로 양자화된 모델을 찾고 있기도 하다.
서버 사양은 Ubuntu 22.04, i7-7700K, 32GB, RTX 2060 12G 이다. 아래와 같이 실행했다.
$ mkdir DeepSeek-R1-Distill-Qwen-1.5B
$ cd DeepSeek-R1-Distill-Qwen-1.5B
$ python3 -m venv venv
$ . venv/bin/activate
(venv) $ pip install vllm
(venv) $ vi run.py
from vllm import LLM, SamplingParams
llm = LLM(
model="deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B",
dtype="half",
max_model_len=8_000
)
sampling_params = SamplingParams(
temperature=0.5,
max_tokens=8_000
)
prompts = [
"""The day before yesterday I was 25. The next year I will be 28. This is true only one day in a year. What day is my Birthday?"""
]
conversations = [
[{"role": "user", "content": x}] for x in prompts
]
outputs = llm.chat(conversations, sampling_params=sampling_params)
for output in outputs:
print(output.outputs[0].text)
(venv) $ python run.py
실행 결과는 아래와 같다. 보기좋게 편집되어있다. 질문은 생일을 맞추는 문제인데, "2일 전에는 25살, 내년에는 28살"일 때 생일을 묻는 문제로, 생일은 12월 31일이다. 정확하게 맞췄다. 약 25초 정도 걸렸다. VRAM 사용량은 약 9.5GB 정도 된다. (nvidia-smi 으로 측정)
(venv) $ python run.py
INFO 02-00 18:51:00 __init__.py:183] Automatically detected platform cuda.
WARNING 02-00 18:51:02 config.py:2368] Casting torch.bfloat16 to torch.float16.
INFO 02-00 18:51:07 config.py:526] This model supports multiple tasks: ...
INFO 02-00 18:51:07 llm_engine.py:232] Initializing a V0 LLM engine (v0.7.1) ...
INFO 02-00 18:51:08 cuda.py:184] Cannot use FlashAttention-2 backend for Volta and Turing GPUs.
INFO 02-00 18:51:08 cuda.py:232] Using XFormers backend.
INFO 02-00 18:51:09 model_runner.py:1111] Starting to load model
deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B...
INFO 02-00 18:51:09 weight_utils.py:251] Using model weights format ['*.safetensors']
INFO 02-00 18:51:10 weight_utils.py:296] No model.safetensors.index.json found in remote.
Loading safetensors checkpoint shards: 0% Completed | 0/1 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 1.06it/s]
Loading safetensors checkpoint shards: 100% Completed | 1/1 [00:00<00:00, 1.06it/s]
INFO 02-00 18:51:11 model_runner.py:1116] Loading model weights took 3.3460 GB
INFO 02-00 18:51:12 worker.py:266] Memory profiling takes 1.05 seconds
INFO 02-00 18:51:12 worker.py:266] the current vLLM instance can use
total_gpu_memory (11.55GiB) x gpu_memory_utilization (0.90) = 10.40GiB
INFO 02-00 18:51:12 worker.py:266] model weights take 3.35GiB;
non_torch_memory takes 0.04GiB; PyTorch activation peak memory takes 1.41GiB;
the rest of the memory reserved for KV Cache is 5.60GiB.
INFO 02-00 18:51:12 executor_base.py:108] # CUDA blocks: 13097, # CPU blocks: 9362
INFO 02-00 18:51:12 executor_base.py:113] Maximum concurrency for 8000 tokens per request: 26.19x
INFO 02-00 18:51:14 model_runner.py:1435] Capturing cudagraphs for decoding.
This may lead to unexpected consequences if the model is not static.
To run the model in eager mode, set 'enforce_eager=True' or use '--enforce-eager' in the CLI.
If out-of-memory error occurs during cudagraph capture,
consider decreasing `gpu_memory_utilization` or switching to eager mode.
You can also reduce the `max_num_seqs` as needed to decrease memory usage.
Capturing CUDA graph shapes: 100%|█████████████| 35/35 [00:09<00:00, 3.63it/s]
INFO 02-00 18:51:24 model_runner.py:1563] Graph capturing finished in 10 secs, took 0.19 GiB
INFO 02-00 18:51:24 llm_engine.py:429] init engine (profile, create kv cache, warmup model)
took 13.48 seconds
INFO 02-00 18:51:24 chat_utils.py:330] Detected the chat template content format to be 'string'.
You can set `--chat-template-content-format` to override this.
Processed prompts: 100%|███████████████████████
[00:04<00:00, 4.14s/it, est. speed input: 9.66 toks/s, output: 81.16 toks/s]
<think>
To determine the day of the birthday, I start by analyzing the information given.
First, it's stated that the day before yesterday, the person was 25.
This means that yesterday was the birthday day, and today is the day after birthday.
Next, it's mentioned that the next year, the person will be 28.
This implies that the current age is 25 plus 1, which is 26.
Since the person will be 28 in the next year, their birthday must be on December 31st.
This is because the next year's birthday will occur on the same date,
and the age will increase by one year.
Therefore, the birthday is December 31st.
</think>
To determine the day of your birthday, let's analyze the information step by step:
1. **Day Before Yesterday:**
- You were **25** years old the day before yesterday.
- This means **yesterday** was your birthday day.
2. **Next Year:**
- You will be **28** years old in the next year.
- If you are currently 26 years old, your birthday will be on **December 31st** because:
- **Today** is **December 31st**.
- **Tomorrow** will be **January 1st**, and you'll turn **27**.
- **Next Year** (two years from now) you'll be **28** years old.
**Conclusion:**
Your birthday is on **\boxed{December 31st}**.
Think 태그에 보면 사고의 흐름을 볼 수 있다. 이런게 나오긴 한다 정도로 생각하면 된다. 정답은 맞췄지만 논리적 사고를 한다기 보다는 문장의 흐름, 패턴을 검색해 유추한다고 생각한다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/하드웨어 정보

2008년 5월경 구매한 기가비트 8포트 스위치. 굉장히 오래된 제품이지만 아직까지도 가지고 있다. 잘 작동하기도 하고 말이다.
※ 스펙
칩셋: BCM5398, MNC G4802CG, MNC G4802SG
표준: 10BASE-T/100BASE-TX/1000BASE -T
포트: 10/100/1,000Mbps 8포트, Auto MDI/MDIX
전송방식: Fast store-and-foward
MAC 테이블/학습방법: 8k / 자Self-learning, Auto-Aging
패킷필터링/포워딩: 포트당 14880/148800/1488000pps
전원: DC 9V, 1.2A
크기: 105(W) x 80(D) x 26(H)mm
출시가격: 4.6 만원
케이스가 철제 프레임으로 되어있어서 방열에 좋은 편이다. 생각보다는 작은 크기다.

번들해주는 어댑터가 리니어 방식이라 크고 무겁다. (그만큼 리니어 방식 어댑터가 비싸다. 저렴한게 아니라서 좋다)
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음