윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
153 개 검색됨 : 기술,IT/스테이블 디퓨전 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
미소녀 만화 그림체의 LoRA 를 받아 생성한 그림이다. 미소녀 만화 그림체로 그려주는 LoRA 는 많지만 내가 사용하는 모델에 잘 어울리는 LoRA 는 찾기 힘들다. 사진에 사용한 LoRA 도, LoRA 소개 이미지는 아래 그림과 딴판이었다. 즉 이런 LoRA 를 발견한건 상당한 운이 있었던 셈.
LoRA 가 학습을 강하게 했는지, 다른 형태의 이미지를 생성할 수는 있지만, 프롬프트를 많이 바꾸지 않으면 유사한 이미지들이 많이 나온다. 이것저것 해보다가 아래와 같은 형식이 가장 예쁘게 나왔다. 뭔가 귀족풍의 아가씨를 만드려고 하는 내 의지와 맞았다.
이 글은 Part 3까지 업로드 예정이다.







- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
리본 형태의 나비넥타이. 의외로 자주 보는 넥타이 형식인데, 이 형태가 SD 에서는 나오질 않았다. 나왔다 해도 조금 이상하게 나오기도 했다.
그래서 LoRA 를 만들어서 구현해 봤다. 인터넷에서 유사한 이미지들을 찾고 그림판에 붙이고 자르고 그려 넣어서 그럴듯한 이미지를 만들고, 이 이미지로 LoRA 를 만든다. LoRA 를 사용해 다시 이미지를 만들고 다시 학습시켜서 LoRA 만들고. 이걸 반복하다 보면 만족할만한 품질의 LoRA 가 나온다.
대략 모양이 나오게 만들었으면 이후 디테일을 높이고 이것저것 장식을 만들면 완성. 말이 쉽지 약 52시간 정도 걸렸다. 일주일 정도 걸린 셈. 그렇게 해서 나온게 아래 이미지들이다.



만들고 나니 뿌듯하다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SDXL 은 다양한 해상도를 가진 이미지로 학습되어있는데, 이 해상도의 기준이 1024 x 1024 이다. 또한 내부적으로 64px 의 디멘션을 사용하기 때문에, 해상도는 64의 배수가 되어야 한다.
학습한 해상도인 1024 x 1024 가 가장 좋고, 512 ~ 1536 사이의 값으로 64 의 배수값으로 사용한다. 전체 픽셀수는 1.04M (1,090,519) 을 넘어서는 안된다.
보통 이미지는 아래 해상도로 생성하면 된다.
해상도 픽셀수 비율
---------- --------- -------------
1344 x 768 1,032,192 1.75:1 16:9
1216 x 832 1,011,712 1.46:1 3:2
1152 x 896 1,032,192 1.28:1 4:3
1024 x 1024 1,048,576 1.00:1 1:1
1536 x 640 983,040 2.40:1 2.39:1
가로/세로를 바꿔서 생성해도 된다. 비율은 16:9 비율이 약 1.77:1 비율임을 생각하면 된다. 참고로 2.39:1 은 시네마스코프 비율이다.
필자의 경우 768 x 1344 를 선호한다. 16:9 에 가장 가깝기 때문에 그렇다. 두번째로는 832 x 1216 을 사용한다. 대략 3:2 비율이기 때문이다.
SDXL 은 생성할 이미지의 비율에 따라 이미지의 구도가 달라지기 때문에, 생성해보다가 구도가 맞지 않으면 다른 걸 사용해도 된다.
아래 이미지를 보자.

1536 x 640

1344 x 768

1216 x 832

1152 x 896

1024 x 1024
모두 동일한 프롬프트와 시드에서, 해상도만 변경해서 생성한 이미지다. 머리 모양과 흩날리는 정도가 이미지 비율에 따라 변경되는걸 볼 수 있다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SDXL 에서 VAE 는 FP32 으로 사용하곤 한다. FP16 으로 된 VAE 라도, FP32 으로 변환해서 사용한다. 이렇게 하는 이유가 SDXL 의 경우 VAE 를 사용해 이미지를 변환할 때, NaN 오류가 많이 발생하기 때문이다.
- 그래서 필자도 Stable Diffusion webUI (SDUI) 에서 --no-half-vae 옵션을 주어 사용했다. 이렇게 하면 NaN 이 발생하지 않아 이미지가 검게 생성되는 현상을 없앨 수 있었다. 반대로 이 옵션을 주지 않으면, 매우 자주 발생한다.
여태까지 --no-half-vae 옵션을 주면서 사용하다가, 최근에 이에 대한 패치가 나온걸 알 았다. VAE 에 대한 FP16 FIX 이다. SDXL-VAE-FP16-Fix 에 나와있는
https://huggingface.co/madebyollin/sdxl-vae-fp16-fix/resolve/main/sdxl.vae.safetensors
을 다운로드 받아 사용하면 된다.
- VAE를 받아 SDUI 의 VAE 디렉토리에 넣고 이 VAE 를 사용하도록 세팅한다. 그리고 --no-half-vae 옵션을 사용하고 SDUI 를 실행해보면, 이미지 생성시 아래와 같이 메모리 사용량이 줄어드는걸 볼 수 있다.

SDXL 에서 FP16 VAE 으로 세팅하고 이미지를 생성시 전용 GPU 메모리 사용량

SDXL 에서 FP32 VAE 으로 세팅하고 이미지를 생성시 전용 GPU 메모리 사용량
FP32 VAE 사용시 마지막 단계에서 FP32 VAE 를 사용하기 위해 메모리 사용량이 급격히 (2배) 늘어나는걸 볼 수 있다. 이미지 품질에는 영향이 없기 때문에 FP16을 사용할 수 있으면 사용해야 한다.
- 시간과 메모리 사용량은 아래와 같이 비교된다.
FP32 VAE: 생성시간 4 min. 18.3 sec. A: 8.37 GB, R: 26.08 GB, Sys: 16.0/15.9961 GB (100.0%)
FP16 VAE: 생성시간 3 min. 49.4 sec. A: 5.22 GB, R: 9.99 GB, Sys: 11.2/15.9961 GB (69.8%)
- 또한 HiResFix 나 Upscale 작업시에는 VRAM 이 부족한 경우가 많다. 부족한 경우 Tiled VAE 를 사용할 수도 있지만, FP16을 사용할 수도 있을것 같다. 아니면 두가지 모두 사용하거나 말이다.
- FP16 VAE 를 사용해서 문제가 생기면(검은색 이미지가 생성되면) SDUI 의 아래 옵션을 체크해보자. NaN 이 발생하는 경우 자동으로 BF16이나 FP16으로 변환해 사용한다. BF16 을 사용하는 경우 GPU 에서 지원하는지 반드시 확인해야 한다. 잘 모르겟으면 해제하면 된다.
☑ Automatically convert VAE to bfloat16 ☑ Automatically revert VAE to 32-bit floats
- FP16 VAE 설명을 보면, NaN 이 자주 발생하는건 일부 활성화 값이 너무 크기 때문이라고 한다. 이 값을 조절하기 위해 몇가지 작업을 했다고 한다.

활성화 값이 큰 예시
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
요즘엔 4K 이미지에 대한 목표가 없어졌다. 예전엔 그렇게도 생성하고 싶었었는데, 막상 할 수 있게 되고보니 그다지 갈망하지는 않는거 같다.
좀 다른 방법을 소개한다. Tiled Diffusion 플러그인을 사용하는 방법이다. 하는 방법은 아래와 같다.
1. SDUI 에서 Extensions 탭으로 간 후, TiledDiffusion with Tiled VAE manipulations 을 설치한다.
2. txt2img 탭으로 가서 이미지를 생성하기 위한 설정(프롬프트)을 하고, Hires Fix 를 선택한다. 최종 해상도가 4K 이상이 되도록 배율을 선택한다.
3. Tiled VAE 를 선택한다. 최소한 아래와 같은 설정이 필요하고 나머지 2개도 필요하면 체크해준다.
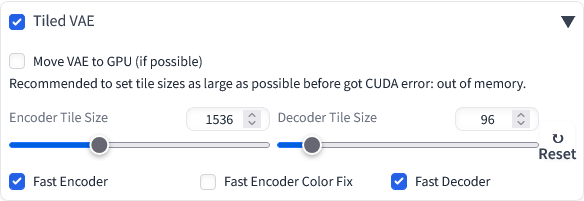
Encoder/Decoder Tile Size 는 가급적 크게 주는게 좋은데, 너무 크게 주면 CUDA error: out of memory 오류가 발생한다. 적당히 크게 세팅하자. 16GB VRAM 의 경우 1536, 96 으로 세팅한다. 8GB VRAM 의 경우 1024, 64 정도면 될것이다. 그 이하의 VRAM 을 사용하면 더 낮게 세팅해도 된다. 최소값은 256, 48 이다.
4. 생성을 눌러 이미지를 생성하자.
콘솔을 보면 아래와 같이 생성되는걸 확인해볼 수 있다.
100%|████████████████████████████████████████| 38/38 [02:51<00:00, 4.52s/it]
100%|████████████████████████████████████████| 76/76 [03:32<00:00, 3.83s/it]
[Tiled VAE]: input_size: torch.Size([1, 4, 320, 192]), tile_size: 96, padding: 11
[Tiled VAE]: split to 4x2 = 8 tiles. Optimal tile size 96x96, original tile size 96x96
[Tiled VAE]: Fast mode enabled, estimating group norm parameters on 57 x 96 image
[Tiled VAE]: Executing Decoder Task Queue: 100%|███████████| 984/984 [00:04<00:00, 213.04it/s]
[Tiled VAE]: Done in 5.675s, max VRAM alloc 3613.766 MB
Total progress: 100%|██████████████████████████████| 76/76 [03:41<00:00, 2.92s/it]
Tiled VAE 사용하지 않은 이미지와 사용한 이미지와는 차이나지 않는다.
VRAM 이 부족하지 않아도 이미지 생성시 GPU가 공유 메모리도 사용하고 있다면 Tiled VAE 를 사용해볼만 하다. 상당히 빨라진다. 필자의 경우 4:59 소요되던 스케일링 작업이 Tiled VAE 를 사용하면 3:45 정도 소요된다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
3.1 절이기도 해서 한복 비슷한 그림으로 그려보았다. 요맘때랑 광복절때 한복을 그려야 겠다는 생각을 한다.
현재 AI 에서는 우리나라 전통 한복을 완전하게 그리지는 못한다. (아마 앞으로도 완전하게는 못그릴거 같다) 특히 옷 매듭이 어렵고, 윗 저고리도 한복처럼 잘 안나온다. 어딘가 일본의 기모노와 중국의 한푸, 치파오가 섞여있는 느낌이다.
생성한 것 중 그나마 비슷하다고 생각되는 걸로 골라 올린다. 오늘 하루종일 이 이미지만 생성한거 같다. CIVITAI 에 올려놓은 한복 LoRA를 사용해 생성했다.







- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
후면 이미지로도 생성해보았다. 오히려 뒷 모습을 그리는게 옷이 휘날리는 프롬프트에 더 부합하는 느낌이다.
실제 이런 옷을 볼 수는 없겠지만 언젠가 비슷한 거라도 있었으면 한다.






- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SDXL 에서는 FP8 를 사용않고 있었다. SDUI 에서도 FP8 이 기본적으로 활성화 되지 않는다. 문득 조금 이상하다는 생각이 들어 찾아봤다.
- 우선 SDUI 에서는 Optimizations 항목에 FP8 관련 설정이 아래와 같이 2개 있다.
① FP8 weight (Use FP8 to store Linear/Conv layers' weight. Require pytorch>=2.1.0.)
◎ Disable ◎ Enable for SDXL ◎ Enable
② Cache FP16 weight for LoRA (Cache fp16 weight when enabling FP8, will increase the quality of LoRA. Use more system ram.)
- ① 을 활성화하면 기본적으로 FP8 을 사용하게 된다. 실제로 해보면 성능 향상(이미지 생성속도)이 없다. 단 메모리는 FP8을 사용하는 만큼 적게 사용한다. FP8을 활성화 하는 경우 일부 LoRA 를 사용할 수 없다. 왜인지는 모르겠지만 오류 발생한다.
- SDXL 메모리 사용량
FP8: 3.80 GB
FP16: 5.23 GB

SDXL FP16

SDXL FP8
주) VAE 는 동일하게 FP32 사용한다.
- ②는 캐시관련된거라 성능에 관련이 없다.
- 결론적으로 써도 성능 향상이 없고, LoRA 호환성만 떨어뜨리기 때문에 사용 안하는 거다. 결과물도 다르다. (단 FP16이 항상 더 좋은 결과를 내주는건 아니다) FLUX.1 dev 는 FP8 을 쓰면 효과가 상당히 좋은데 (이미지 생성속도가 빨라지는데) 유독 SDXL 에서는 효과가 없다.
- 아래는 같은 프롬프트, 같은 파라메터를 사용해서 만든 이미지다. 어떤게 좋다고는 할 수 없지만 왠지 FP16 이 더 빛나 보인다.

FP8 으로 생성한 이미지

FP16으로 생성한 이미지
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
바람에 휘날리는 드레스와 노을은 언제나 예쁘다. 생각날때마다 만드는데, 이번에도 한번 올려본다. 해상도가 4000 x 2400 이기 때문에, 4k 화면에서도 잘 보일 것이다.





- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전










- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음