윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
4 개 검색됨 : 2024/06/22 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
일부러 파란색, 초록드레스로 골라봤다.역대급으로 잘 나온 첫번째 사진이 가장 맘에 든다. 왠지 분위기도 있고 말이다.




- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
드레스중에 가장 좋아하는게 빅토리아 시대의 드레스다. 물론 고증이 잘된걸 좋아하는건 아니고 약간 현대식으로 개량된걸 좋아한다. 마침 괜찮아 보이는 LoRA 가 올라와서 작성해 보았다.
최근에 사용하고 있는 체크포인트는 왠지 흰색-금색이 잘 나온다. 프롬프트 바꾸면 되긴 하지만, blonde 프롬프트를 포기하고 싶진 않아 그냥 금색으로 생성했다. (SD1.5 에서는 색상 변경이 잘 안된다)




- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
Stable Diffusion 3 Medium
Stable Diffusion 3 Medium 이 오픈소스로 릴리즈 되었습니다. ComfyUI 에서는 지원되고 아직 WebUI 에서는 지원안되지만 조만간 지원될걸로 생각합니다. ComfyUI 는 제작사인 Stability AI 에서 직접 지원해줬네요.
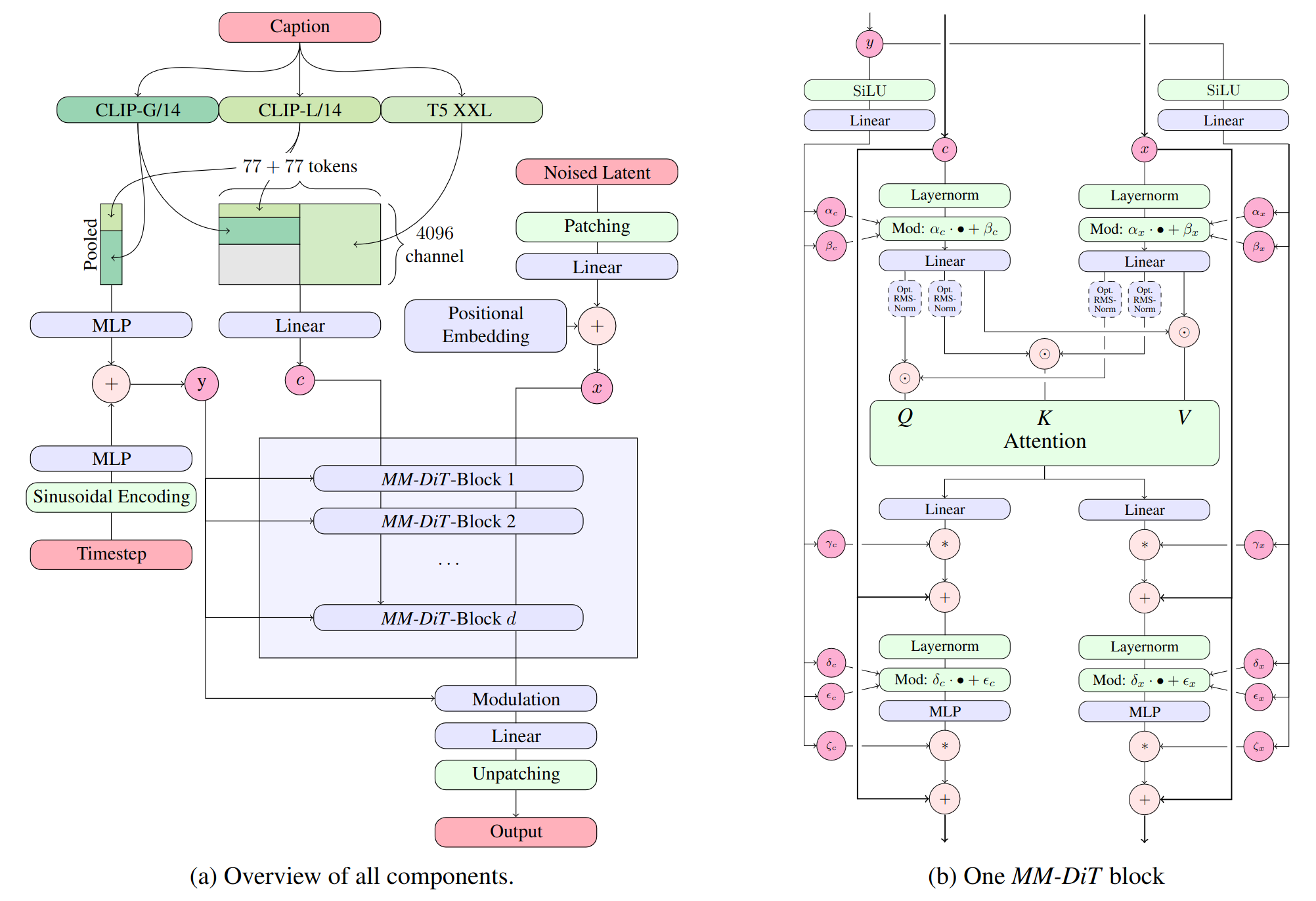
CLIP이 3가지(CLIP-G, CLIP-L, T5 XXL)이고, U-NET 구조를 가지지 않습니다. MMDiT (Multimodal Diffusion Transformer) 모델이라고 설명하네요. 파라메터는 20억개로 SDXL 의 26억개보다는 적지만, 굉장히 많은 개선점이 있습니다. 가장 눈에 띄의는건 텍스트를 제대로 인식해 출력해준다는 거네요. nVidia 와의 협업으로 TensorRT 를 사용한 성능 향상도 눈에 띄입니다.
실행시킬때 필요한 PC사양, 성능은 SDXL 과 크게 다르지 않을것 같네요. FP8 으로 줄인 모델을 사용하면 더 빠르게 사용할 수 있을 걸로 생각합니다.

WebUI 에서 포팅 중이긴 한데 아직 좀 더 기다려야 합니다. 대충 보니깐 현재 구현된건 ComfyUI 보다 많이 느리다고 하네요. Karras 스케줄러와도 안 맞는다고 합니다.
단 라이선스 때문에 말이 많네요. "크리에이터 라이선스"나 "상업 라이선스"는 유료인가 봅니다. 그리고 "비상업적 라이선스" 부분도 좀 애매한 부분이 있어, CiviAI 에서 이 부분에 대한 명확한 해명을 요구하고 있네요. 현재 라이선스대로라면 CivitAI 처럼 서비스 하는건 불가능하나 보네요.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
해 지는 저녁 노을을 배경으로 한 여인의 실루엣 사진을 한번 만들어보고 싶었다. 이런 구도는 괘 흔한 거긴 하지만, 이런걸 만들려면 색상의 대비를 표현해줄 LoRA 가 필요한데, 마침 하나 올라왔다.




- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음