- 트윅 윈도우 1
윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
1000 개 검색됨 : 기술,IT 에 대한 결과
- 글쓴시간
- 분류 기술,IT
드디어! 기다리던게 나왔습니다. 삼성의 DDR5-6400 메모리 모듈입니다. CUDIMM 형식으로 나왔네요. DDR5-5600 까지만 UDIMM 으로 나오고, 그 이후부터는 CUDIMM 으로 나오네요.

현재 나온건 16GB, 8 GB 모듈입니다. 16GB 는 40만원 정도에 거래되고 있네요. 아직은 비싼감이 있지만, 조만간 저렴해지겠죠. 16GB 모델의 파트넘버는 m333r2ga3pb1-ccp 입니다.
이제 DDR5 으로 바꿀때가 되었으려나요.
현재 CUDIMM 을 지원하는 CPU 는 인텔의 코어 울트라 시리즈 2 뿐입니다. 이것도 Z890 마더보드를 사용한 시스템에서만 지원됩니다. AMD AM5 소켓을 사용하는 CPU 가 아직 지원을 못하지만 일부 AMD CPU용 마더보드에서는 CUDIMM 의 bypass 모드를 사용해 낮은 속도로는 사용할 수 있는것으로 알려져 있습니다.
즉 아직 호환성은 별로이긴 하네요. 하지만 컨슈머용으로 발매되었으니 조만간 지원이 늘어날걸로 생각합니다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT
Shortcut Forwarding Engine, Flow Acceleration
DD-WRT 를 사용하다보면 WAN Setup 설정 부분에 아래 2가지 설정이 있다. 한번 정리해 본다.
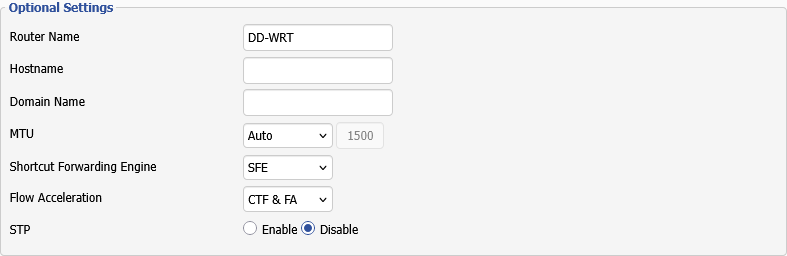
DD-WRT 를 사용하다보면 WAN Setup 설정 부분에 아래 2가지 설정이 있다. 한번 정리해 본다.
1. Shortcut Forwarding Engine
- Disable
- SFE
- CTF
2. Flow Acceleration
- Disable
- CTF
- CTF & FA
위는 라우터에서 NAT 를 가속하는 기술이다. 원래 가정용 공유기라는게 저렴한 가격(=하드웨어)에 적절한 성능을 제공하는게 목표였는데, 요즘에는 가정에서도 고속 네트워크를 사용하기 때문에 꽤 오래전부터 좀 더 빠른 NAT 에 대해 연구하기 시작했고, SFE, CTF, FA 는 그 결실이다.
※ SFE (Shortcut Forwarding Engine)
퀄컴에서 개발한 NAT 가속 엔진. 오픈소스이고, 소프트웨어적으로 작동한다. GITHUB 에 소스가 공개되어있다.
https://github.com/waau/qualcomm-sfe
※ CTF(Cut-Through Forwarding)
브로드컴에서 브로드컴 CPU 를 위해 개발한 하드웨어 NAT 가속 엔진.
※ FA(Flow Accelerator)
브로드컴에서 브로드컴 SoC 를 위해 개발한 Flow Control 가속 엔진.
※ 설정방법
아래와 같은 순서로 설정하고, 테스트해본다. 이상없으면 다음 설정으로 넘어가면 된다. SFE 보다 CTF 더 빠르고, CTF 보다 CTF & FA 가 더 빠르다. QoS 를 사용한다면 CTF & FA 를 사용할 수 없다.
1. Disable → SFE → CTF
2. Disable → CTF → CTF & FA
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
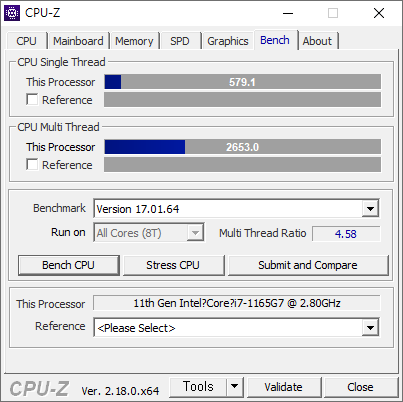
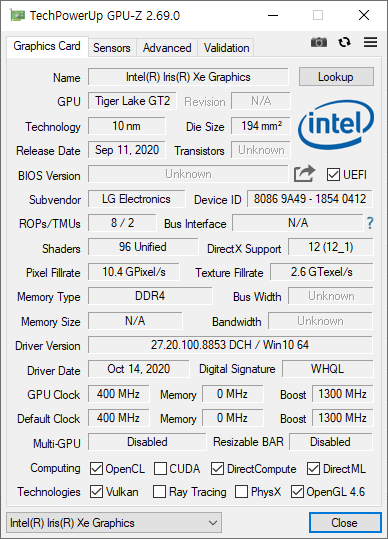
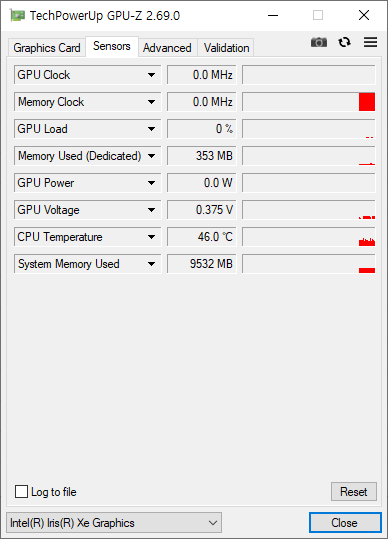
우연한 기회에 써본 1165G7. 상당히 좋다. 11세대 이후로는 데스크탑용 CPU 에는 AVX512 지원이 거의 없다. 아마 11세대 Core 프로세서가 AVX512 를 지원하는 마지막 데스크탑용 CPU 일것 같다.
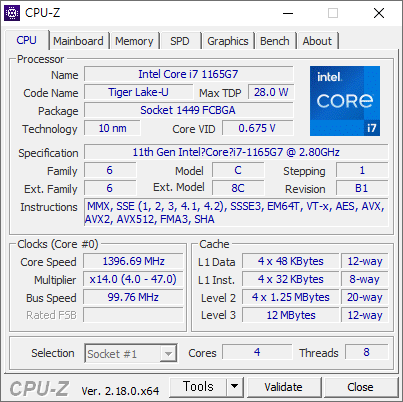
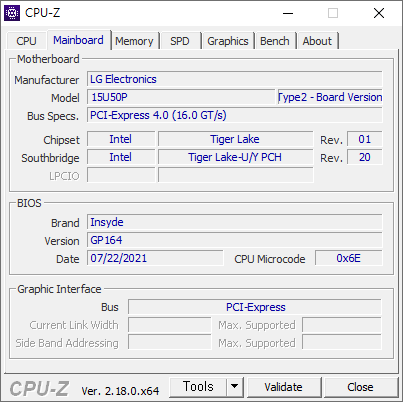
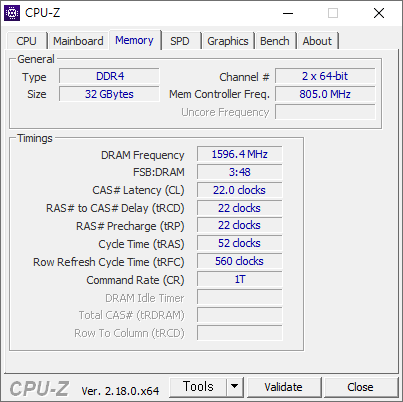
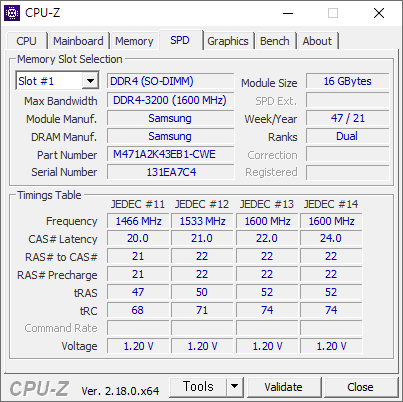
벤치마크는 579 점으로 잘 나왔다.
GPU-Z 는 아래와 같다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
우연히 사용하게된 MX450 이다. 성능은 1030 보다 조금 더 좋은 정도. 어차피 메모리가 2GB 이라 요즘 게임 하기엔, AI 돌리기엔 버겁다.
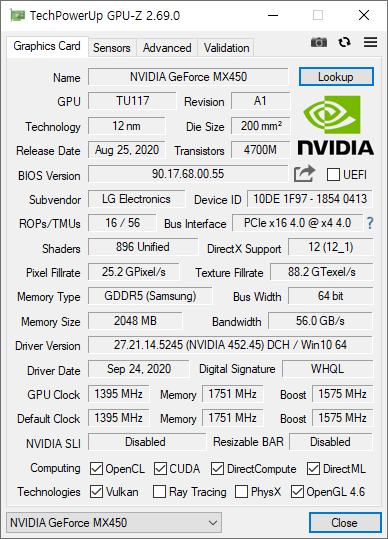
MX450 중에서는 나중에 나온 제품이다. 그래서 기존것 보다는 성능이 약 2배 정도 좋다. 하지만 어차피 게임 옵션을 높일 수 있는 수준은 아니다. MX450 은 스펙이 다양하기 때문에 일일이 확인해봐야 하기도 하다. 어쨌든 TU117 기반이고 MX450 에 사용한 TU117S 는 TU117 의 컷칩이다. TU117S 는 대략 GTX 1650 의 절반 수준이고, NVENC, NVDEC 가 없는 칩이다.
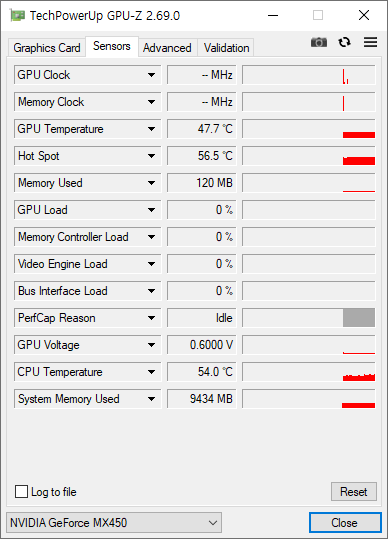
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
그냥 습관적으로 이것 저것 생성하다가, 드레스를 입히면 괜찮을 것 같은 조합이 나왔다. 바로 실행해봤다. 나름 맘에 들어서 올려본다.

아래 사진이 가장 맘에 들었는데, 스케일 업 과정에서 손가락에 문제가 생겼다. 손가락 부분은 수정했다.




- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
DDR5 메모리 살펴보다가 주의해야할 사항이 하나 있었네요. 잊지 않도록 블로그에도 적어 놓습니다.

삼성 5세대 DDR5 메모리 칩. 16Gb 짜리 칩이다.
인텔 코어 울트라 플랫폼(인텔 15세대 이후 플랫폼)에서, 8Gb 메모리 칩을 사용한 메모리 모듈을 인식하지 못하는 현상이 있다네요.
보통 8GB 또는 16GB 메모리 모듈중 일부가 해당됩니다. 8 GB 메모리인데 칩을 8개를 사용하거나, 16 GB 메모리인데 칩을 16개 사용하면 메모리가 인식 안된다고 하네요. 다른 플랫폼에서는 됩니다. AMD 플랫폼에서는 이슈 없구요.
즉 16기가 모듈의 경우 1Gb x 16 또는 2Gb x 8 으로 구성되는데, 2Gb 칩을 사용한 단면 메모리 모듈은 문제 없습니다.
수 십년전에 메모리 구매할 대 양면/단면 따져가면서 구매했었는데 이젠 어떤 용량의 칩이 쓰였는지도 확인해봐야 하네요. 이건 작년 말에 나온 이슈로, 아직 바이오스 업데이트가 안되었나봅니다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
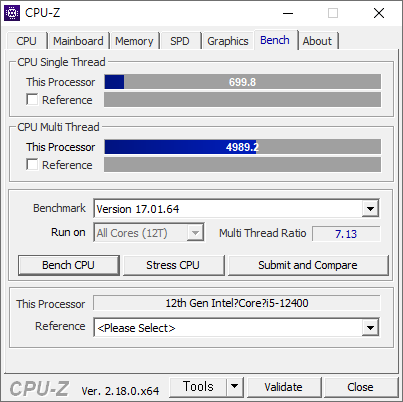
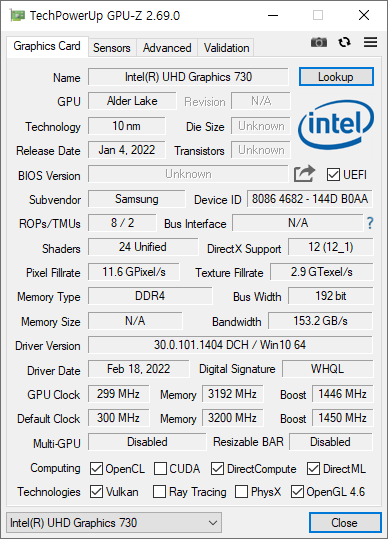
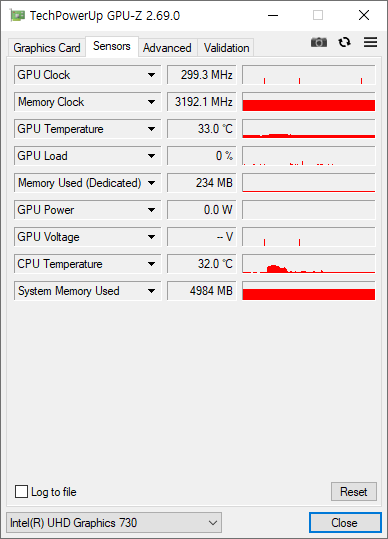
i5-12400 을 잠깐 써 봤다.
12 세대 인텔 코어 CPU 부터 E코어라고 불리는 절전형 코어가 들어 있는데, 12400 은 없다. P 코어만 6개 들어가 있다. 그래서인지 성능이 상당히 좋다.
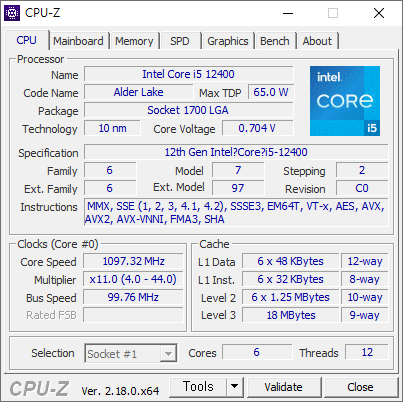
사용한 PC 는 싱글채널이라, 메모리 채널 개수가 1 x 64bit 으로 나온다. LLC/Ring 속도가 나오는게 특이했다. LLC(Load-Line Calibration) 라는 단어는 왜 넣었는지 모르겠지만 말이다. Ring 은 인텔 CPU 내부의 인터커넥트 속도다. 예전의 Uncore 속도를 말하는것 같아 보인다.
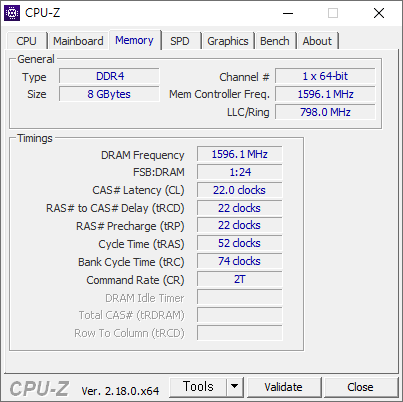
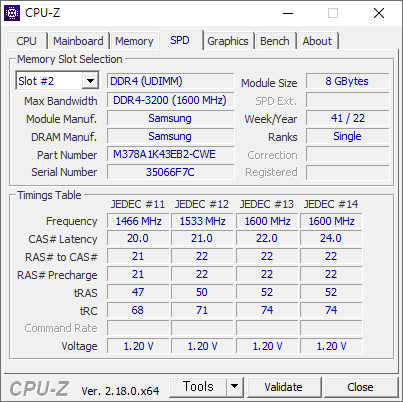
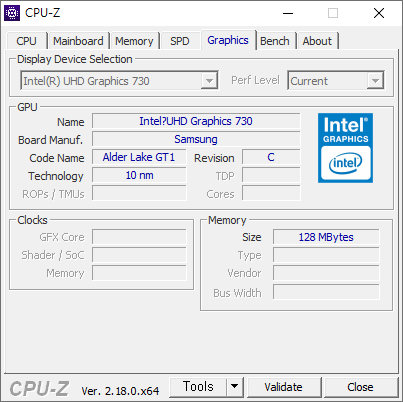
벤치는 꽤 잘 나왔다. P 코어만 있어서 그런지 싱글 쓰레드 속도가 잘 나왔다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
LPCAMM2 를 이야기 하기 전에 먼저 메모리 모듈에 대해 이야기 해야 한다.
초창기 컴퓨터는 메모리를 마더보드에 납땜해서 사용했다. 이후 DIP(Dual in-line package)를 사용하는 메모리가 활발하게 사용되었다.

DIP 패키지를 사용한 칩. 출처: 위키피디아
1990년대 후반 인텔에서 펜티엄 프로세서가 나올떄쯤에 DIP 스위치를 모방한 SIMM(Single In-line Memory Modules)이 나왔다.

SIMM. 출처: 위키피디아
이후 곧 SIMM 을 양면으로 사용하는 DIMM(Dual In-line Memory Module)이 나왔고, 2026년 현재까지 PC 에서는 계속 쓰이고 있다. DIMM 중에서, 노트북과 같은 작은 기기에 사용할 목적으로 만든게 SO-DIMM(Small Outline DIMM)일 뿐 근본적으로 변경된건 없었다.

DIMM. 출처: GEIL

SODIMM. 출처: GEIL
하지만 메모리 속도가 빨라짐에 따라 DIMM 으로는 문제가 생겼다. 메모리에서는 타이밍이 매우 중요한데, DIMM 은 길다란 형태를 가졌기 때문에 CPU 에서 각 메모리 모듈끼리 신호 타이밍 맞추기가 점점 힘들어졌다. 그렇다고 넉넉하게 신호를 여유있게 하자니 속도가 문제되었다. 그래서 DIMM 에 클록 생성기(Client Clock Driver, CKD)를 내장한 CU-DIMM 까지 나왔지만 근본적인 문제는 남아있었다.

CuDIMM 의 CKD 부품. 출처: GEIL. 사진 가운데 있는 부품이 CKD다.
그래서 나온게 CAMM 이다. 이런 형태의 메모리를 최초로 만든건 DELL 이다. 이를 메모리 표준기구인 JEDEC 에서 표준화한게 CAMM2 (Compression Attached Memory Module 2) 이다. 따라서 컨슈머용 CAMM 메모리는 CAMM2 부터 나온다. 그리고 노트북에는 LPCAMM2(Low Power CAMM2)형식이 들어가는데 CAMM2 나 LPCAMM2 나 기술적으로는 같다.

CAMM2. 출처: GEIL. 하단이 반대편을 찍은 것이다. LGA 의 접점이 닿을 곳이다.
CAMM 의 원리는 간단하다. 요즘나오는 CPU 를 마더보드에 끼우는 방식인 LGA 를 메모리에도 사용하는 것이다. CAMM2 메모리라고 사진찍어놓은걸 보면 윗면만 보이기 때문에 잘 안보이는데, 뒷면은 CPU 의 뒷면처럼 생겨있다. 그리고 메인보드의 CAMM 소켓은 LGA 핀이 달려있다. 마치 CPU 소켓처럼 말이다.

LPCAMM2. 출처: GEIL
하지만 아직까지는 DIMM 이 대세고 DDR5 메모리 모듈에는 CAMM2 제품도 있긴 하지만 잘 사용되지는 않는다. DDR6 부터 CAMM2 를 사용할 것이라고 한다.
CAMM2 부터 메모리 장착에는 십자 드라이버가 필요하다. DIMM 처럼 소켓 걸쇠를 이용한 방식이 아니다. CPU 처럼 소켓을 만들지 않은건 아쉽지만, 좁은 공간에 눞혀서 장착하려면 어쪌 수 없을것 같기도 하다.

메인보드에 장착된 CAMM2 모듈. 출처: MSI INSIDER
또한 CAMM2 부터는 보통 마더보드에 1개 정도 장착될 것으로 생각된다. CAMM2 의 크기가 DIMM 보다는 작긴 하지만, 눞혀서 장착하기 때문에 메인보드의 공간을 많이 차지한다. 아마 데스크탑 PC 에 장착하는건 1개로 생각된다. 물론 1개의 CAMM2 모듈로 듀얼채널을 지원하기 때문에 성능에는 상관 없지만 추후의 확장성에는 아쉬워지는 부분이다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
※ 윈도우 11을 트윅한 버전에 대한 글을 보고 그런게 있다길래 설치해보았다. 그 글에는 매우 빠르다는 것과 앞으로도 이걸 계속 사용해야겠다는 내용이었다.
호기심에 한번 설치해보았다. 설치한 사양은 아래와 같은 사양이다. 오래 사용할 생각이 아니라 여유부품들을 긁어 모았다.
CPU: Core2 Quad Q9550
MEM: DDR3 8G
HDD: SATA 320GB
GPU: GT1030
- 위 사양은 쉽게말해 GPU 빼고는 다 15년도 넘은 사양이다. 4K 해상도는 지원해야 해서 GT1030 을 끼워주었다.
※ 우선 윈도11 23H2 기반으로 트윅한걸 설치했다. 설치한 PC 의 CPU는 SSE 4.2 를 지원하지 않기 때문이다.
※ 설치는 쉽게 되었다. 윈도 11을 설치해본 사람이면 쉽게 할 수 있을듯 하다.
※ 설치해본 소감을 말하자면
1. 일단 빠르다. 정말 빠르다. 군더더기가 없다는게 이렇게 빠를줄은 몰랐다. 절로 감탄이 나왔다.
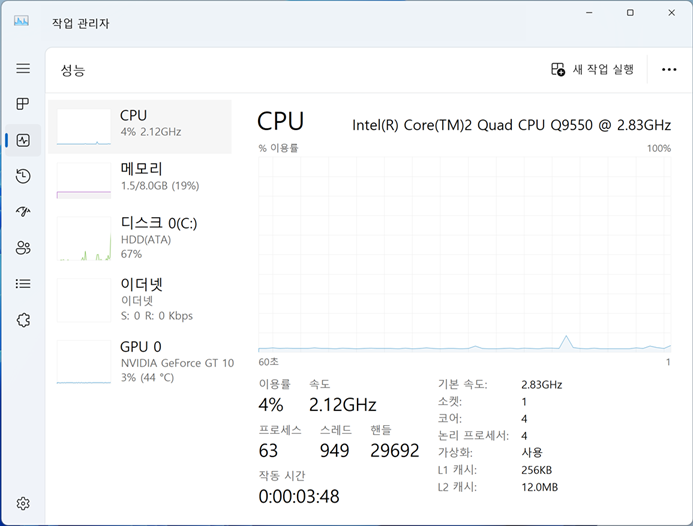
2. 작업관리자를 보면, 실행되어 있는 프로세스가 적다. 필자의 경우 드라이버를 모두 설치한 후에 아래와 같이 63개의 프로세스가 실행되어 있고, 메모리는 1.5GB 정도 사용하고 있다. 반드시 실행할 필요 없는 프로세스를 과감히 실행하지 않도록 설정한게 트윅버전이다.
3. Edge 가 없다. 따라서 설치하자마자 인터넷 브라우저부터 설치해야 한다. 필요하다면 엣지를 설치하는것도 나쁘지 않다. 필자는 불여우 설치해서 사용했다.
4. 기본 프로그램이 별로 없다. 가장 불편했던게 그림판(mspaint) 이 없다. 쉽게 말해 윈도 앱스토에 있는 앱들은 설치되지 않는것 같다. 사용하다 보면 어딘가 모르게 불편한게 나올것 같다.
15년전 사양의 하드웨어임에도 불구하고 정말 쾌적하게 사용할 수 있었다. Q9550 에서 이정도 성능이면, 최신 CPU 를 사용하는 PC라면 정말 날아다닐것 같은 느낌.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/하드웨어 정보
SilverStone SST-FLP02W
재미있는 케이스가 나와서 올려본다. 실버스톤의 FLP02 라는 모델이다.

레트로감성 풍만한 케이스다. 요즘엔 플로피나 ODD 를 달 수 있는 5.25 인치 확장 슬롯이 있는 모델이 나오지 않지만, 불과 10여년전만 해도 흔했다. 게다가 20여년전에 볼 수 있었던 잠금장치를 2026년에 볼 수 있을거라고는 생각 못했다. 터보키도 구현해 놓았다. 전원 버튼도 요즘 나오는건 버튼식이라 저런식으로 구현하기 힘들었을 것 같다. 실제로 작동되는 건 20여년전의것과는 다르다. 잠금키는 리셋버튼의 잠금키고, 터보키는 PWM 조절장치라고 한다.

재미삼아 구매하기엔 너무 비싸다. 30만원 정도. 그래도 이런 케이스가 나오니 반갑긴 하다.
같은회사에서 아래와 같이 HTPC 모델인 FLP01 이 나왔다. 이것도 만만치 않는 가격이다.

- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음