윈디하나의 블로그
윈디하나의 누리사랑방. 이런 저런 얘기
2460 개 검색됨 : 윈디하나 에 대한 결과
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
갑자기 생성해보고 싶어서 만든 메이드. 짧은 의상편.








- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음


- 글쓴시간
- 분류 기술,IT/하드웨어 정보
3RSYS L300 코드 (화이트)

3RSYS 의 미니타워 케이스다. 가격은 4.15 만냥. M-ATX 마더보드까지 사용할 수 있다. 아이의 방에 놓아둘 PC를 조립할 생각으로 구매했다. 팬이 QUITE 팬이 아닌게 조금 아쉽지만, 그래도 조용하다. 어차피 아이가 고사양의 게임을 할 건 아니니 발열은 크게 신경 안써도 된다. 그래도 나름 만듬새가 있어서 조립하기엔 좋았다.
전면은 먼지필터와 메쉬로 되어있는데, 이게 하얀색 조명과 더불어 감성적이다. 뭔가 인테리어틱한 디자인이기도 하고 말이다.

이 케이스가 나오고 몇개월 후에 "3RSYS R10 아트오브제"가 나왔다. 전면 디자인과 받힘대 디자인이 다른데, 아트오브제가 전면 팬이 1개라 이부분이 아쉬웠는데 이건 2팬이라 나름 좋긴 하다. 그래도 L300 에 QUITE 팬 달아줬으면 더 좋지 않았을까 하는 아쉬움도 가지고 있다.
----
3RSYS R10 아트오브제 (화이트)
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
한국의 미녀를 만드려고 했지만, 잘 안되었다. 금발을 포기해야 하는데 그게 잘 안되는 셈. 그래도 맘에 드는 그림이 생성되어 좋았다.
요즘에 많이 생성하는 이미지가 애스콧(ascot)을 착용한 미녀의 이미지다. 애스콧은 여성 정장 넥타이 정도 되는데 근대에는 별로 유행하고 있지 않다. 스카프와 유사하지만 매듭이 있다. 미녀 #7 에 있는 넥타이가 모두 애스콧이다.


- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
윈도에서 노트북 배터리 레벨 보기
Libre Hardware Monitor 라는 프로그램에서 볼 수 있다. 아마 다른 프로그램도 사용할 수 있을 거 같다.
사용하면 할 수록 저하 수준(Degradation Level)이 늘어나는게 보인다. 늘어나는게 점점 가속되는 느낌. 회사에서 4년째 사용하고 있는 노트북이니 줄어들만도 하다.
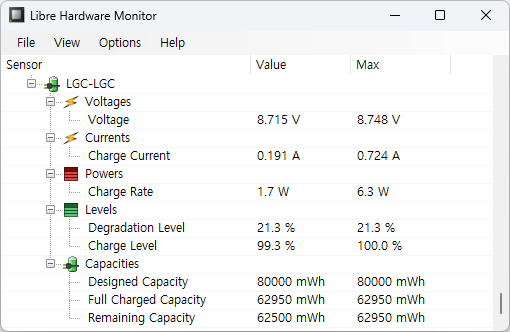
재미있는건 이 값들이 완전충전시에는 변한다는 거다. 위 화면은 99.3% 충전시고, 100% 충전하면 아래와 같이 저하 수준이 19.9% 으로 변한다.
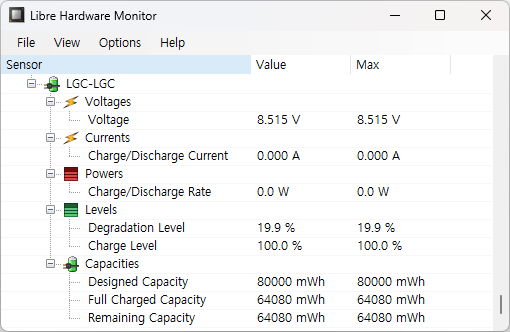
어찌되었던 19.9% 이하로는 안 떨어질듯. 바꿔말하면 20% 가까이 떨어진건데, 이정도면 배터리 교체해야하긴 하다. 물론 노트북 교체할꺼지만 말이다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
수영복 사진은 잘 안올리려고 했는데, 마침 좋은 LoRA 가 보여서 한번 생성해보았다. 이런 그림에는 슈트로 해야 하기 때문.










- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
오버클럭시에는 필수라는 소프트웨어라고는 하지만, 4750G CPU 는 PBO 가 지원 안되기 때문에 그동안 사용 안했다. Ryzen CPU 를 모니터링하고 제어할 수 있는 제조사 공식 툴이다.
그래도 한번 설치해보았다. 실행시 나오는 경고문구는 그다지 신경 안 써도 된다.
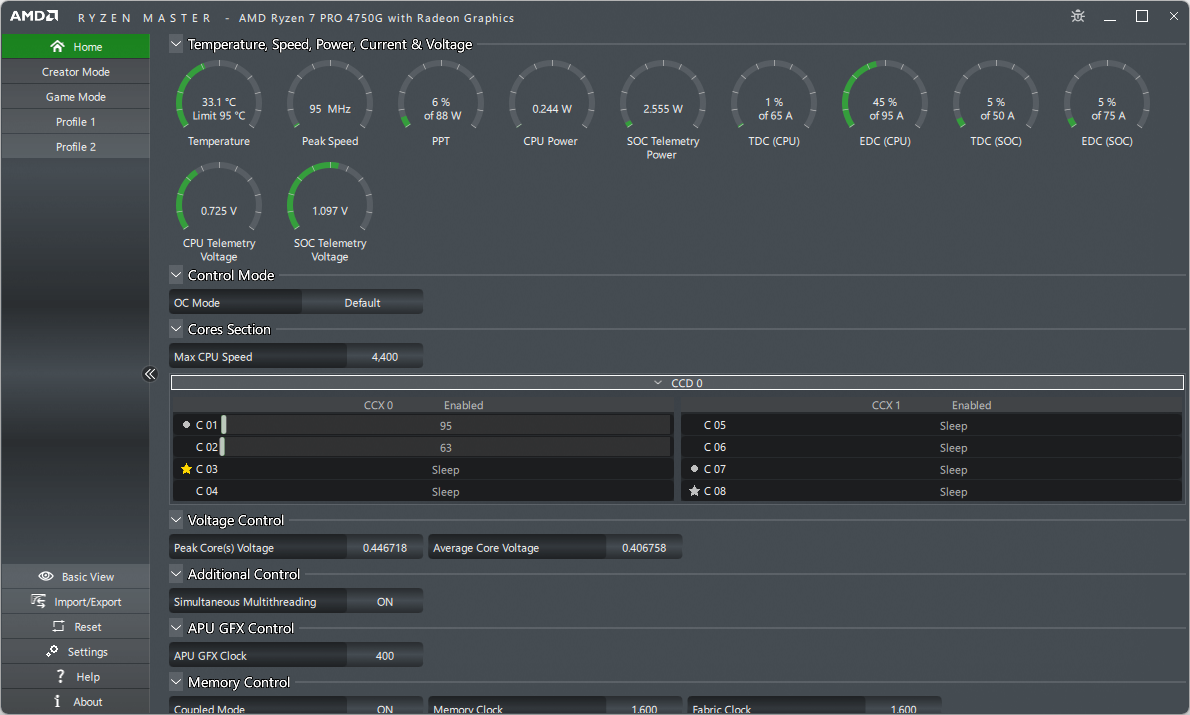
다른건 HWiNFO 나 CPU-Z 에서 보여주기 때문에 크게 중요지 않지만, 라이젠 마스터에는 CPU 선호도 나오는게 있다. CCD 및 CCX 화면에서 ★ 별표와 ● 동그라미로 나온다. 이중 ★노란색 별표가 가장 성능이 좋은 코어라는 의미다.
언젠가 PBO 지원되는 X 계열 CPU 사고 꼭 해봐야지.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
이게 될꺼라고는 생각 못했는데, 우연히 기능을 살펴보다가 알게 되었다.
ASUS 마더보드에 UEFI 바이오스가 들어있는 경우,
1. USB 드라이브를 연결하고
2. F12 를 누르고 USB 드라이브를 선택하면 .bmp 파일로 저장된다.
- 아래와 같이 저장되었다. 해상도는 1024 x 768 이다.
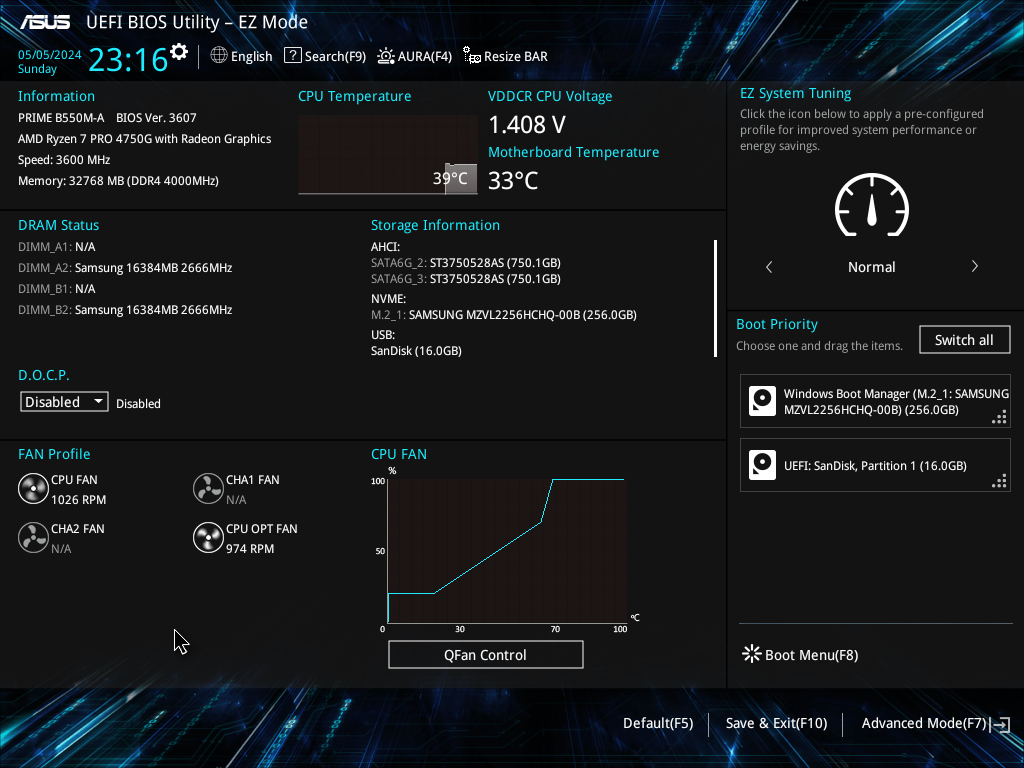
- 도움말을 보니 아래와 같은 키도 되나보다.
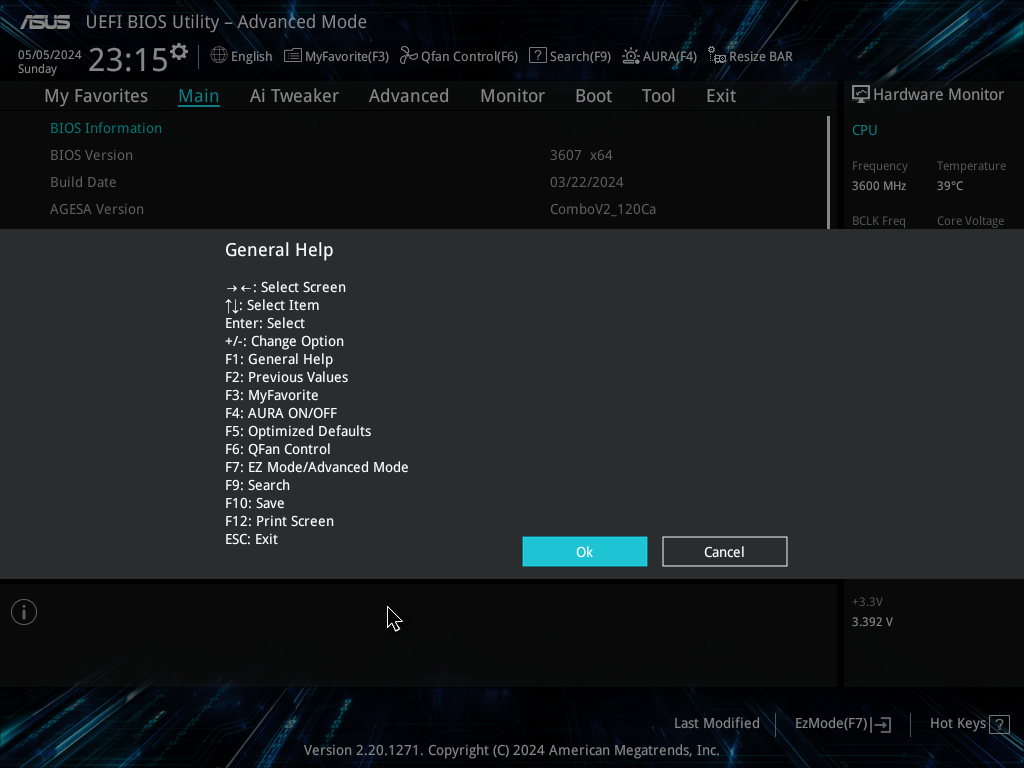
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
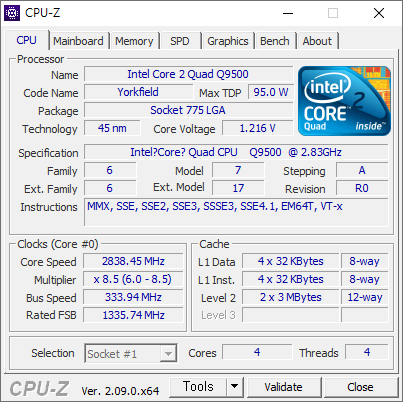
Core 2 의 오버클러킹(오버)는 원래 잘 안하는데, (예전에 시도했었지만 실패하기도 했고) Q9500 이 잘된다는 글을 보고 한번 시도해 보았다. 10여년도 더 된 CPU 를 이제와서 오버하는건 의미 없을수도 있겠지만, 결과적으로는 잘 되어서 글을 써본다.
Core 2 의 오버는 주로 FSB 클럭수를 오버한다. 다른건 오버가 안되기 때문이다. Core2 이전에는 배수를 조절해서 오버했지만, Core2 는 배수락이 걸려있기 때문에 배수를 조정할 수 없다. 따라서 다른 방법을 사용한다.
※ 우선 Q9500 의 클럭은 아래와 같이 계산된다.
- 버스클럭: 333 MHz
- FSB클럭: 1333 MHz (버스클럭 x 4)
- 코어클럭: 2.83 GHz (버스클럭 x 8.5)
-> FSB 클럭은 버스클럭의 4배수(모든 코어2 시리즈 CPU가 4배수이다)이고, Q9500의 코어 클럭은 버스클럭의 8.5 배수로 정해져 있다. 따라서 버스클럭을 올리면 자연적으로 FSB 클럭과 코어클럭이 올라간다.
-> 여기서 문제되는건 FSB 클럭이다. 버스 클럭을 올리면 코어클럭만 오르는게 아니라 FSB 클럭도 같이 오른다는게 문제다. 공식적으로 Core2 시리즈는 FSB 1600MHz 까지 나와있으며, 따라서 마더보드에서 FSB 1600MHz 까지는 지원되는 경우가 많다. 이 이상하려면 마더보드의 매뉴얼을 찾아 봐야 한다. 즉 버스클럭을 333 MHz -> 400 MHz 까지 오버클럭하는건 어느정도 허용의 범위지만, 그 이상은 마더보드 스펙을 따져보면서 해야 한다.
-> 또한 FSB 클럭이 오르면 자연적으로 메모리 클럭이 오른다. (정확하게는 FSB 클럭마다 사용할 수 있는 메모리 클럭이 정해져 있으며 FSB 클럭을 올리면 높은 메모리 클럭이 필요하다) PC2-3200 메모리를 사용하면 FSB 클럭이 1600MHz 으로 작동할 때 FSB:DRAM 클럭을 1:1 으로 맞춰줄 수 있다.
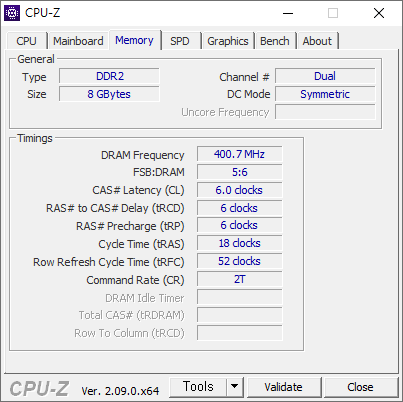
※ 사용한 메모리는 DDR2-800 메모리다. 2G 씩 4개 풀 뱅크로 사용중이다. 이 상태에서 오버클러킹을 시도했다.
- 순정 스펙인 FSB-1333 - DDR2-800 은 아래와 같다. 252.3 점 - 999.2 점 이다.
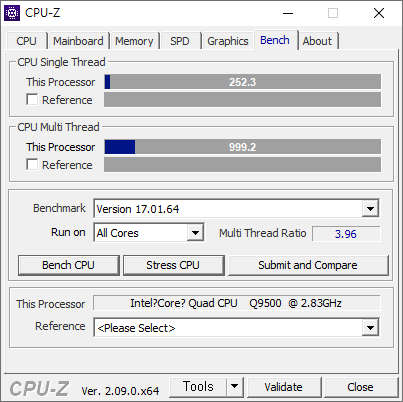
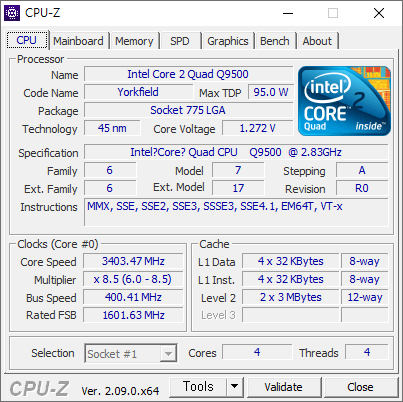
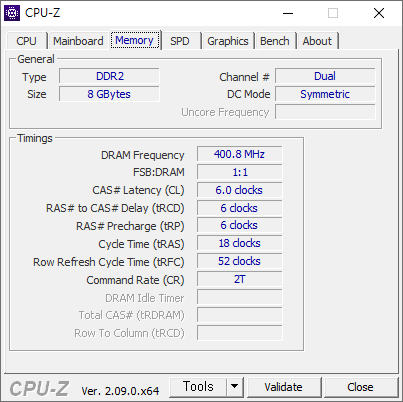
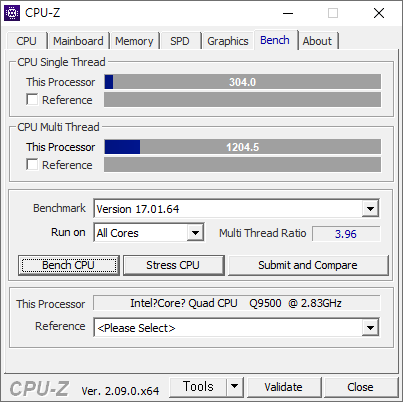
- BUS 를 400으로 올렸다. FSB-1600 - DDR2-800 은 아래와 같다. 304.0 점 - 1204.5 점 이다. FSB:DRAM 이 1:1 인게 맘에 든다.
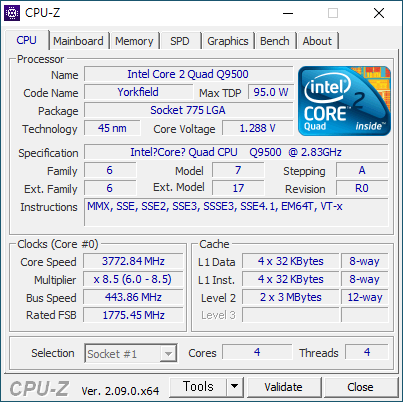
- BUS 를 444으로 올렸다. FSB-1776 - DDR2-888 은 아래와 같다. 335.3 점 - 1328.6 점 이다.
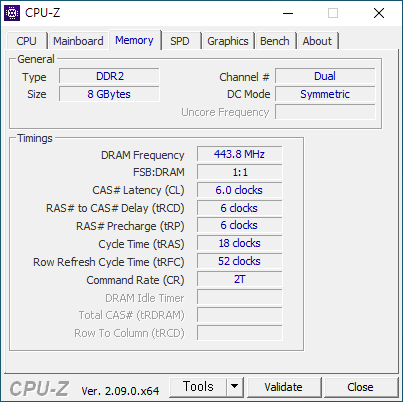
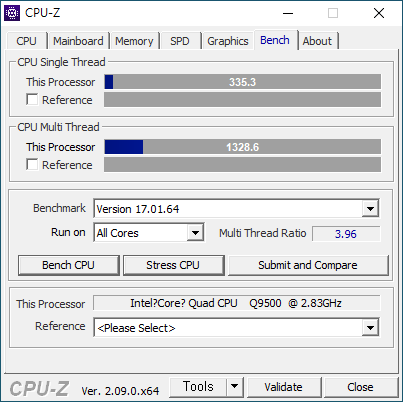
- 메모리를 DDR2-1066 으로 올렸다. FSB-1776 - DDR2-1066 은 아래와 같다. 337.8 - 1335.2 점이다.
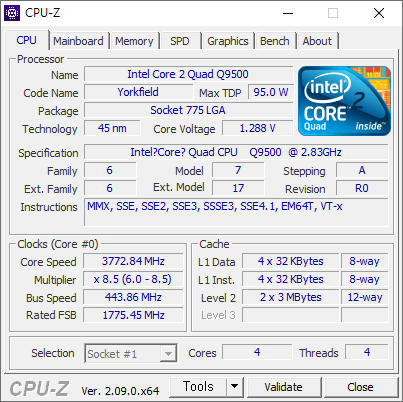
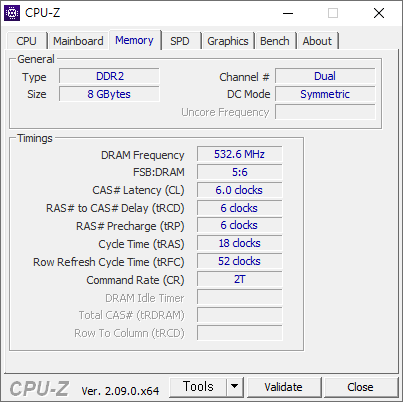
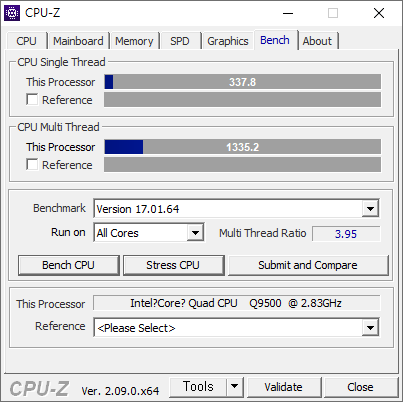
- BUS 를 470으로 올렸다. 이렇게 하면 최대 Core Speed 가 4.0 GHz 가 나온다. 부팅은 되었지만 CPU-Z 벤치에는 실패했다. 안하기로 했다.
- 메모리도 DDR2-1333 까지 올려봤지만 바이오스 진입에 실패했다.
- 현재는 FSB-1600 - DDR2-800 사양으로 사용하고 있다.
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT
결과적으로는 안정성을 위해 전력제한 해제하지 말고, 전압 오버하지 않도록 오버클럭하지 말고 쓰라는 것입니다. 그래서 사용자들이 전력제한을 해제하지 않고 써보니, 그렇다면 12세대와 성능차이가 없다고 하네요. 그럼 뭐하러 비싼돈주고 13, 14세대 CPU 쓰냐는 거죠. 화가 단단히 났습니다. 게다가 인터넷 뒤져보니 최근에는 일부러 오버하지 않았는데도 CPU 가 고장난 경우가 있다고 하네요. CPU 의 터보 기능만 적극 사용해도 이슈가 있는거 같아 보이네요.

전문은 아래와 같습니다.
13th and 14th Generation K SKU Processor Instability Issue Update
Intel® has observed that this issue may be related to out of specification operating conditions resulting in sustained high voltage and frequency during periods of elevated heat.
Analysis of affected processors shows some parts experience shifts in minimum operating voltages which may be related to operation outside of Intel® specified operating conditions.
ㆍ While the root cause has not yet been identified, Intel® has observed the majority of reports of this issue are from users with unlocked/overclock capable motherboards.
ㆍ Intel® has observed 600/700 Series chipset boards often set BIOS defaults to disable thermal and power delivery safeguards designed to limit processor exposure to sustained periods of high voltage and frequency, for example:
– Disabling Current Excursion Protection (CEP)
– Enabling the IccMax Unlimited bit
– Disabling Thermal Velocity Boost (TVB) and/or Enhanced Thermal Velocity Boost (eTVB)
– Additional settings which may increase the risk of system instability:
– Disabling C-states
– Using Windows Ultimate Performance mode
– Increasing PL1 and PL2 beyond Intel® recommended limits
Intel® requests system and motherboard manufacturers to provide end users with a default BIOS profile that matches Intel® recommended settings.
ㆍ Intel® strongly recommends customer’s default BIOS settings should ensure operation within Intel’s recommended settings.
ㆍ In addition, Intel® strongly recommends motherboard manufacturers to implement warnings for end users alerting them to any unlocked or overclocking feature usage.
Intel® is continuing to actively investigate this issue to determine the root cause and will provide additional updates as relevant information becomes available.
Intel® will be publishing a public statement regarding issue status and Intel® recommended BIOS setting recommendations targeted for May 2024.
- 올초에 나온 이야기 중에 인텔CPU 에서 AVX2 명령셋 및 PCIe 레인을 동시에 과도하게 오랫동안 사용하는 경우 오류가 발생하는 경우가 있다고 합니다. 이런 경운 CPU 가 고장나 있는거라 A/S 받으러 가야했죠. 특히 철권8 이라는 게임에서 쉽게 발견되었다고 합니다.
- 원래 CPU에서 AVX 명령을 수행하면 전력을 많이 소비하고 그만큼 발열이 심했습니다. AVX2 명령을 사용하면 더 심해지고, AVX512 명령은 더 심해지죠. 현재 AVX 명령을 사용하는 게임이 많기 때문에 이 이슈가 지금 나오게 된거 같습니다. 그 정점에 철권8 이 있게 된 셈입니다.

- 10년전까지만 해도 인텔 CPU는 AMD CPU에 비해 빠르고 안정적이었습니다. 고장도 없었고 소비전력도 낮고 안정적으로 작동했기 때문에 믿고 쓸 수 있었죠. 특히 서버 제품군에는 인텔 외에는 생각도 하지 않았습니다. 하지만 어느샌가 CPU 에 고장이 많아지고 있었고 인텔도 예외는 아니었습니다. AMD는 원래 드물게 고장이 있었고 그냥 그러려니 했었는데, 결국 저도 고장난 G4560 (카비레이크) 를 하나 가지게 되었습니다. CPU가 원래 고장이 잘 나지 않기 때문에 중고거래가 활발한 편인데, 이번엔 그렇지 않나 보네요. 전 다행이 그런 비싼 인텔 CPU는 못쓰고, 저렴한 AMD CPU나 쓰고 있습니다. AMD CPU 가 더 안정적이라는건 정말 오랜만에 느껴보네요.

----
https://www.igorslab.de/en/intel-releases-the-13th-and-14th-generation-k-sku-processor-instability-issue-update/
- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음
- 글쓴시간
- 분류 기술,IT/스테이블 디퓨전
정복이란 "의식을 행할때 입는 예복"을 말한다. 여성용 정복이라함은 블레이저, 스커트, 블라우스, 스타킹, 펌프스 정도로 되어있지만 조금 다르게 생성해 보았다.



- 응답
- RSS / ATOM 피드를 통해 답글을 트랙할 수 있음