윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
16 개 검색됨 : 2023/07 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
출시되었습니다.
- 공식 체크포인트 파일은 아래에서 받을 수 있습니다.
BASE: sd_xl_base_1.0.safetensors
REFINER: sd_xl_refiner_1.0.safetensors
VAE: sdxl_vae.safetensors
문제는 위의 공식 버전은 FP16 을 사용할 경우 VAE 적용에서 문제생긴다네요. 그래서 VAE 를 다르게 적용해 합본한 파일을 받아 사용해야 합니다. 결과적으로 아래의 통합 파일을 받아서 사용해야 합니다.
- StabilityAI 에서 VAE를 통합한 파일을 다시 배포했습니다. 아래에서 받을 수 있습니다. WebUI 에서는 아래걸 받아 VAE 없이 사용하면 됩니다.
BASE + VAE: sd_xl_base_1.0_0.9vae.safetensors
REFINER + VAE: sd_xl_refiner_1.0_0.9vae.safetensors
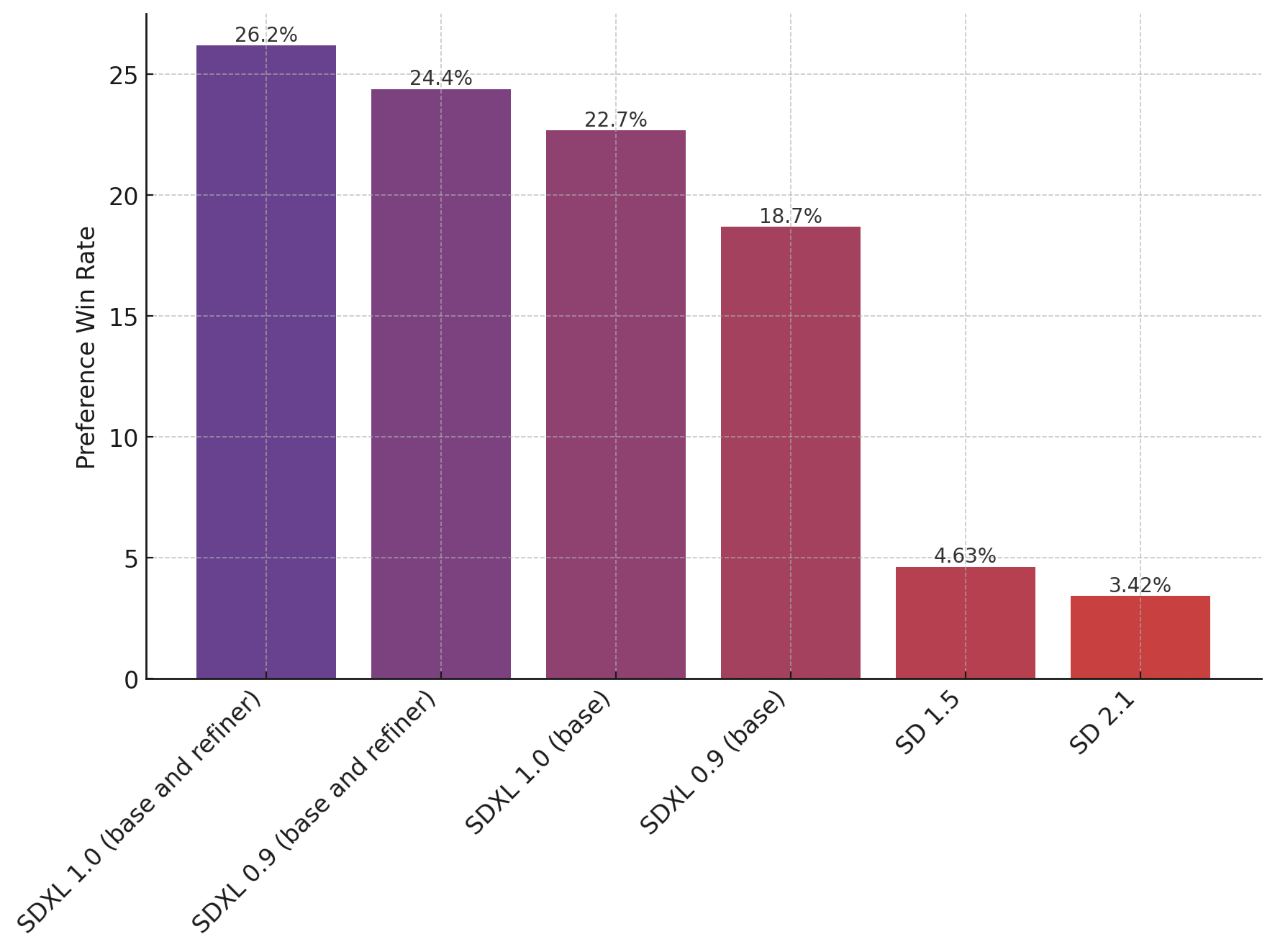
보름쯤 전에 배포된 0.9 버전보다 더 좋아졌다고 하네요. (그래프 값의 합은 100% 입니다)
사용해보니 메모리. VRAM 과 시스템 메모리 사용양이 많습니다. VRAM 12GB, 시스템 메모리 32GB 도 버겁다는 말이 있네요.
현재 사용하고 있는 제 시스템 사양이 VRAM 12GB, 시스템 메모리 12GB 인데, 체크포인트 로딩하는데 1470초 걸렸습니다. HDD 라 더 걸리는것 같지만 근본적으로 메모리가 부족합니다. 시스템 메모리 64GB 만들어야 할거 같네요.
로딩 이후에는 시스템 메모리 4.5GB, VRAM 8.3 GB 사용하고 있습니다. 이미지 생성시에는 12GB, 12GB 다 차네요. 역시 메모리가 부족합니다. SDXL 생성에 걸린시간은 40초 정도로 SD 1.5 의 20초보다 2배 정도 더 걸립니다.
아래는 SDXL 으로 생성한 그림입니다. 기본이 이정도 퀄리티라면 역시 SDXL으로 바꾸긴 해야겠네요. SD 1.5 오리지널보다 훨씬 많이 디테일이 좋고 프롬프트가 이미지에 잘 반영됩니다. CivitAI 찾아보니 이미 DreamShaper 라는 체크포인트는 SDXL 용으로 Alpha 버전이 올라와 있네요. SD 2 나올때보다 더 폭발적인 반응입니다. 앞으로 SD1.5 에서 SDXL 으로 많이 바꿀거라 생각합니다.


- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
어제 stable-diffusion-webui 의 1.5 버전이 배포되었다. 주된 변경점은 SDXL 지원이다. 예전글에 쓴적이 있는데 몇가지 특징을 적어줘서 블로그에 옮긴다.
출처: https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/11757
1. 가장 큰 변경점이 사전의 크기가 대폭 늘어났다는 거다.
SD1: Tensor(2x77x768)
SDXL: {'crossattn': Tensor(2x77x2048), 'vector': Tensor(2x2048)}
이라고 한다. (파라메터 늘어났다는 의미이고 이걸 텐서로 표현하면 위와 같이 된다는 거 같다)
2. SDXL 을 돌릴때 1024 x 1024 이미지 생성시 VRAM 을 약 12GB 정도 소비했다고 한다. --medvram 옵션을 주었을때 그렇다는거다.
하지만 8GB 만 사용하도록 제한을 두어도 이미지가 생성된다고 한다. 즉 8GB 정도면 실행가능하다는 의미다.
(개발자는 nVidia RTX 3090 24GB 를 사용하는 것으로 알려져 있다)
3. textual inversion 은 작동하지 않는다. (SDXL 용으로 개발해야 할듯)
4. LoRA 도 SDXL 으로 개발된거 빼고는 작동 안한다.
5. 난수 생성기를 CPU 로 설정하고 Stability-AI 에 올라와있는 프롬프트대로 생성시 거의 같게 생성된다고 한다.
6. 여러가지 Attention 최적화 기법이 작동한다고 한다. (xFormers 적용 된다는 의미인듯 하다)
7. --no-half-vae 옵션이 반드시 필요하다고 한다.
8. DDIM, PLMS, UniPC 샘플러가 작동하지 않는다고 한다. (SDXL 용으로 개발해야 할듯)
9. 현재 webUI 에서는 refiner 지원하지 않는다.
----
SDXL 소개: Stable Diffusion - SDXL
SDXL 후기: Stable Diffusion XL 1.0 출시
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
"[LoHa] Vines あおふじ青藤 Style (With multires noise version)" 이라는 LoRA 가 올라왔길래 사용해보았다. 맘에 들어 게시한다. 윈도 배경 이미지로 쓰고 있다.
참고로
Vines, あおふじ, 青藤(청도)은 "넝굴식물" 의 의미. 다 같은 말이다.이 LoRA 가지고 넝굴식물과 같은 이미지를 만들 수 있다. 여기에 은하수를 더한 이미지가 이 글에 게시한 이미지다.







- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
"cartoon_portrait_v2" 라는 LoRA 를 사용해서 생성한 그림.
샘플 이미지에 나온 그림들을 보고 생성한그림들이 맘에 들어서 더 작성해 보았다.


아래 이미지들은 내가 즐겨쓰는 프롬프트를 사용해 만든것.
재미있는건 텍스트로 업스케일링이 안되어서, 이미지에서 업스케일링 했다. 그것도 0.1 강도로 말이다. 그외의 방법으로는 뭔가 검은 그림으로 생성되어서 (즉 오류발생해서) 사용할 수 없었다. LoRA 는 잘 적용되었는데 말이다. 아니면 LoRA 가 SD 1.5 체크포인트를 가지고 만들어서 그런걸지도 모르겠다. (확인 안해봤다)








- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전












- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
2023.07.18 (현지시각) 공개할 차세대 Stability Diffusion이다. v3 는 아니지만, 그래도 꽤 많은 변화가 있다.
- 가장 큰 변화는 기준이 되는 학습한 이미지의 크기가 변경된 거다.
SD 1.x 에서는 512x512 이미지로학습
SD 2.x 768 에서는 768 x 768 이미지로 학습
SDXL 에서는 1024 x 1024 이미지로 학습
그래서 SDXL 에서는 1024 미만의 해상도를 가진 이미지를 생성하는 경우 크롭될 수 있다.
- SDXL 은 refine (SDXL 용 업스케일링 체크포인트)도 있다는것 같다.
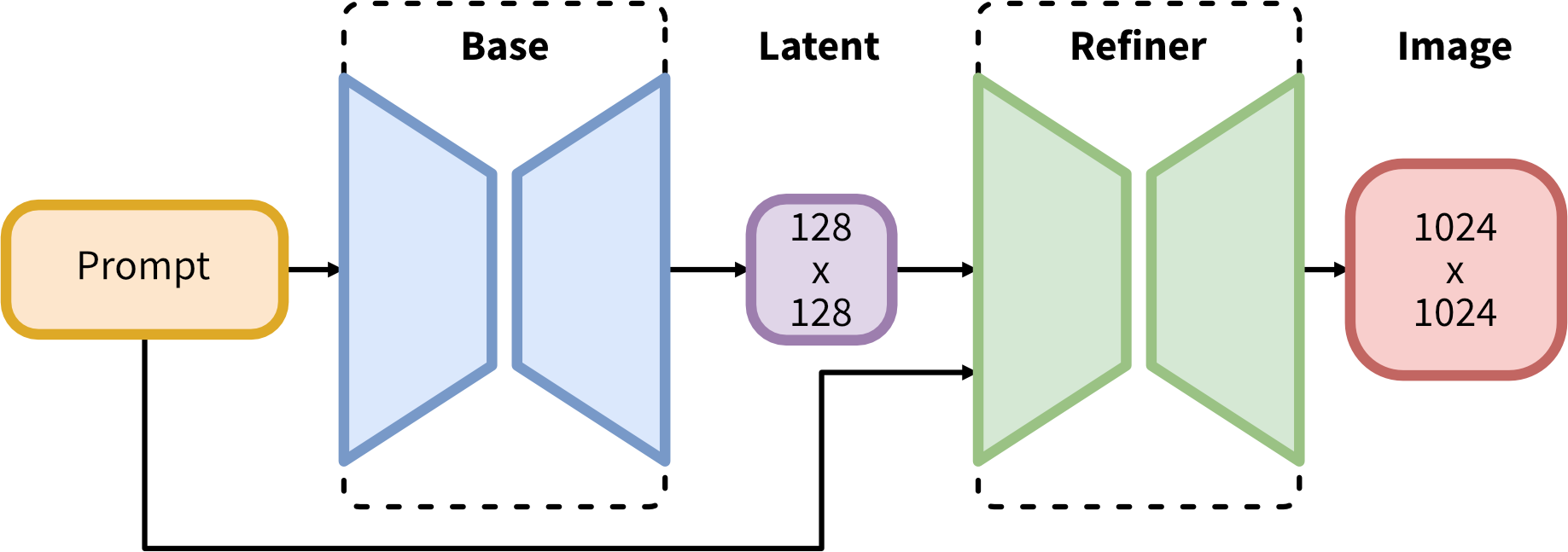
SDXL 파이프라인
- AI 이미지에서 손을 못 그리는 이유 중 하나가 학습된 이미지의 해상도 때문이다. 전신 사진을 512x512 로 저장하다 보면 손과 같이 디테일이 필요한 부분은 뭉개지게 되고, 이를 학습하면 뭉개진 채로 학습되기 때문에, 이게 결과적으로 뭉개진 그림을 생성하게 된다. 물론 SD 초창기에는 손 뿐만 아니라 얼굴과 눈도 문제가 되긴 했지만, 이건 학습을 많이 해서 해결했다. 손은 학습을 많이 하는걸로도 해결이 안되었던 셈이다. 768 x 768 이미지로 학습시킨 SD 2.x 768 에서는 확실히 손의 디테일이 살아있긴 하지만 그래도 부족했고, 무었보다 SD 2.x 는 텍스트 인코더가 좋지 않아 이전 버전에 비해 원하는 이미지 만들기가 더 힘들었다. SDXL 은 손 문제가 어느정도 해결될 것으로 생각한다. 그렇다면 SDXL 으로 빠르게 전환될지도 모르겠다. 다른건 몰라도 SD 에서 손을 못 그리는 문제는 반드시 해결해야 한다. 시간이 걸리더라도 말이다.
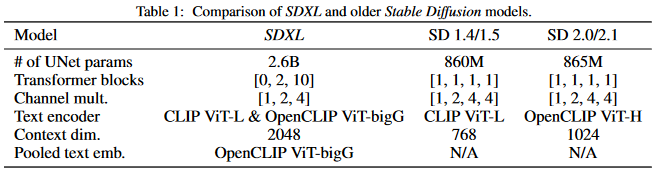
SD 버전 비교
- 또한 SDXL 은 UNet 파라메터가 860M 에서 2.6B 으로 3배 정도 늘어났다. 한글로 표현하자면 8억개에서 26억개로 늘어났다. 어쨌든 파라메터 개수가 늘어나면 좀 더 퀄리티 높은 결과가 나오지 않을까 기대중이다.
- 고해상도 이미지를 학습시키고 고해상도 이미지를 생성해야 하며, 학습 파라메터도 늘어났기 때문에 VRAM 과 시스템 메모리를 많이 필요로 한다. 특히 시스템 메모리 16GB 가 필요하다고 한다. 그렇다면 32GB 는 준비해야 여유있을거라는 의미다. 그래픽카드도 nVidia RTX 이 필요하고 VRAM 은 8GB 이상이 필요하다고 한다. 최소 RTX 2060 12GB 는 필요한 셈이다. RTX 20 시리즈가 2018년 9월에 나온걸 감안하면 꽤 오래전 GPU 까지 지원해주는 듯. 에혀... 올해 4월에 RTX 2060사고 좋아라 했는데 다시 업그레이드해야겠다.
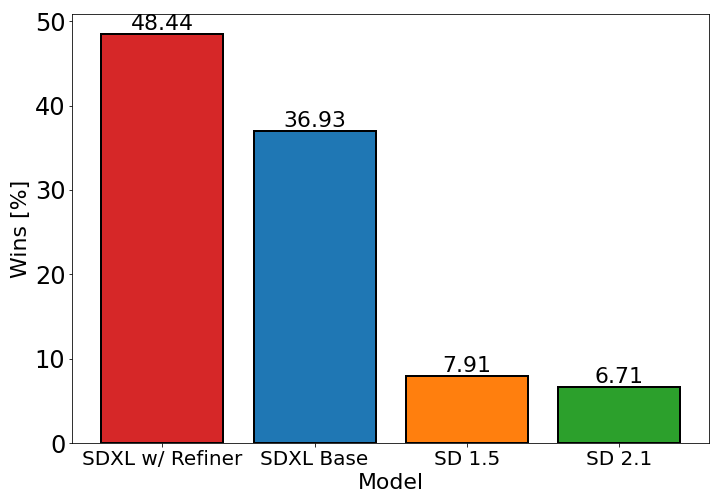
SD1.5 에서 맘에 드는 이미지를 생성할 확률이 7.91% 라면, SDXL Refiner 사용시에는 48.44% 라는 의미다.
2023.07.19 추가
공개가 연기되었다고 한다. 일주일 정도. 에혀. 느긋하게 기다려보자.
https://decrypt.co/149016/hold-your-horses-stability-ai-delays-stable-diffusion-xl-v1-release
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전








- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전









- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전





- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전











- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음