윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
16 개 검색됨 : 2023/04 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전

Stable Diffusion web UI (이하 SD)에 대해 안내되어있는 공식적인 최소사양, 권장사양은 없다. 여기서 말하려는건 내 경험에 의한 최소사양과 권장사양을 적으려 한다. 필자가 처음에 SD시작할때, 이런 정보를 찾기 힘들어서 필요한 사양을 가늠하기 어려웠는데, 지금은 아래와 같이 자신있게 말할 수 있다.
- 필자가 생각하는 최소사양 #1 - GPU 사용
1. CPU: 듀얼코어 이상
2. GPU: nVidia 1030 2GB
3. HDD: 16GB 여유공간
4. RAM: 8GB 이상
-> 512px 768px 이미지 1개 생성하는데 2분 정도 걸리며, 사용상의 제약이 매우 많다. 특히 고해상도 보정 기법인 Hires.fix 기능을 사용못하기 때문에, 고품질의 이미지를 생성할 수 없다.
-> nVidia Geforce GT 1030 (2GB VRAM) 으로 Stable Diffusion WebUI 사용하기
- 필자가 생각하는 최소사양 #2 - CPU 사용
1. CPU: 하스웰 아키텍처 이상의 듀얼코어 이상 CPU
2. GPU: 없음
3. HDD: 16GB 여유공간
4. RAM: 16GB 이상
-> 512px x 512px 이미지 1개 생성하는데 2시간 돌리다가 포기했다. 하지만 8 시간 정도면 생성 되지 않을까 생각한다. 사용상의 제약이 많다. 참고로 GPU 가 "없음"으로 되어있는건 GPU 없이도 사용 가능하다는 의미. 참고로 PC에서는 GPU 없이 윈도로 부팅이 안된다.
- 필자가 추천하는 권장사양
1. CPU: 듀얼코어 이상
2. GPU: nVidia 3060 12GB 이상
3. SSD: 256GB 이상
4. RAM: 32GB 이상
-> 1920px x 1080px 이미지 1개 생성하는데 2분 정도 걸리며 사용상의 제약이 크지 않다. 인터넷에 AI 로 생성한 그림들을 따라하고, 나만의 그림을 생성하는데 불편함이 없다.
-> 듀얼코어 이상이라고는 했지만, 이미지 생성시에는 거의 단일코어를 사용한다. 병렬연산은 GPU 에 맡겨놓기 때문이 코어 개수는 크게 중요하지 않다. 단일코어의 속도가 중요하다.
- 필자의 현재 사양 (2024.11.01 업데이트)
1. CPU: i3-6100 -> i5-7500 -> Ryzen 4750G
2. GPU: GT 1030 2G -> RTX 2060 12GB -> RTX 4060Ti 16GB
3. SSD: 512GB
4. RAM: 8GB -> 12GB -> 32GB -> 64GB
-> 2023.03.30 업데이트: 2060으로 업그레이드. 가장 드라마틱한 성능 향상이었다. 1920px x 1080px 이미지 1개 생성하는데 2분 10초 정도 걸리지만 사용상의 제약이 크지 않다. 해상도 낮은 걸로 여러개 생성해보고, 맘에 드는걸 골라 고해상도로 다시 생성하는 식으로 사용한다.
-> 2023.12.28 업데이트: 메모리 32GB로 업그레이드. 또한 새로나온 DPM++ 2M 의 샘플러 사용해서 2배 빨라졌다. 1920 x 1080px 생성시 100 초 정도 소요.
-> 2024.03.01 업데이트: Ryzen 4750G 으로 업그레이드. 마더보드도 바꿨다. 속도는 크게 차이 안났다.
-> 2024.08.02 업데이트: 메모리 64GB로 업그레이드. 속도는 크게 차이 안났다.
-> 2024.11.01 업데이트: 4060Ti 으로 업그레이드. 대략 50% 정도 생성시간이 줄었다.
- 필자의 예전 사양
1. CPU: i5 750
2. GPU: nVidia GT 1030 2GB
3. HDD: 256GB
4. RAM: 16GB
-> 512px x 768px 이미지 1개 생성하는데 15분 정도 걸리며 사용상의 제약이 많다. 맛보기로 조금 해보고 거의 바로 바꿨다. 어쨌든 말하고 싶은건 2GB VRAM 에서도 실행 되고 이미지 생성이 된다는 거다.
- 사용상의 제약이 없으려면 VRAM 이 24GB 이상 되어야 한다고 생각한다. VRAM 이 더 많으면 더 좋다. 따라서 RTX 3090 이나 RTX 4090 사용하면 좋다. CPU 만으로도 사용 가능하지만 64코어 CPU가 필요할 것으로 생각되어서 CPU로 사용하는건 사실상 포기다.
- 보통 기다리는데에 지루하지 않다고 느낄 수 있는 시간이 8초라고 한다. 대기시간이 8초 넘어가면 느리다는 생각을 하고 딴짓하기 시작한다고 들었다. 바꿔 말하면 즉 이미지 1장 생성하는데 8초 이내여야 한다는 의미. 필자의 경우 512 x 1024 로 생성하는데 20초 정도 걸린다. 어쨌든 성능 좋은걸로 바꿔서 줄이긴 줄여야 한다는 의미다.
- 시스템 구성할때 팁 하나 더 주자면... 시스템 냉각에 매우 많이 고민하고 투자해야 한다는 거다. 장비 구매 예산을 짤 때 GPU 구매 비용 뿐만 아니라 그걸 원활하게 냉각시키기 위해 사용하는 비용도 생각해야 한다. 생각외로 비용이 많이 들기 때문이다. 참고로 2060 12G 를 중고로 20만냥에 샀는데 냉각 비용만 20만냥 들었다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SD 를 사용하다보면, 아래와 유사한 오류가 발생하면서 더이상 진행안되는 현상이 발생하곤 한다. 데이터 중에 NaN(Not a Number) 값이 있어 처리할 수 없다는 메시지다.
Traceback (most recent call last):컴퓨터로 부동소수점 연산하다보면 NaN 이 생길 수 있기 때문에 이부분에 대해서는 대책을 세워야 한다. SD에서는 아래와 같이 해보라고 한다.
File "/home/windy/stable-diffusion-webui/modules/call_queue.py", line 56, in f
res = list(func(*args, **kwargs))
File "/home/windy/stable-diffusion-webui/modules/call_queue.py", line 37, in f
res = func(*args, **kwargs)
File "/home/windy/stable-diffusion-webui/modules/txt2img.py", line 56, in txt2img
processed = process_images(p)
File "/home/windy/stable-diffusion-webui/modules/processing.py", line 503, in process_images
res = process_images_inner(p)
File "/home/windy/stable-diffusion-webui/modules/processing.py", line 657, in process_images_inner
devices.test_for_nans(x, "vae")
File "/home/windy/stable-diffusion-webui/modules/devices.py", line 152, in test_for_nans
raise NansException(message)
modules.devices.NansException: A tensor with all NaNs was produced in VAE. This could be because there's not enough precision to represent the picture. Try adding --no-half-vae commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
--no-half-vae 옵션 사용
--disable-nan-check 옵션 사용
--xformers 옵션 사용
필자는 3가지 옵션을 다 해봤지만 그래도 간혹 나기는 한다. --no-half-vae 옵션이 가장 발생 빈도를 낮추는것 같다. --disable-nan-check 옵션 주면 그냥 검은색 이미지 생성하고 다음으로 넘어간다. 이 오류는 VAE 를 처리할 때 발생한다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
Stable Diffusion web UI (이하 SD) 를 사용하다보면 반드시 사용하게 되는 SD 의 기능중 하나가 LoRA (Low-Rank Adaptation of Large Language Models)다. 여기서 Large Language Models 는 Transformer 를 이야기하는거고 Stable Diffusion 에도 Transformer 가 있기 때문에 이 부분에 적용된다.
기본적으로 학습된 모델을 (SD 에서는 체크포인트) 파인튜닝(미세조정)하려면 DreamBooth 를 사용해 재학습 시켜야 한다. 재학습시키는건 비용(=시간)이 많이 들기 때문에 좀 더 빠르게 미세조정할 수 있는 방법을 생각해보다가 나온게 "Low-Rank Adaptation" 이다. 예를 들어 1000 x 2000 행렬을 1000 x 2 + 2000 x 2 로 해서 학습할 파라메터를 줄인다. 이후 LoRA 를 이용한 다양한 기법들이 연구되고 사용되고 있다.
- LoRA: Low-Rank Adaptation (Tranformer 블록만 학습)
- LoCon: LoRA for Convolusion Network (Tranformer 외에 Res 블록도 학습)
- LoHa: LoRA with Hadamerd Product Representation (LoRA 에서 행열곱 연산 대신 하마다르곱 연산을 사용)
- LoKR: LoRA with KRonecker Product Representation (LoRA 에서 행열곱 연산 대신 크로네커곱 연산을 사용)
- DyLoRA: Dynamic search-free LoRA (한번의 학습으로 여러 Rank 의 모델을 얻음)
SDUI 에서는 LyCORIS(Lora beYond Conventional methods, Other Rank adaptation Implementations) 라는 확장 프로그램을 사용해 각종 LoRA 들을 사용할 수 있다.
물론 학습이 쉬워졌다(=낮은 사양에서도 실질적으로 학습 할 수 있다)는 이야기지, 대충 만들어도 좋게 나온다는 의미는 아니다. 그래도 학습에 필요한 양질의 이미지를 준비해야하기 때문에, 상당한 노력과 시간이 필요하긴 하다.
학습에 필요한 이미지가 준비되었고 준비된 이미지에 프롬프트를 설정해주었다면, RTX 3060 12G 에서 LoRA 를 생성하는데 3시간 정도 걸린다.
필자가 생성하는 거의 모든 이미지에 koreanDollLikeness_v10 를 사용한다. 심지어 koreanDollLikeness_v20 이 나오긴 했지만 안쓴다. 맘에 드는 LoRA 하나 정도는 찾아 놓는것도 좋을것 같다. 아래 이미지는 이를 사용해 생성한 이미지다.





- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SD를 사용하다보면, 스탭을 몇번에 놓을지 고민하게 된다. 필자는 처음에는 24 스텝을 사용하고, 업스케일링할 때에는 30으로 놓고 업스케일링 한다. 스텝을 늘이는 이유는 더 선명해지고, 디테일이 증가하기 때문이다.
하지만 이렇게 하다보면 간혹 스텝 24일때와 스텝 30일때 큰 변화를 가지게 되는 경우가 생긴다. 대부분의 이미지는 30으로 설정할 때 더 선명해지기만 하지만, 그렇지 않은게 간혹 나온다. 아래와 같이 말이다.


아래와 같아지는 경우도 있다.


하지만, 선명한 이미지는 스케일업할 때에도 할 수 있고, 그래서 필자는 이런 경우는 스텝을 늘여서 제작하지 않는다. 특히 18, 19, 20, 21 스텝이 이미지가 판이하게 다르게 나오곤 한다. 공통적으로 프롬프트가 적용되는 강도가 달라지는 거지만, 강하게 적용된다고 모두 내 맘에 든다는 아니니 말이다. 그렇다고 모든 스텝을 다 확인해볼 수는 없는 노릇이고 말이다. 어떻게 효율적으로 확인해보는 방법 없을지 고민이다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
체크포인트 바꾸려고 이리저리 머지 해보다가 하나 건졌다. 이를 윈디하나#1 이라고 명명했다. ㅎㅎ
서브컬처에서 에니메이션풍 그림을 "2D", 사진풍 그림을 "3D" 라고 한다. 이의 중간정도 되는게 "2.5D"라고 하는데, AI 로 생성한 그림들이 주로 이 레벨이다. 그래야 위화감이 별로 없을 거라 생각한다. 실사와 너무 같으면 불쾌한골짜기도 생기고 말이다.
하지만 필자는 2.5D 에서 더 에니메이션 풍을 원했다. 그렇다면 2.3D 정도 되려나. 아래 사진정도면 2.3D 라고 봐줄만 하지 않을까?







- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
인물 사진 얼굴을 변경해보기 위해 체크포인트 머지했다. 얼굴을 변경하는 많은 방법이 있겠지만, 로라사용하는 것 외에는 이게 가장 먼저 생각 났다. 예쁜 얼굴을 만들기 위함이다.
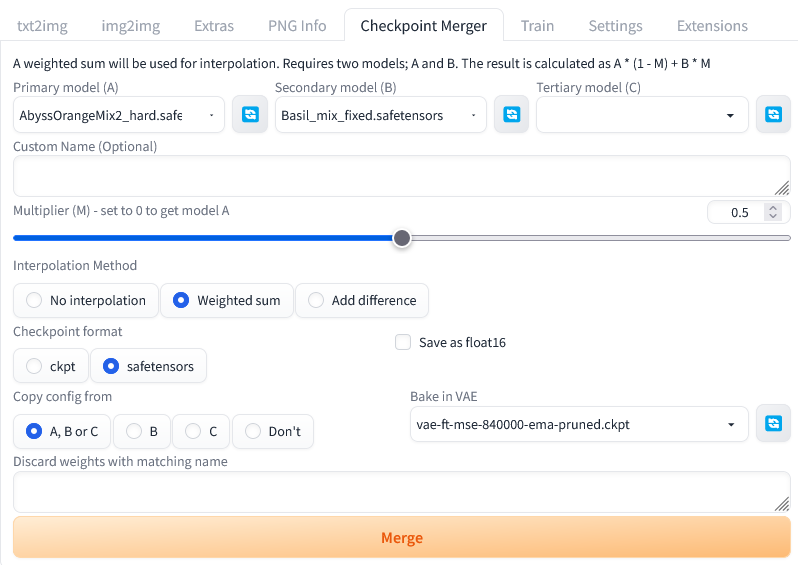
기본적으로 WebUI 에서 머지를 지원한다. 여러가지 모델에 대해 문제 없이 머지되도록 잘 되어있기 때문에 이를 사용해 머지한게 많다. 그냥 체크 포인트 두개 선택하고, 비율 조절해준 다음 safetensors 선택해서 머지해주면 된다. 위 사진과 같이 하면 체크포인트 해시 "ca883fecc7" 값을 가지는 safetensor 파일이 나온다. 이 조합법이 한때 많이 유행했다고 한다.
이렇게 하면 같은 시드, 같은 프롬프트라도 다른 이미지가 나온다. 아래와 같이 말이다. 다른건 몰라도 얼굴형을 미세 조정 하는건 어렵기 때문에 얼굴만 봤다. 이중 맘에 드는거 하나 골랐다. ㅎㅎ



- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/하드웨어 정보

라이저케이블을 사용해 VGA 를 수직 장착했다. 배송비 별도 4.95 만냥에 구매했다. 사용하고 있는 2060이 기가바이트 윈드포스라 바람이 그래픽 카드 위로도 나온다. 따라서 수평 장착시 케이스 측면을 향해 뜨거운 바람이 불게되고, 이때문에 뜨거운 바람이 다시 케이스 안으로 들어가게 된다. 여러모로 발열을 해결하는데 있어 문제가 되기 때문에 수직 장착으로 해결했다. 수직 장착하면 케이스 후면 팬으로 뜨거운 바람이 나가게 된다. 케이스 내부 온도는 쉽게 체감될 정도로 낮아졌고, 그래픽 카드 온도는 72 도 정도로 수직장착 전보다 3도 낮아진걸로 측정되긴 했지만 큰 차이 없는듯 하다.
라이저케이블을 사용해 그래픽 카드를 장착하게 되면, 그래픽 카드가 붕 뜨게 된다. 그냥 그래픽 카드가 떠있는 상태에서 그래픽 카드 받침대를 사용해 지지하고, 라이저케이블을 사용해 마더보드의 PCIe 16 포트와 그래픽 카드의 접속 단자를 연결해주는식으로 설치한다. 초기에는 PCIe 3.0 용 케이블만 판매했고 품질도 조악했었다고 하는데, 요즘 판매되는건 PCIe 4.0 용 케이블이고 속도저하도 없다고하며 무었보다 5만원정도로 저렴하게 구매할 수 있다.

필자의 경우도 다행이 성능 저하는 없는듯 하지만, 현재 사용하고 있는 마더보드는 PCIe 3 까지만 지원하는거라 PCIe 4 로는 확인 못했다.

L610 수직 장착
케이스에 따라 전용 라이저 장치를 달 수 있는경우도 있지만, 그렇게 하면 다른 확장포트를 전혀 쓰질 못하게 되어서 이런식으로 장착했다. 케이스에 수직으로 장착해 고정할 수 있는 확장 포트가 있고, 라이저케이블을 끼울 수 있을 정도의 공간이 있다면, 다른 케이스에도 장치하는건 어렵지 않을것 같다. 참고로 필자는 3RSYS L610 를 사용한다.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
Stable Diffusion WebUI (이하 SD) 사용하다보면 같은 프롬프트를 주었는데도 유사한 이미지를 생성하지 못하는 경우가 꽤 자주 있다. 원인은 모르겠지만, 프롬프트 외에도, SD 실행시 옵션이나 설정이 달라지면 같은 프롬프트로도 완전히 다른 이미지가 생성되는것 같다.
재미있는건 이 현상이 이미지 업스케일링에서도 일어난다는 거다. txt2img 에서 hi.res fix 를 사용하거나, img2img 탭에서 업스케일링하는 경우에 업스케일링 전 이미지와 살짝 다른 이미지를 생성해 낸다. 그게 더 좋아보이기 때문에 사용하고 있다. 어쨌든 img2img 탭에서는 프롬프트를 입력하도록 되어있고 이 프롬프트를 업스케일링할때 사용한다.
이 문서에서는 프롬프트를 사용해 업스케일링 하는 방법을 이야기 한다. AI를 사용한 이미지 업스케일링은 Extra 탭에서 사용하고 추후 다룰 것이다.
※ 이미지 생성시에 사용한 프롬프트를 가지고 있지 않은 경우
img2img 탭에서 프롬프트 없이 실행.
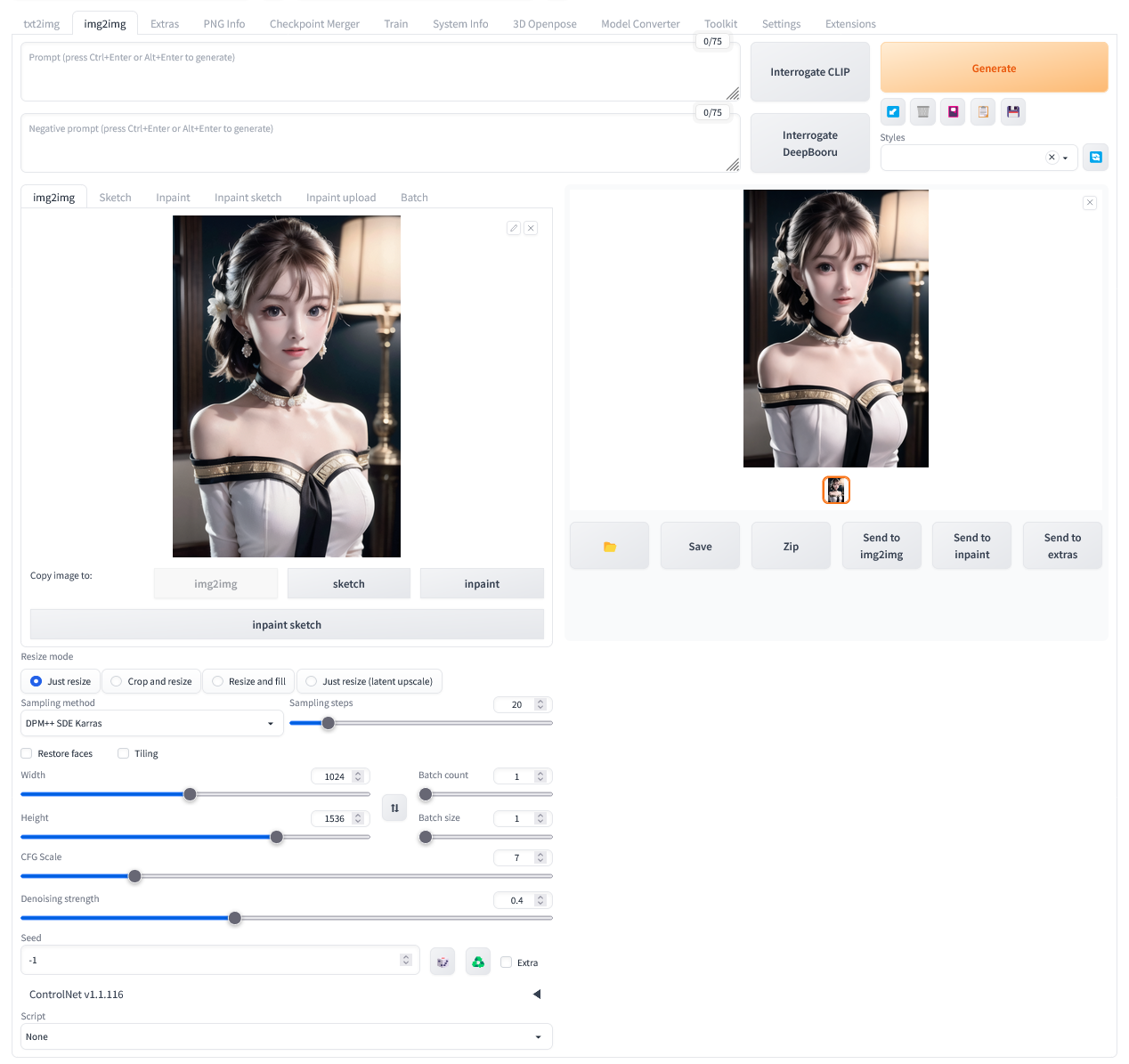
프롬프트를 사용하지 않은 이미지 업스케일링
단, 단순 업 스케일링 하는 경우 PNG 파일에는 프롬프트가 남지 않는다. 프롬프트를 입력하지 않아도 업스케일 되기 떄문에, 필자는 입력하지 않는다. 또한 선명함이 조금 낮아진다. 그래도 프롬프트를 전혀 알 수 없을때 SD 를 사용해야할때 할 수 있는 방법이다. 추천하는 방법이 아니다. 프롬프트 없으면 Extra 탭 사용하자.
※ 이미지 생성시에 사용한 프롬프트를 가지고 있지만, txt2img 탭에서 프롬프트를 사용했을 때 같은 이미지가 생성되지 않는 경우
img2img 탭 하단의 Script 드롭박스에서 SD upscale 을 선택한 후 Upscaler 를 선택해 사용
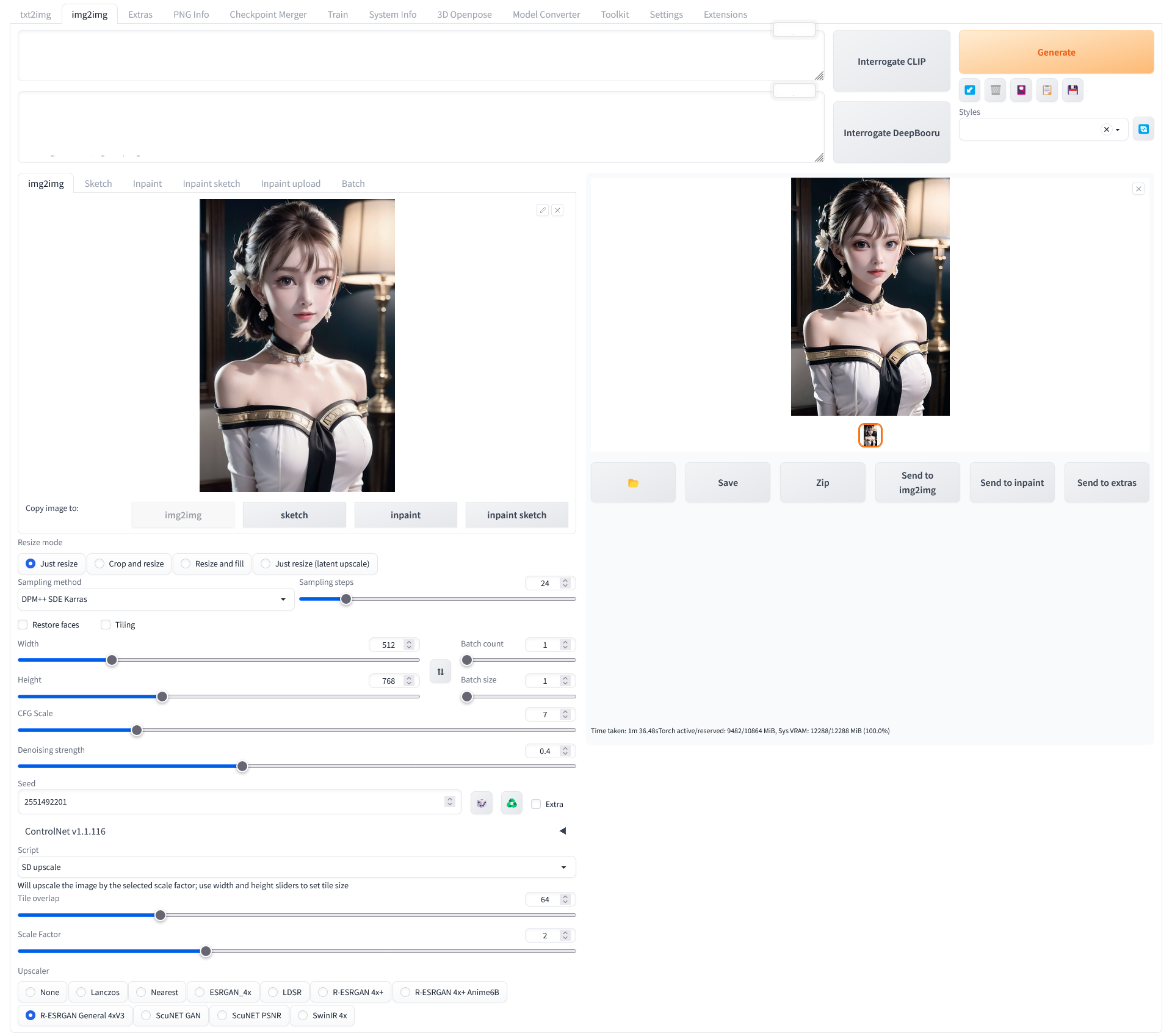
프롬프트를 사용한 이미지 업스케일링. (스크린샷에서 프롬프트는 삭제되어있다)
매우 쓸만해지고 선명해진다.
아래는 업스케일링한 이미지들이다.







- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
파스텔 풍 그림 그려주는 모델이다. 써본 것 중에 가장 괜찮은것 같다.
원래는 다른 이미지를 얻기 위한 프롬프트인데, 시드를 높이면서 이미지를 생성하면 아래와 같이 입력한 프롬프트와 다른 이미지를 그려주기도 한다. 그런데, 이게 맘에 드는 경우가 있다. 뭔가 과하게 학습되었다고 생각되는데, 그게 나름 괜찮다. 다른 모델들 보다 animePastelDream 이 조금 심한것 같긴 하다. 아래는 그 사진들이다. 1920 x 1080 해상도로 업스케일 했다. 윈도 바탕화면 용이다.






- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
FP16과 FP32 가 어떤 차이가 있을까 궁금해서 한번 테스트 했다. 결론을 먼저 말하자면, 그냥 FP16 사용하자. 사용하는데에는 결과물에 차이 없고 메모리를 더 적게 사용하기 때문에, FP16 사용해야 한다.
nVidia RTX 2060 에서 테스트했다. 참고로 20 시리즈는 FP16 이 FP32 보다 연산능력이 2배 좋다. 30 시리즈부터 FP16 과 FP32 연산능력이 동일하다.
이미지크기는 504 x 960 으로 했다.
① FP32 체크포인트, FP32 실행
chilloutmix_NiPrunedFp32Fix FP32 5.1G -> 5.9G -> 7.7G -> 5.1G Total progress: 100%|██████████████████████████████████████████████████████████████████| 28/28 [00:46<00:00, 1.48s/it]
② FP32 체크포인트, FP16 변환
chilloutmix_NiPrunedFp32Fix FP32 -> FP16 2.6 -> 10.1 -> 8.9G -> 3.0G 100%|████████████████████████████████████████████████████████████████████████████████| 28/28 [00:28<00:00, 1.01s/it] Total progress: 100%|██████████████████████████████████████████████████████████████████| 28/28 [00:24<00:00, 1.15it/s] Total progress: 100%|██████████████████████████████████████████████████████████████████| 28/28 [00:24<00:00, 1.57it/s]
③ FP32 체크포인트, FP16 실행
chilloutmix_NiPrunedFp32Fix FP16 3.0G -> 3.3G -> 5.1G -> 3.0G Total progress: 100%|██████████████████████████████████████████████████████████████████| 28/28 [00:17<00:00, 1.61it/s]
④ FP16 체크포인트, FP16 실행
chilloutmix_NiPrunedFp16Fix FP16 3.0G -> 3.3G -> 3.0G Total progress: 100%|██████████████████████████████████████████████████████████████████| 28/28 [00:17<00:00, 1.62it/s]
② 은 FP32로 학습한 체크포인트를 FP16 으로 수행하기 전에 FP16 으로 변환하는데, 처음 체크포인트 변환시 10.1G, VAE 변환시 8.9G 를 소비한다. 재 실행시에는 변환작업이 없다.
생성한 이미지
①

③

④

메모리 사용
①
②③
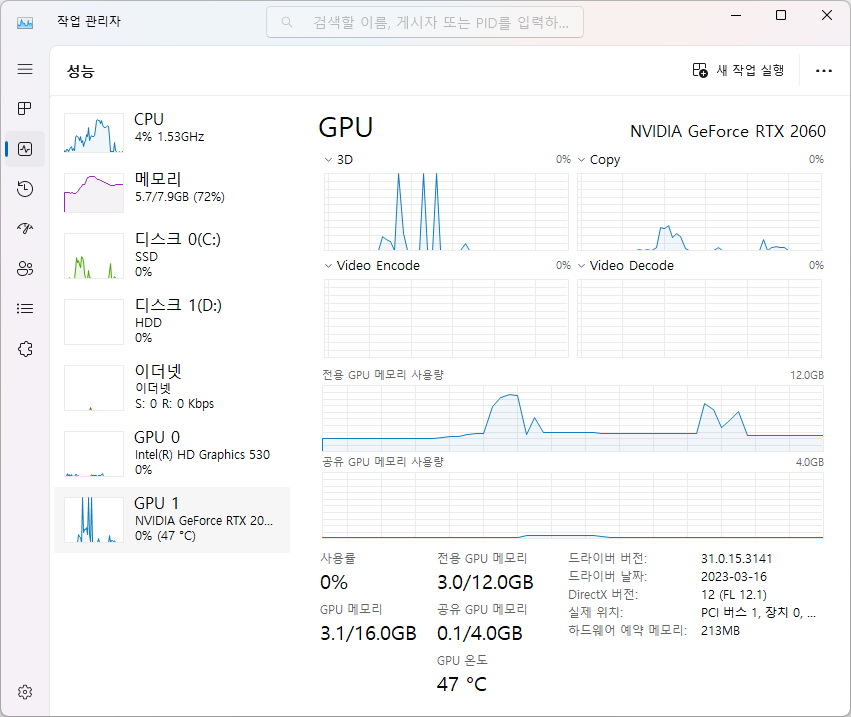
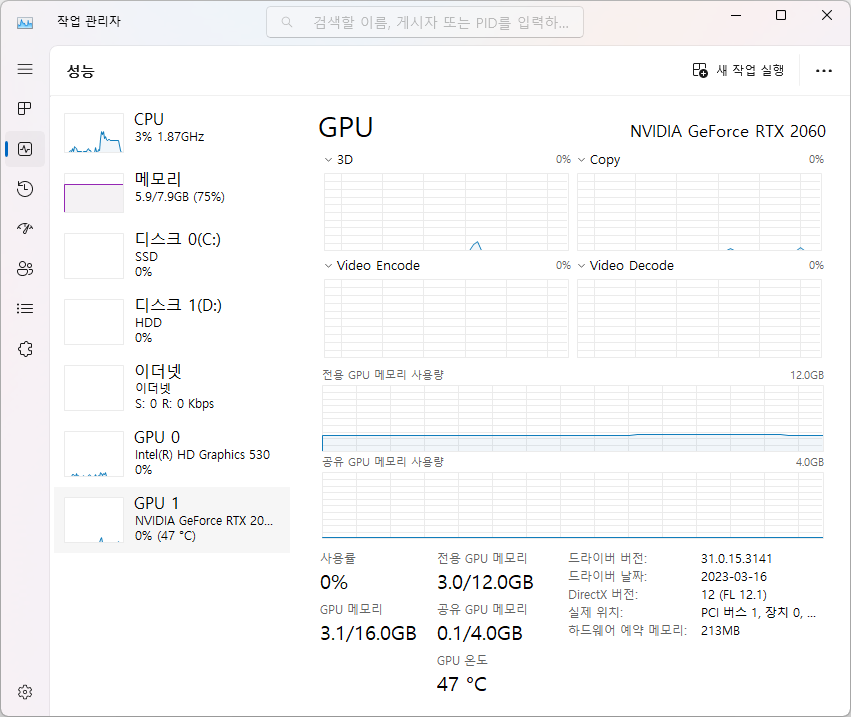
④
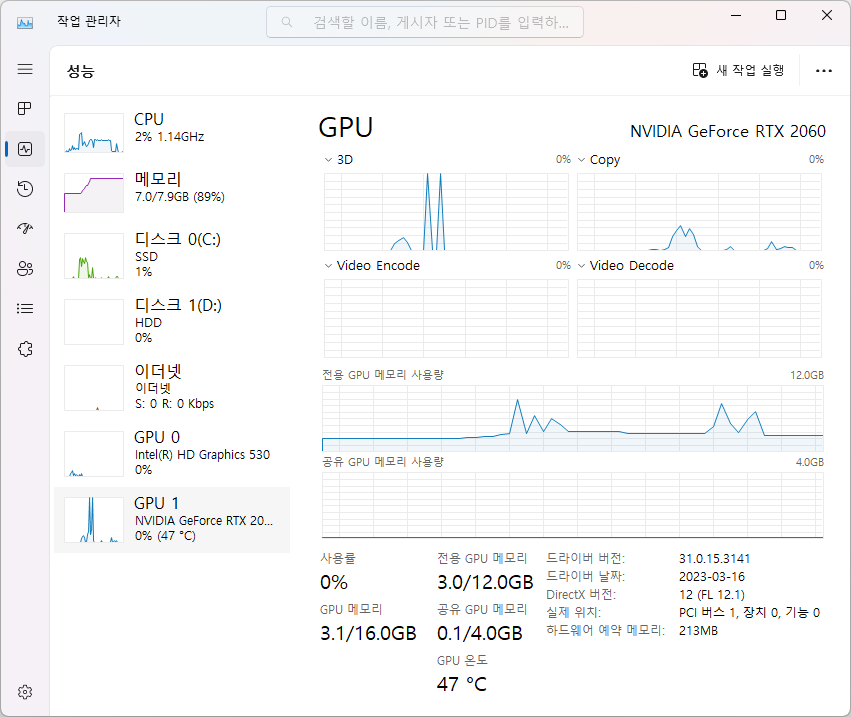
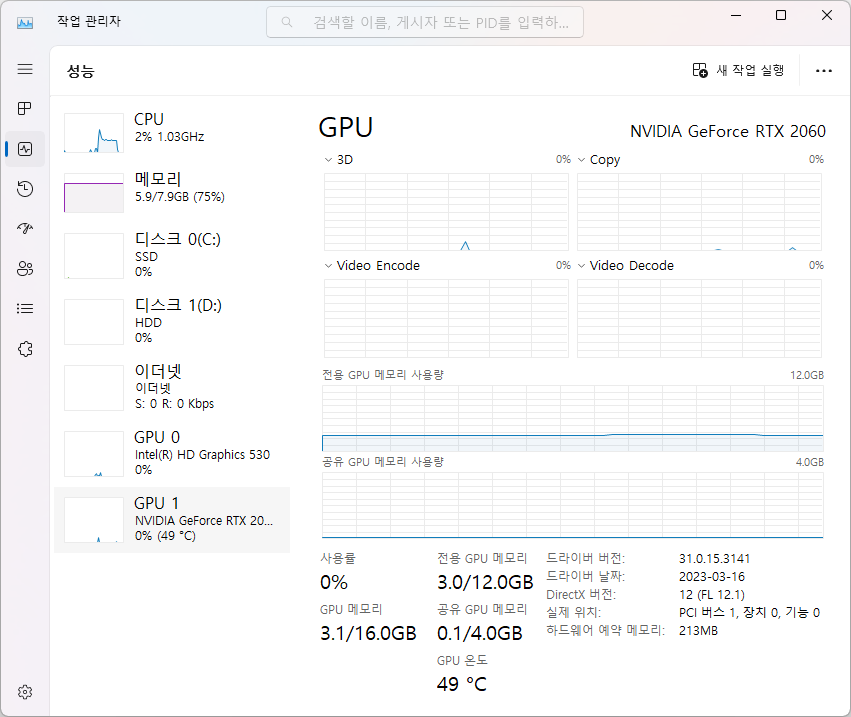
------------
참고: GT1030, --lowvram
이미지크기: 384 x 768
① FP16 체크포인트, FP32 실행
chilloutmix_NiPrunedFp16Fix FP32 1952MiB
Total progress: 100%|██████████████████████████████████████████████████████████████████| 20/20 [08:10<00:00, 25.61s/it]
② FP16 체크포인트, FP16실행
chilloutmix_NiPrunedFp16Fix FP16 1350MiB
Total progress: 100%|██████████████████████████████████████████████████████████████████| 20/20 [05:10<00:00, 16.15s/it]
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음