윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
153 개 검색됨 : 기술,IT/스테이블 디퓨전 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
스테이블 디퓨전에서 샘플러는 이미지에서 노이즈를 제거하는 방법에 대한 정의다. 생성한 이미지의 품질에 직접적인 영향을 끼치기 때문에 좋은 샘플러를 사용하는건 그만큼 좋은 이미지를 생성할 수 있다는 의미다.
샘플러의 동작 원리 같은건 인터넷을 찾아보자. 필자도 잘 모른다.
이번 Stable Diffusion WebUI 1.6 (이하 SDUI) 버전에서 꽤 많은 샘플러가 추가 되어있다. 샘플러는 "상 미분방정식(Ordinary Differential Equations)" 이나 "확률 미분방정식(Stochastic Differential Equation)"을 푸는 알고리즘이 들어가 있다. 세계적인 수학자 오일러의 방식이나 카를 호인의 방식이 그것이다. 자세한 구현 방법은 생략하겠다.
어쨌든 SDUI 에서 사용할 수 있는 샘플러에 대한 샘플 이미지를 작성해 보았다. 결론부터 말하자면 현재 필자가 사용하는 샘플러는 "DPM++ 2M SDE Heun Karras" 이다.
샘플러도 좋아야 하지만 샘플러와 모델도 맞아야 한다. 모델을 보면 어떤 샘플러를 사용해 튜닝했는지가 나오는데 예전엔 DPM++ SDE Karras 을 많이 사용했다. (필자도 지난달까지만 해도 이걸 썼다)
1. DPM++ 2M Karras
2. DPM++ SDE Karras
3. DPM++ 2M SDE Exponential
4. DPM++ 2M SDE Karras

DPM++ 2M Karras

DPM++ SDE Karras

DPM++ 2M SDE Exponential

DPM++ 2M SDE Karras
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
필요에 의해 정리해 놓는다. 총 10가지 인데, 대략 의미는 아래와 같다.
1. extreme facial close up: 최대 얼굴 클로즈업 - 얼굴 - (face portrait 라고도 함)
2. facial close up: 얼굴 클로즈 업 - 어깨 부터 위
3. medium close up: 미디엄 클로즈 업 - 겨드랑이 부터 위
4. bust shot: 바스트 샷 - 가슴 위
5. waist shot: 웨이스트 샷 - 허리 위
6. medium shot: 미디엄 샷 - 배꼽부터 위
7. upper body: 상반신 - 골반부터 위
8. cowboy shot: 카우보이 샷 - 허벅지 중간부터 위
9. thigh above body: 허벅지 상위 샷 - 허벅지부터 위
10. full body: 전신 - 발끝부터 위
Stable Diffusion 에서는 구도는 이미지의 크기에 영향을 받는다. SD 1.5 는 512px x 512px, SDXL 은 1024px x 1024px 이기 때문이 1:1 비율이 아닌 이미지 생성시에는 구도가 다르게 표현되곤 한다.
아래는 위 샷 이미지를 540px x 960px (9:16 비율) 에서 구현하고 업스케일한 이미지다. 같은 프롬프트에서 구도 프롬프트만 변경했다. 구도에 따라 얼굴 형태가 어떻게 바뀌는지 살펴봐야 이미지를 제대로 생성할 수 있다.

1. extreme facial close up

2. facial close up

3. medium close up

4. bust shot

5. waist shot

6. medium shot

7. upper body

8. cowboy shot

9. thigh above body

10. full body
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
CivitAI 에 바(Bar) 로라가 올라와있어, 바니와 같이 생성해 보았다. 생각보다는 잘 되어서 올려본다.







- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
뭔가 고상하고 어려워 보이는 문제를 푸는 장면을 연출하고 싶긴 했지만, 잘 안된다. 특히 어려워보이는 문제를 칠판에 빼곡하게 그리는게 쉽지 않은듯. 프롬프트 문제인감. 그래서 피타고라스의 정리를 쓰는 걸로 했다. 유명한 정리라 학습되어있을 거라고 생각해서다. 역시 뭔가가 학습되어있긴 한거 같다.
가로구도에서는 단상 위에 올라서서 칠판을 가리키는게 안된다. 세로구도에서는 되는 느낌. 구도를 강제로 잡으려면 컨트롤넷을 사용해야 하는데, 거기까지 하는건 힘들다. 그래서 책상위에 올라탄 그림이 그려진다.




- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
긴 의상들만 모아서 게시한다. 긴 치마 의상은 거의 중국식 의상이기도 하다. 그만큼 AI 쪽에서는 중국의 역할(?)을 무시 못한다. CivitAI 에 자주 중국 의상 LoRA 가 업로드되는거 보면 왠지 부럽기도 하다.
의상은 역시 한복도 아니고 기모노도 아니고 장삼도 아닌 애매한 그림이 나온다. 그래도 맘에 들어서 게시한다.








- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
전통의상 틱한 뭔가를 만들어 보았다. 대한민국의 전통의상인 한복은 아니다. 결정적으로 옷 고름의 위치가 다르기 때문. 뭔가 한복과 기모노와 장삼이 섞인 느낌. 그래도 맘에 드는게 있어 업로드 한다.










- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
기타 업스케일러. Nearest 업스케일러를 아주 가끔 사용하긴 하지만, 거의 사용하지 않는다.

Original

Lanczos

LDSR

Nearest

ScuNET GAN

ScuNET PSNR

SwinIR_4x
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
4x- 로 시작하는 업스케일러를 별도로 받아 사용할 수 있다. ESRGAN 계열의 업스케일러다. 4x-UltraSharp 는 여전히 많이 사용되는 업스케일러이기도 하다.
Model Database 에 있는 링크를 통해 받을 수 있다. 모델을 받아 stable-diffusion-webui/models/ESRGAN 디렉토리에 복사하고 SDUI 를 껏다 다시 켜면 사용할 수 있다.

Original

4x-AnimeSharp

4x-UltraMix_Balanced

4x-UltraMix_Restore

4x-UltraMix_Smooth

4x-UltraSharp
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
SD 에서 사용할 수 있는 업스케일러를 테스트했다. 예전에 테스트해본결과 "R-ESRGAN General 4xV3"을 주로 사용하게 되었는데, 그걸 정리한거다.
SD webUI 에서는 Extra 탭에서 사용할 수 있다. 프롬프트 없이 가능하고 빠른데다 x4 나 도 x8 도 가능하기 때문에, 게다가 배치작업 (특정 디렉토리의 모든 이미지를 업스케일링 하는 작업)도 가능하기 때문에 자주 사용한다.

Original

ESRGAN 4x

R-ESRGAN 2x+

R-ESRGAN 4x Anime6B

R-ESRGAN 4x+

R-ESRGAN AnimeVideo

R-ESRGAN General 4xV3

R-ESRGAN General WDN 4xV3
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
출시되었습니다.
- 공식 체크포인트 파일은 아래에서 받을 수 있습니다.
BASE: sd_xl_base_1.0.safetensors
REFINER: sd_xl_refiner_1.0.safetensors
VAE: sdxl_vae.safetensors
문제는 위의 공식 버전은 FP16 을 사용할 경우 VAE 적용에서 문제생긴다네요. 그래서 VAE 를 다르게 적용해 합본한 파일을 받아 사용해야 합니다. 결과적으로 아래의 통합 파일을 받아서 사용해야 합니다.
- StabilityAI 에서 VAE를 통합한 파일을 다시 배포했습니다. 아래에서 받을 수 있습니다. WebUI 에서는 아래걸 받아 VAE 없이 사용하면 됩니다.
BASE + VAE: sd_xl_base_1.0_0.9vae.safetensors
REFINER + VAE: sd_xl_refiner_1.0_0.9vae.safetensors
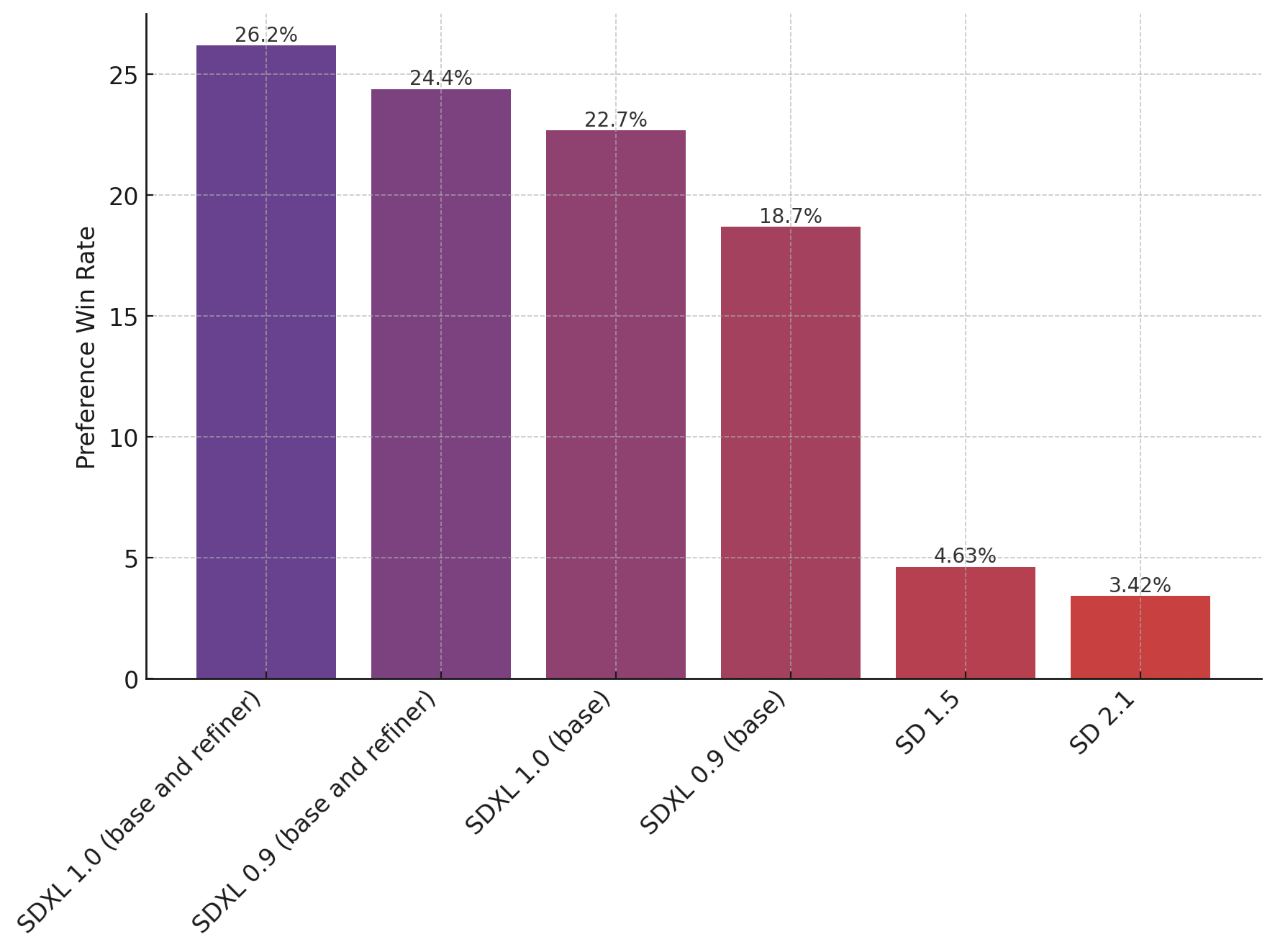
보름쯤 전에 배포된 0.9 버전보다 더 좋아졌다고 하네요. (그래프 값의 합은 100% 입니다)
사용해보니 메모리. VRAM 과 시스템 메모리 사용양이 많습니다. VRAM 12GB, 시스템 메모리 32GB 도 버겁다는 말이 있네요.
현재 사용하고 있는 제 시스템 사양이 VRAM 12GB, 시스템 메모리 12GB 인데, 체크포인트 로딩하는데 1470초 걸렸습니다. HDD 라 더 걸리는것 같지만 근본적으로 메모리가 부족합니다. 시스템 메모리 64GB 만들어야 할거 같네요.
로딩 이후에는 시스템 메모리 4.5GB, VRAM 8.3 GB 사용하고 있습니다. 이미지 생성시에는 12GB, 12GB 다 차네요. 역시 메모리가 부족합니다. SDXL 생성에 걸린시간은 40초 정도로 SD 1.5 의 20초보다 2배 정도 더 걸립니다.
아래는 SDXL 으로 생성한 그림입니다. 기본이 이정도 퀄리티라면 역시 SDXL으로 바꾸긴 해야겠네요. SD 1.5 오리지널보다 훨씬 많이 디테일이 좋고 프롬프트가 이미지에 잘 반영됩니다. CivitAI 찾아보니 이미 DreamShaper 라는 체크포인트는 SDXL 용으로 Alpha 버전이 올라와 있네요. SD 2 나올때보다 더 폭발적인 반응입니다. 앞으로 SD1.5 에서 SDXL 으로 많이 바꿀거라 생각합니다.


- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음